Spark2.1.0编译
1.下载spark源码包
http://spark.apache.org/downloads.html

2.安装Scala与maven,解压spark源码包
安装Scala:
tar zxf scala-2.11.8.tar
修改vim /etc/profile
export SCALA_HOME=/usr/scala/scala-2.11.8
export PATH=$PATH:$SCALA_HOME/bin
安装maven
tar zxf apache-maven-3.3.9.tar
修改vim /etc/profile
export MAVEN_HOME=/usr/maven/apache-maven-3.3.9
export PATH=${MAVEN_HOME}/bin:${PATH}
解压:
cd /opt/spark
tar zxf spark-2.1.0.tgz
3.maven编译spark
(1)添加内存
export MAVEN_OPTS="-Xmx8g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=2048M"
(2)修改spark的pom.xml文件中央仓库
CDH的中央仓库https://repository.cloudera.com/content/repositories/releases/
阿里云的中央仓库http://maven.aliyun.com/nexus/content/groups/public/
(3)在spark的pom.xml文件修改hadoop版本
hadoop-2.6.0
(4)maven编译
mvn -Phadoop-2.6 -Dhadoop.version=2.6.0-CDH5.10.0 -Pyarn -Phive -Phive-thriftserver -DskipTests -T 4 -Uclean package
4.make-distribution.sh打包spark
(1)注释make-distribution.sh中maven部分
vim /opt/spark/spark-2.1.0/dev/make-distribution.sh
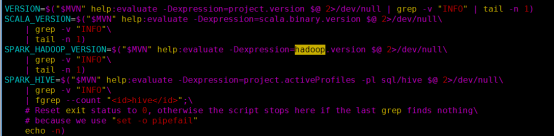


(2)添加版本号
VERSION=2.1.0
SCALA_VERSION=2.11.8
SPARK_HADOOP_VERSION=2.6.0-CDH5.10.0
SPARK_HIVE=1.2.1
(3)执行make-distribution.sh命令
./make-distribution.sh --tgz
(4)打包成功
spark-2.1.O-bin-2.6.0-CDH5.10.0.tgz
Spark2.1.0编译的更多相关文章
- Spark2.0编译
Spark2.0编译 1 前言 Spark2.0正式版于今天正式发布,本文基于CDH5.0.2的Spark编译. 2 编译步骤 #2.1 下载源码 wget https://github.com/ap ...
- mac os x 编译spark-2.1.0 for hadoop-2.7.3
mac os x maven编译spark-2.1.0 for hadoop-2.7.3 1.官方文档中要求安装Maven 3.3.9+ 和Java 8 ; 2.执行 export ...
- Spark记录-源码编译spark2.2.0(结合Hive on Spark/Hive on MR2/Spark on Yarn)
#spark2.2.0源码编译 #组件:mvn-3.3.9 jdk-1.8 #wget http://mirror.bit.edu.cn/apache/spark/spark-2.2.0/spark- ...
- spark2.1.0的源码编译
本文介绍spark2.1.0的源码编译 1.编译环境: Jdk1.8或以上 Hadoop2.7.3 Scala2.10.4 必要条件: Maven 3.3.9或以上(重要) 点这里下载 http:// ...
- Spark2.1.0——运行环境准备
学习一个工具的最好途径,就是使用它.这就好比<极品飞车>玩得好的同学,未必真的会开车,要学习车的驾驶技能,就必须用手触摸方向盘.用脚感受刹车与油门的力道.在IT领域,在深入了解一个系统的原 ...
- Spark2.1.0——Spark初体验
学习一个工具的最好途径,就是使用它.这就好比<极品飞车>玩得好的同学,未必真的会开车,要学习车的驾驶技能,就必须用手触摸方向盘.用脚感受刹车与油门的力道.在IT领域,在深入了解一个系统的原 ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- spark最新源码下载并导入到开发环境下助推高质量代码(Scala IDEA for Eclipse和IntelliJ IDEA皆适用)(以spark2.2.0源码包为例)(图文详解)
不多说,直接上干货! 前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. ...
- Spark2.1.0模型设计与基本架构(上)
随着近十年互联网的迅猛发展,越来越多的人融入了互联网——利用搜索引擎查询词条或问题:社交圈子从现实搬到了Facebook.Twitter.微信等社交平台上:女孩子们现在少了逛街,多了在各大电商平台上的 ...
随机推荐
- asp.net core 2.0中的配置(1)---Configuration
配置就是一个装配数据字典的过程,一个字典也就是一个键值对,所以从配置就是键值对. 在asp.net core中关于配置是由四个基本的类型来支撑的,是①IConfigurationSource②ICon ...
- Docker(十四)-Docker四种网络模式
Docker 安装时会自动在 host 上创建三个网络,我们可用 docker network ls 命令查看: none模式,使用--net=none指定,该模式关闭了容器的网络功能. host模式 ...
- zip 与 unzip的简单使用
先看help Copyright (c) - Info-ZIP - Type 'zip "-L"' for software license. Zip ). Usage: zip ...
- Xshell 使用数字小键盘进行vim 写入操作.
Copy From http://blog.csdn.net/shenzhen206/article/details/51200869 感谢原作者 在putty或xshell上用vi/vim的时候,开 ...
- python模块_pcharm导入包的问题
1.添加pip包 2.导入项目需要由内置包(library root)
- ava 8中的新功能特性
正如我之前所写的,Java 8中的新功能特性改变了游戏规则.对Java开发者来说这是一个全新的世界,并且是时候去适应它了. 在这篇文章里,我们将会去了解传统循环的一些替代方案.在Java 8的新功能特 ...
- mysql 分页数据错乱
最近在使用mysql 分页查询数据的时候发现返回的数据与预期的不一样,显示数据重复错乱. 在官方文档 有这样一句话 If multiple rows have identical values in ...
- python---str和repr
在 Python 中要将某一类型的变量或者常量转换为字符串对象通常有两种方法,即 str() 或者 repr() . 区别与使用 函数str() 用于将值转化为适于人阅读的形式,而repr() 转化为 ...
- BZOJ3261最大异或和——主席树
题目描述 给定一个非负整数序列{a},初始长度为N. 有M个操作,有以下两种操作类型: 1.Ax:添加操作,表示在序列末尾添加一个数x,序列的长度N+1. 2.Qlrx:询问操作,你需要找到一个位置p ...
- MT【229】最小值函数
已知定义域为$R$的函数,$f(x),g(x)$满足:$f(x)+g(x)=e^{-x^2+1}$,则$min\{f(x),g(x)\}$的最大值为______ 解答:$min\{f(x),g(x)\ ...