深度森林DeepForest
级联森林(Cascade Forest)
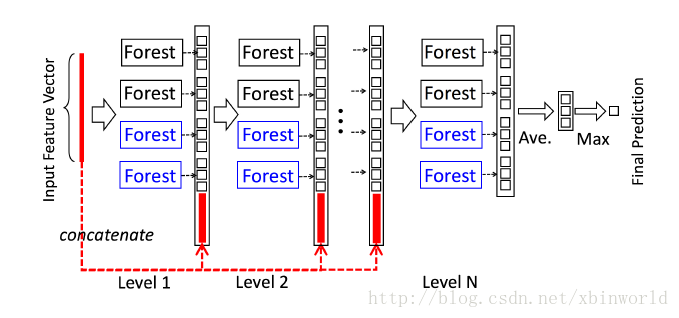
级联森林结构的图示。级联的每个级别包括两个随机森林(蓝色字体标出)和两个完全随机树木森林(黑色)。
假设有三个类要预测,因此,每个森林将输出三维类向量,然后将其连接以重新表示原始输入。注意,要将前一级的特征和这一级的特征连接在一起——在最后会有一个例子,到时候再具体看一下如何连接。
给定一个实例(就是一个样本),每个森林会通过计算在相关实例落入的叶节点处的不同类的训练样本的百分比,然后对森林中的所有树计平均值,以生成对类的分布的估计。如下图所示,其中红色部分突出了每个实例遍历到叶节点的路径。叶节点中的不同标记表示了不同的类。被估计的类分布形成类向量(class vector),该类向量接着与输入到级联的下一级的原始特征向量相连接。例如,假设有三个类,则四个森林每一个都将产生一个三维的类向量,因此,级联的下一级将接收12 = 3×4个增强特征(augmented feature)。
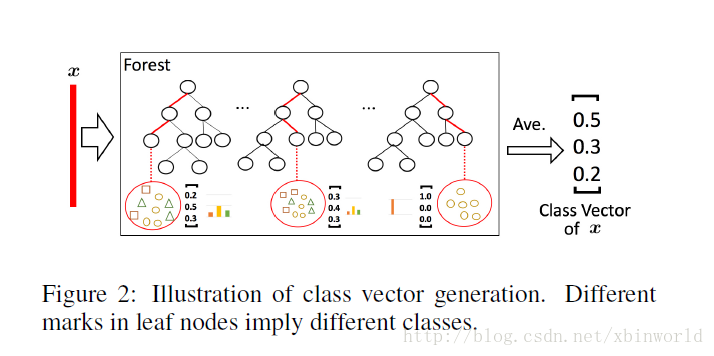
为了降低过拟合风险,每个森林产生的类向量由k折交叉验证(k-fold cross validation)产生。具体来说,每个实例都将被用作 k -1 次训练数据,产生 k -1 个类向量,然后对其取平均值以产生作为级联中下一级的增强特征的最终类向量。需要注意的是,在扩展一个新的级后,整个级联的性能将在验证集上进行估计,如果没有显着的性能增益,训练过程将终止;因此,级联中级的数量是自动确定的。与模型的复杂性固定的大多数深度神经网络相反,gcForest 能够适当地通过终止训练来决定其模型的复杂度(early stop)。这使得 gcForest 能够适用于不同规模的训练数据,而不局限于大规模训练数据。
多粒度扫描(Multi-Grained Scanning)
深度神经网络在处理特征关系方面是强大的,例如,卷积神经网络对图像数据有效,其中原始像素之间的空间关系是关键的。(LeCun et al., 1998; Krizhenvsky et al., 2012),递归神经网络对序列数据有效,其中顺序关系是关键的(Graves et al., 2013; Cho et al.,2014)。受这种认识的启发,我们用多粒度扫描流程来增强级联森林。
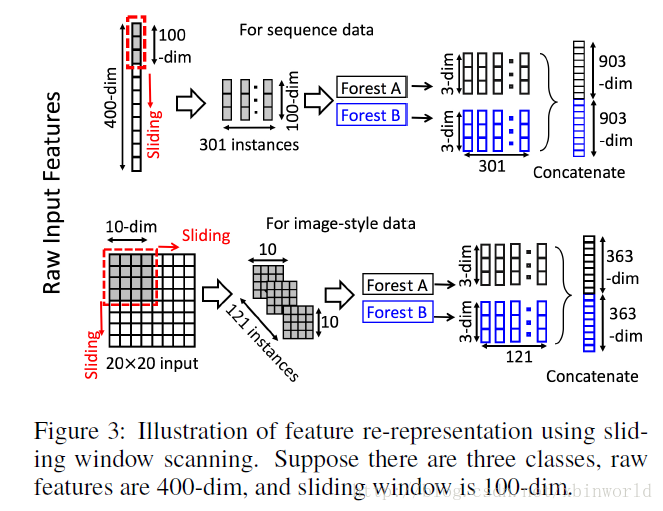
滑动窗口用于扫描原始特征。假设有400个原始特征,并且使用100个特征的窗口大小。对于序列数据,将通过滑动一个特征的窗口来生成100维的特征向量;总共产生301个特征向量。如果原始特征具有空间关系,比如图像像素为400的20×20的面板,则10×10窗口将产生121个特征向量(即121个10×10的面板)。从正/负训练样例中提取的所有特征向量被视为正/负实例;它们将被用于生成类向量:从相同大小的窗口提取的实例将用于训练完全随机树森林和随机森林,然后生成类向量并连接为转换后的像素。如上图的上半部分所示,假设有3个类,并且使用100维的窗口;然后,每个森林产生301个三维类向量,导致对应于原始400维原始特征向量的1,806维变换特征向量。通过使用多个尺寸的滑动窗口,最终的变换特征矢量将包括更多的特征,如下图所示。
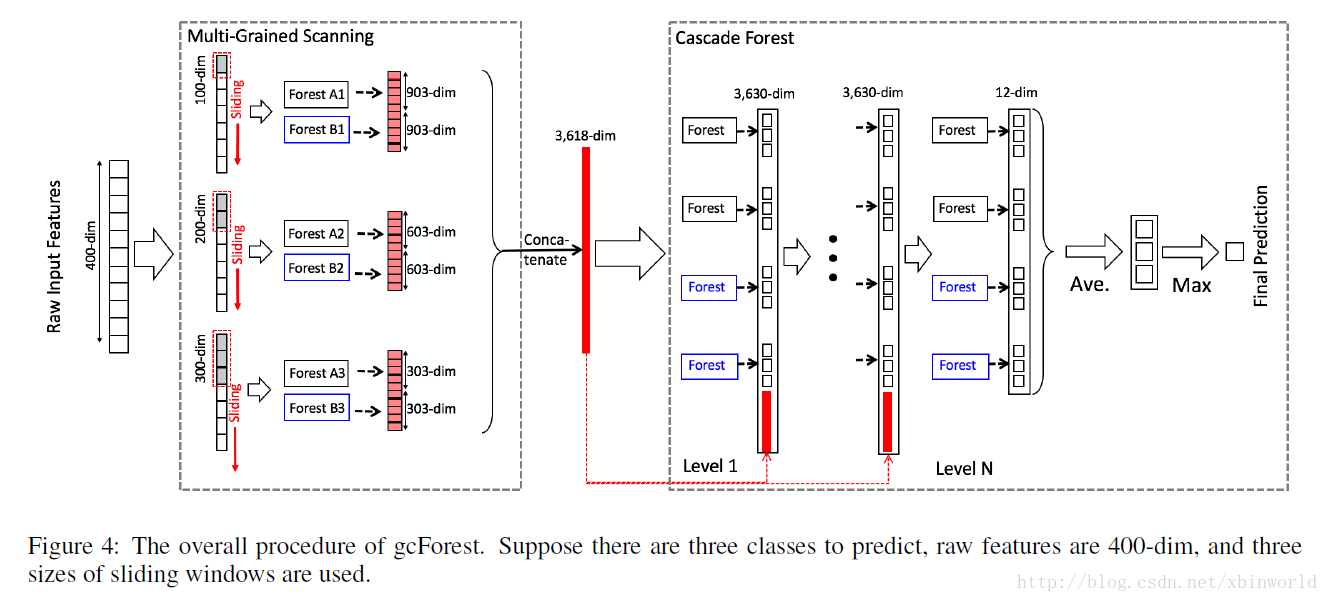
concat成一个3618-dim的原始数据,表示原始的一个数据样本,第一级的输出是12+3618=3630,后面也是一样,直到最后第N级,只有12个输出,然后在每一类别上做avg,然后输出max那一类的label,那就是最终的预测类别。
深度森林DeepForest的更多相关文章
- 学习笔记TF053:循环神经网络,TensorFlow Model Zoo,强化学习,深度森林,深度学习艺术
循环神经网络.https://github.com/aymericdamien/TensorFlow-Examples/blob/master/examples/3_NeuralNetworks/re ...
- 【深度森林第三弹】周志华等提出梯度提升决策树再胜DNN
[深度森林第三弹]周志华等提出梯度提升决策树再胜DNN 技术小能手 2018-06-04 14:39:46 浏览848 分布式 性能 神经网络 还记得周志华教授等人的“深度森林”论文吗?今天, ...
- AI产业将更凸显个人英雄主义 周志华老师的观点是如此的有深度
今天无意间在网上看的了一则推送,<周志华:AI产业将更凸显个人英雄主义> http://tech.163.com/18/0601/13/DJ7J39US00098IEO.html 摘录一些 ...
- [重磅]Deep Forest,非神经网络的深度模型,周志华老师最新之作,三十分钟理解!
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 深度学习最大的贡献,个人认为就是表征 ...
- LSH︱python实现局部敏感随机投影森林——LSHForest/sklearn(一)
关于局部敏感哈希算法.之前用R语言实现过,可是由于在R中效能太低.于是放弃用LSH来做类似性检索.学了python发现非常多模块都能实现,并且通过随机投影森林让查询数据更快.觉得能够试试大规模应用在数 ...
- 关于ML的思考讲座-周zh-11.30日
1.深度神经网络 1.以往神经网络采用单或双隐层结构,虽然参照了生物上的神经元,但是从本质上来说还是数学,以函数嵌套形成. 2.通常使用的激活函数是连续可微(differentiable)的,sigm ...
- 用Python实现随机森林算法,深度学习
用Python实现随机森林算法,深度学习 拥有高方差使得决策树(secision tress)在处理特定训练数据集时其结果显得相对脆弱.bagging(bootstrap aggregating 的缩 ...
- scikit-learn随机森林调参小结
在Bagging与随机森林算法原理小结中,我们对随机森林(Random Forest, 以下简称RF)的原理做了总结.本文就从实践的角度对RF做一个总结.重点讲述scikit-learn中RF的调参注 ...
- Bagging与随机森林算法原理小结
在集成学习原理小结中,我们讲到了集成学习有两个流派,一个是boosting派系,它的特点是各个弱学习器之间有依赖关系.另一种是bagging流派,它的特点是各个弱学习器之间没有依赖关系,可以并行拟合. ...
随机推荐
- css设置点击态样式
.rightMenu:active { background-color: rgba(46, 103, 222, 0.13); }
- VirtualBox fedora29 安装
目录 准备工作 VirtualBox安装 fedora安装 快捷键定义 准备工作 平台配置 win10 64位 内存 8G 硬盘 1T 下载地址 VirtualBox 5.2.22:https://w ...
- SQL-45 将titles_test表名修改为titles_2017。
题目描述 将titles_test表名修改为titles_2017.CREATE TABLE IF NOT EXISTS titles_test (id int(11) not null primar ...
- hadoop Non DFS Used是什么
首先我们先来了解一下Non DFS User是什么? Non DFS User的意思是:非hadoop文件系统所使用的空间,比如说本身的linux系统使用的,或者存放的其它文件 它的计算公式: n ...
- 谷歌浏览器chrome的vuejs devtools 插件的安装
(推荐方法2) 安装方法1: 需正常打开chrome商店,搜索vuejs devtools 安装.chrome://extensions/ 开发者工具-扩展程序下启用: 方法2: github下载插件 ...
- JavaScript实现本地图片上传前进行裁剪预览
本项目支持IE8+,测试环境IE8,IE9,IE10,IE11,Chrome,FireFox测试通过 另:本项目并不支持Vue,React等,也不建议,引入JQuery和Vue.React本身提倡的开 ...
- Ubuntu 17.10 安装Caffe(cpu)并配置Matlab接口
(1)安装依赖: sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-ser ...
- VS Code + NWJS(Node-Webkit)0.14.7 + SQLite3 + Angular6 构建跨平台桌面应用
一.项目需求 最近公司有终端桌面系统需求,需要支持本地离线运行(本地数据为主,云端数据同步),同时支持Window XP,最好跨平台.要求安装配置简单(一次性打包安装),安装包要小,安装时间短,可离线 ...
- video自动填充满父级元素
想要video能自动填充慢父div的大小,只要给video标签加上style="width= 100%; height=100%; object-fit: fill"即可. obj ...
- 前台的url通过 ActionName?var1=xx&var2=yy 的形式传给特定action
本文对自己开发的基于lucene和J2EE技术的搜索引擎开发经验进行简单总结.今后可能会从性能的角度总结lucene开发经验.当数据上TB级别后,分布式lucene以及结合分布式文件系统(如HDFS) ...