HBase 笔记1
cap理论: 一致性 可用性 可靠性
任何分布式系统只能最多满足上面2点,无法全部满足
NOSQL = Not Only SQL = 不只是SQL
HBase速度并不快,知识当数据量很大时它慢的不明显
HBase缺点:
数据分析是弱项,对于整个NOSQL生态圈,基本都不支持表关联
需求如下时不支持使用HBase:
主要需求是数据分析,比如做报表
单表数据量不超过千万
需求如下时使用HBase:
单表数据量超过千万,并发还挺高
数据分析需求弱,或不需要那么灵活/实时
宏观上看
HBase部署架构上分为: Master服务器 RegionServer服务器
一般情况下:一个集群=1*Master服务器+N*RegionServer服务器
Master服务器维护表结构信息
Region Server服务器负责存储实际数据,保存的表数据直接存储在HDFS上; RegionServer依赖Zookeeper服务,Zookeeper扮演着管家的角色,管理所有Region Server信息,包括具体的数据段存放在哪个Region Server
客户端每次与HBase连接,都是先和Zookeeper通信,查询出需要连接哪个Region Server,然后再连接Region Server
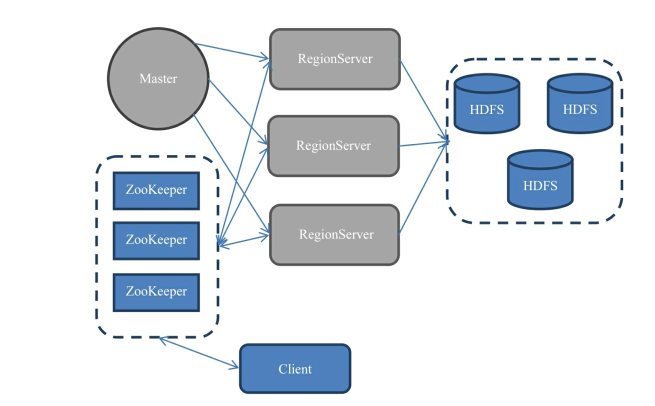
HBase特殊一点:客户端获取数据由客户端直接连接RegionServer, Master挂掉依然可以查询数据,存储/删除数据,但是不能新建表
微观上看
Region: 是一段数据的集合(多个行的集合), HBase中的表可以分成1个或多个Region
一个Region Server上存在1个或多个Region
数据量大时,HBase会拆分Region
Hbase负载均衡时,Region可能会从一个Region Server上移到另一个RegionServer上
Region是基于HDFS实现的
RegionServer 是存放Region的容器,直观上就是服务器上的一个服务
Master 角色像是打杂的,只负责各种协调工作,如建表,删除表等,他们的共性就是需要跨Region Server
存储架构
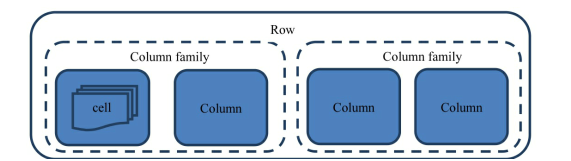
HBase最基本的存储单位是列 一列或多列形成一行row
HBase不是严格的行列对齐,这一行可能有3列,下一行有4列,行与行的列可以完全不一样
每个行都有唯一的行键row key来标定这个行的唯一特性,每个列有多个版本,多个版本的值存在单元格cell(单元格是数据存储的最小单位)中
行键row key: 由用户指定的一串不可重复的字符串,HBase是根据行键来进行排序(字典排序)进而确定存储位置
若干列组成一个列族
列族需要在建表时就确定,此外表的很多属性(过期时间,数据块缓存等)都定义在列族上,不同的列族有完全不同的属性配置,相同列族内的列具有相同的属性
列必须依赖列族存在,单独的列无意义
HBase中列的名称前面总是带着所属的列族,如b:age
唯一确定一个值: 行键:列族:列:版本号(rowkey:column family:column:version),版本号不写则默认最新的版本
HBase中,每个存储语句必须精确定义的写出数据要存储到哪个单元格,而单元格由 表:列族:行:列定义
HBase 笔记1的更多相关文章
- HBase笔记:对HBase原理的简单理解
早些时候学习hadoop的技术,我一直对里面两项技术倍感困惑,一个是zookeeper,一个就是Hbase了.现在有机会专职做大数据相关的项目,终于看到了HBase实战的项目,也因此有机会搞懂Hbas ...
- Hbase笔记——RowKey设计
一).什么情况下使用Hbase 1)传统数据库无法承载高速插入.大量读取. 2)Hbase适合海量,但同时也是简单的操作. 3)成熟的数据分析主题,查询模式确立不轻易改变. 二).现实场景 1.电商浏 ...
- HBase笔记--自定义filter
自定义filter需要继承的类:FilterBase 类里面的方法调用顺序 方法名 作用 1 boolean filterRowKey(Cell cell) 根据row key过滤row.如果需要 ...
- HBase笔记--filter的使用
HBASE过滤器介绍: 所有的过滤器都在服务端生效,叫做谓语下推(predicate push down),这样可以保证被过滤掉的数据不会被传送到客户端. 注意: 基于字符串的比较器,如 ...
- HBase笔记--编程实战
HBase总结:http://blog.csdn.net/lifuxiangcaohui/article/details/39997205 (very good) Spark使用Java读取hbas ...
- HBase笔记--安装及启动过程中的问题
1.使用hbase shell的时候运行命令执行失败 例如:在shell下执行 status,失败. 可能的原因:节点之间的时间差距过大 解决方法调整两个节点的时间,使二者一致,这里用了个比较笨的方法 ...
- HBase笔记6 过滤器
过滤器 过滤器是GET或者SCAN时过滤结果用的,相当于SQL的where语句 HBase中的过滤器创建后会被序列化,然后分发到各个region server中,region server会还原过滤器 ...
- HBase笔记5(诊断)
阻塞急救: RegionServer内存设置太小: 解决方案: 设置Region Server的内存要在conf/hbase-env.sh中添加export HBASE_REGIONSERVER_OP ...
- HBase笔记4(调优)
Master/Region Server调优 JVM调优 默认的RegionServer内存是1G,而Memstore默认占40%,即400M,实在是太小了,可以通过HBASE_HEAPSIZE参数修 ...
- HBase 笔记3
数据模型 Namespace 表命名空间: 多个表分到一个组进行统一的管理,需要用到表命名空间 表命名空间主要是对表分组,对不同组进行不同环境设定,如配额管理 安全管理 保留表空间: HBase中有 ...
随机推荐
- Integer.parseInt vs Integer.valueOf
一直搞不清楚这两个有什么区别.刚才特意查了一下帖子. Integer.parseInt 返回的是 primitive int Integer.valueOf 返回的是 Integer Object ...
- springMVC 返回时间格式转换
<mvc:annotation-driven> <mvc:message-converters> <bean class="org.springframewor ...
- Linux服务器重启后eureka报错
在Linux服务器重启后,首次启动应用时查看eureka注册中心,报错 EMERGENCY! EUREKA MAY BE INCORRECTLY CLAIMING INSTANCES ARE UP W ...
- VxWorks信号量问题
VxWorks主要提供如下API进行信号量的创建.获取和释放: 参数1:SEM_Q_PRIORITY,SEM_Q_FIFO SEM_Q_PRIORITY(值为0x1):需要获取该信号量的任务基于优 ...
- Kindeditor视频上传问题处理
初始的时候,video这个标签kindeditor是不识别的,只要html处理或者全屏的时候,都会被排除掉.如果想要video存在,则需要设置属性filterMode :false 如果只是想要某个标 ...
- 二、Sql Server 基础培训《进度2-关于主键(知识点学习)》
学习作业2: 问题1:主键都有哪些方式? 问题2:本次实战案例建立的主键采用哪种方式? 问题3:猜猜金蝶K3WISE建立的主键采用哪种方式? 问题4:谈谈手工主键增长设置具体实现思路?(选 ...
- Chrome Google浏览器下载
https://support.google.com/chrome/answer/95346?co=GENIE.Platform%3DDesktop&hl=zh-Hans 下载和安装 G ...
- PowerBI与Visio
前言 如何在Power BI中使用Visio, 刚好最近微软推出了适用于Power BI 的 Visio自定义可视化对象预览,分享给大家. 我们先看一下效果: 通过自定义可视化对象,将Visio ...
- Angel - MemoryDataBlock - angel.task.estimize.sample.number
angel.task.estimize.sample.number val validData = new MemoryDataBlock[LabeledData](isVali) trainData ...
- pushd和popd
[原文地址] 其实,很早就知道pushd和popd在linux中可以用来方便地在多个目录之间切换.那时比较浮躁,感觉切换目录没必要这么复杂.在实际中,发现通过使用pushd和popd能够极大地提高 ...