机器学习算法--Perceptron(感知机)算法
感知机:
假设输入空间是\(\chi\subseteq R^n\),输出空间是\(\gamma =\left( +1,-1\right)\)。输入\(\chi\in X\)表示实例的特征向量,对应于输入空间的点;输出\(y\in \gamma\)表示实例的类别。由输入空间到输出空间的如下函数:
\[f\left( x\right) =sign\left( wx+b\right)
\]称为感知机。其中,w和b为感知机模型的参数,sign是符号函数,即:
\[sign\left( x\right) =\begin{cases}+1 &x\geq 0\\-1 &x<0 \end{cases}
\]
感知机学习策略
假设训练数据集是线性可分的,感知机学习的目标就是求得一个能够将训练集正实例点和负实例点完成正确分开的分离超平面。为了找出这样的超平面,即确定感知机模型参数w,b,需定义损失函数并将损失函数极小化。
损失函数使用误分类点到超平面S的总距离,因此输入空间\(R^n\)中任何一点\(x_0\)到超平面S的距离为:
\]
在这里,\(\left\| w\right\|\)是w的\(L_2\)范数。
对于误分类的数据\(\left(x_i,y_i\right)\)来说,
\]
成立。因为当\(wx_i + b >0\)时,\(y_i=-1\),而当\(wx_i + b < 0\)时,\(y_i=+1\),因此,误分类点\(x_i\)到超平面S的距离是:
\]
这样,假设超平面S的误分类点集合为M,那么所以误分类点到超平面S的总距离为:
\]
不考虑\(\dfrac {1}{\left\| w\right\| }\),就得到感知机学习的损失函数:
\]
其中M为误分类点的集合。
感知机算法原始形式
感知机算法是使得损失函数\(L(w,b)\)极小化的最优化问题,可以使用随机梯度下降法来进行最优化。
假设误分类点集合M是固定的,那么损失函数\(L(w,b)\)的梯度由
\]
\]
给出,随机选取一个误分类点\((x_i,y_i)\),对w,b进行更新:
\]
\]
其中\(\eta(0<\eta \leq1)\) 称为学习率(learning rate),这样通过迭代可以使得损失函数\(L(w,b)\)不断减小,直到为0。
感知机算法原始形式的主要训练过程:
def trainPerceptron(dataMat, labelMat, eta):
m, n = dataMat.shape
weight = np.zeros(n)
bias = 0
flag = True
while flag:
for i in range(m):
if np.any(labelMat[i] * (np.dot(weight, dataMat[i]) + bias) <= 0):
weight = weight + eta * labelMat[i] * dataMat[i].T
bias = bias + eta * labelMat[i]
print("weight, bias: ", end="")
print(weight, end=" ")
print(bias)
flag = True
break
else:
flag = False
return weight, bias
完整代码可以前往我的github查看,还有可视化过程。
https://github.com/yangliu0/MachineLearning/tree/master/Perceptron
感知机算法的对偶形式
假设\(w_0,b_0\)均初始化为0,对误分类点通过
\]
\]
逐步修改\(w,b\),设修改n次,则\(w,b\)关于\((w_i,y_i)\)的增量分为是\(\alpha_i y_ix_i\)和\(\alpha_i y_i\),这里的\(\alpha_i=n_i \eta\),其中\(n_i\)表示第i个点误分类的次数,这样最后学习到的\(w,b\)可以分别表示为
\]
\]
实例点更新的次数越多,意味着它距离分离超平面越近,也就越难正确分类。
训练过程:输出\(\alpha,b\),其中\(\alpha = (\alpha_1, \alpha_2,...,\alpha_N)^T\)
(1)\(\alpha\leftarrow0, b\leftarrow0\)
(2)在训练集中选取数据\((x_i, y_i)\)
(3)如果\(y_{i}\left( \sum ^{n}_{j=1}\alpha _{j}y_{j}x_{j}\cdot x_{i}+b\right)\leq0\),则
\]
\]
(4)转到(2),直到没有错误。
最后通过\(w=\sum ^{N}_{i=1}\alpha _{i}y_{i}x_{i}\)计算出\(w\),使用上述过程求出的\(b\),即计算出模型参数。
以下就是上述感知机对偶形式的python训练代码:
def trainModel(dataMat, labelMat, alpha, b, eta):
flag = True
while flag:
for i in range(m):
if (labelMat[i, 0] * (np.sum((alpha * labelMat * np.dot(dataMat, dataMat[i].T).reshape((m, 1)))) + b)) <= 0:
alpha[i] = alpha[i] + eta
b = b + eta * labelMat[i]
flag = True
break
else:
flag = False
w = np.dot(dataMat.T, alpha * labelMat)
return w, b
以下就是结果可视化图,可以看出,训练的感知机算法对线性可分的点进行了很好的划分。
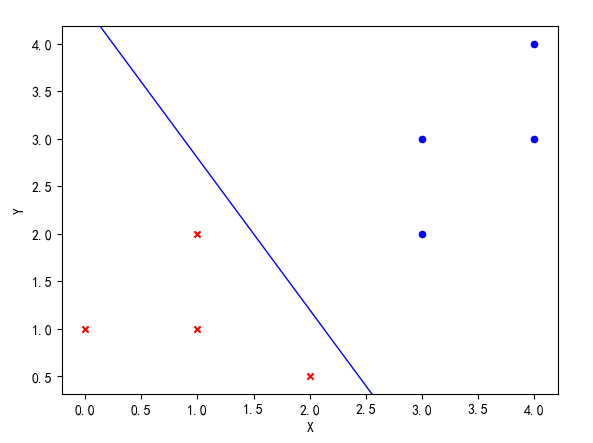
感知机算法的原始形式和对偶形式分别对应了支持向量机(SVM)的两种相应形式,是它们的基础。
上述两种形式的感知机算法完整实现可以在我的github查看,使用python实现。
https://github.com/yangliu0/MachineLearning/tree/master/Perceptron
参考文献
[1]统计学习方法.李航
机器学习算法--Perceptron(感知机)算法的更多相关文章
- 机器学习---用python实现感知机算法和口袋算法(Machine Learning PLA Pocket Algorithm Application)
之前在<机器学习---感知机(Machine Learning Perceptron)>一文中介绍了感知机算法的理论知识,现在让我们来实践一下. 有两个数据文件:data1和data2,分 ...
- 机器学习笔记(一)· 感知机算法 · 原理篇
这篇学习笔记强调几何直觉,同时也注重感知机算法内部的动机.限于篇幅,这里仅仅讨论了感知机的一般情形.损失函数的引入.工作原理.关于感知机的对偶形式和核感知机,会专门写另外一篇文章.关于感知机的实现代码 ...
- 【分类算法】感知机(Perceptron)
0 - 算法描述 感知机算法是一类二分类算法,其问题描述为,给定一个训练数据集 $$T=\{(x_1,y_1),(x_2,y_2),\cdots,(x_N,y_N)\},$$ 其中$x_i\in \m ...
- Python 实现简单的感知机算法
感知机 随机生成一些点和一条原始直线,然后用感知机算法来生成一条直线进行分类,比较差别 导入包并设定画图尺寸 import numpy as np import matplotlib.pyplot a ...
- 感知机算法(PLA)代码实现
目录 1. 引言 2. 载入库和数据处理 3. 感知机的原始形式 4. 感知机的对偶形式 5. 多分类情况-one vs. rest 6. 多分类情况-one vs. one 7. sklearn实现 ...
- 机器学习系列------1. GBDT算法的原理
GBDT算法是一种监督学习算法.监督学习算法需要解决如下两个问题: 1.损失函数尽可能的小,这样使得目标函数能够尽可能的符合样本 2.正则化函数对训练结果进行惩罚,避免过拟合,这样在预测的时候才能够准 ...
- 机器学习六--K-means聚类算法
机器学习六--K-means聚类算法 想想常见的分类算法有决策树.Logistic回归.SVM.贝叶斯等.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别 ...
- 机器学习10大经典算法.doc
详见 F:\工程硕士\d电子书\26 数据挖掘 小结: 1. C4.5 C4.5算法是机器学习算法中的一种分类决策树算法,其核心算法是ID3算法. C4.5算法继承了ID3算法的优点,并在以下几方面 ...
- 机器学习之K近邻算法(KNN)
机器学习之K近邻算法(KNN) 标签: python 算法 KNN 机械学习 苛求真理的欲望让我想要了解算法的本质,于是我开始了机械学习的算法之旅 from numpy import * import ...
随机推荐
- bootstrap学习之利用CSS属性pointer-events禁用表单控件
参考链接: CSS3 pointer-events:none应用举例及扩展 首先pointer-events在除去SVG中的应用只有两个值:AUTO | NONE pointer-events:non ...
- vue 父组件传递子组件事件
在开发中,碰到一个需要从父组件传入方法,子组件点击触发,说白了就是,把方法传入给子组件调用 <el-col v-for='data in spreadFormat.icons' class=&q ...
- keepalived实现nginx高可用
keepalived是什么 keepalived直译就是保持存活,在网络里面就是保持在线了,也就是所谓的高可用或热备,用来防止单点故障(单点故障是指一旦某一点出现故障就会导致整个系统架构的不可用)的发 ...
- LINUX 笔记之常用打包压缩命令
1.将所有.jpg文件打成一个名为all.tar的包 tar -cf all.tar *.gif 2.将所有.gif文件追加到all.tar tar -rf all.tar *.gif 3.更新原来t ...
- 项目总结一:响应式之CSS3 媒体查询
1.<meta name="viewport" content="width=device-width, initial-scale=1.0, user-scala ...
- MongoDB索引限制
1. 额外开销: 每个索引占据一定的存储空间,在进行插入,更新和删除操作时也需要对索引进行操作.所以,如果你很少对集合进行读取操作,建议不使用索引. 2. 内存使用: 由于索引是存储在内存(RAM)中 ...
- sql的基本知识
一.什么是sql? 全称:"结构化查询语言(Structured Query Language)",是1974年由Boyce和Chamberlin提出来的,现已经成为关系数据库的 ...
- 使用chart和echarts制作图表
前 言 chart.js是一个简单.面向对象.为设计者和开发者准备的图表绘制工具库.它可以帮你用不同的方式让你的数据变得可视化.每种类型的图表都有动画效果,并且看上去非常棒,即便是在retina ...
- CodeForces - 294A Shaass and Oskols
//////////////////////////////////////////////////////////////////////////////////////////////////// ...
- Python面向对象篇之元类,附Django Model核心原理
关于元类,我写过一篇,如果你只是了解元类,看下面这一篇就足够了. Python面向对象之类的方法和属性 本篇是深度解剖,如果你觉得元类用不到,呵呵,那是因为你不了解Django. 在Python中有一 ...