SciTech-BigDataAIML-LLM-Transformer Series-Positional Encoding: 位置编码: 统计模型(够多参数够高精度)+"够大数据"凝聚客观规律"预训练+深度NN(学习规律).
词汇
- $\large MI $(Mobile Internet): 移动互联网
- $\large IoT $(Internet of Things): 万物互联网
- \(\large Supervised\ Statistical\ Model\):
\(\large Supervised\ Learning\) 监督学习: 要用"大量训练数据", "学习总结事实规律"(模型参数)。
\(\large Statistical\ Model\) 统计模型: 用概率和统计分析方法建立模型, 对数据进行处理, 确定模型参数。 - $\large WE $(Word Embedding): 词嵌入
- $\large PE $(Positional Encoding): 词位置信息编码
统计模型和大数据的保障源于\(\large MI\)和 \(\large IoT\)
统计模型"预训练大量数据""的本质决定\(\large PE\)
\(\large PE\) 的计算公式和数学证明
1 \(\large PE\) 的计算公式
\(\large pos\ 和\ i\) 都是 \(\large N自然数\), 且由\(\large 0开始编号\); \(\large d\)是\(\large WE\)词向量维度数)
PE(pos, 2i) &= sin( \frac{pos} { 10000^{offset} }), & \ offset = \frac{i}{d} \in [0, 1) \\
PE(pos, 2i+1) &= cos( \frac{pos} { 10000^{offset} }), & \ offset = \frac{i}{d} \in [0, 1) \\
\end{align*} \]
$\large \therefore $
PE(a, 2i) &= sin( \frac{a} { 10000^{offset} }), & \ offset = \frac{i}{d} \in [0, 1) \\
PE(a, 2i+1) &= cos( \frac{a} { 10000^{offset} }), & \ offset = \frac{i}{d} \in [0, 1) \\
PE(b, 2i) &= sin( \frac{b} { 10000^{offset} }), & \ offset = \frac{i}{d} \in [0, 1) \\
PE(b, 2i+1) &= cos( \frac{b} { 10000^{offset} }), & \ offset = \frac{i}{d} \in [0, 1) \\
\end{align*} \]
$\large \because $
sin( \alpha + \beta ) &= sin( \alpha ) cos( \beta ) + cos( \alpha ) sin( \beta ) & \\
cos( \alpha + \beta ) &= cos( \alpha ) cos( \beta ) - sin( \alpha ) sin( \beta ) & \\
\end{align*} \]
$\large \therefore $
PE(a + b , 2i) &= PE(a, 2i) \times PE(b, 2i+1) + PE(a, 2i+1) \times PE(b, 2i) \\
& \Uparrow sin( \frac{(a+b)} { 10000^{offset} }) = sin( \frac{a}{ 10000^{offset}} + \frac{b}{ 10000^{offset} }) \\
PE(a + b, 2i+1) &= PE(a, 2i+1) \times PE(b, 2i+1) - PE(a, 2i) \times PE(b, 2i) \\
&\Uparrow cos( \frac{a+b} { 10000^{offset} }) = cos( \frac{a}{10000^{offset}} + \frac{b}{ 10000^{offset} }) \\
\end{align*} \]
$\large \Uparrow \therefore $
- 将一 $ Word\ Sequence$ 进行\(Word\ Embedding\),
变换为一 \(Matrix(Word\ Embeded\ Vector\ Sequence)\); - \(Matrix(Word\ Embeded\ Vector\ Sequence)\) 第 \(x(2i或2i+1)\) 维特征上,
$ hypothesis:\ Word_{a} :pos为a的词向量, \ Word_{b} :pos为b的词向量 $ ,
\(PE(a + b , 2i)\) 可表示为:
\(PE(a, 2i)与PE(b, 2i)\) 的 或 \(PE(a, 2i+1)与PE(b, 2i+1)\) 的 \(Linear\ Combination\).
\(PE(a + b, 2i+1)\) 可表示为:
\(PE(a, 2i)与PE(a, 2i+1)\) 的 或 \(PE(b, 2i)与PE(b, 2i+1)\) 的 \(Linear\ Combination\).
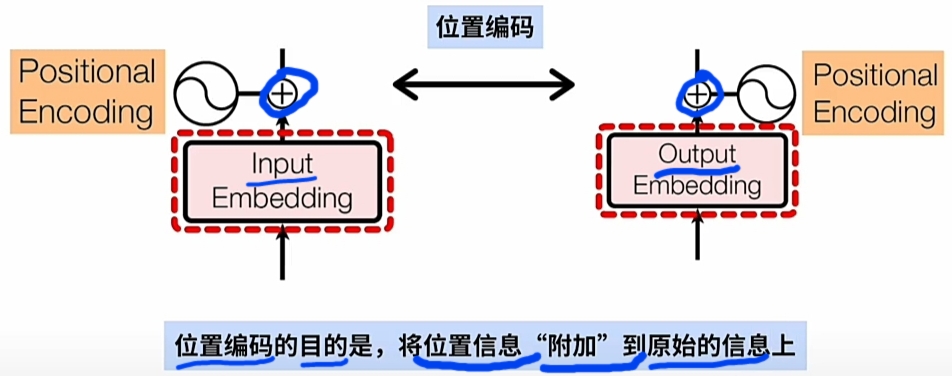
0 $\large PE $的问题
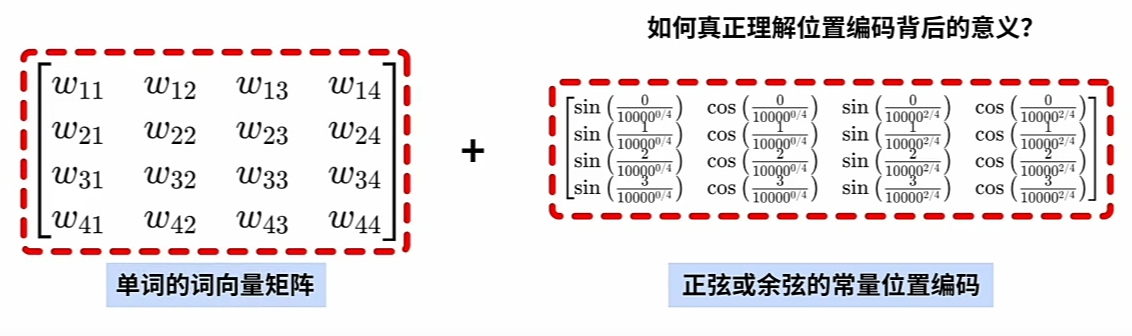
Transformer直接 \(\large WE\ +\ PE\) 实现在\(\large WE\)词嵌入向量 嵌入 \(\large PE\)词位置信息.
特别注意是每一词\(\large Word\)的\(\large WE\)的\(每一维度\)都要加上\(\large PE\)位置编码信息.
即 \(\large PE\)(位置编码矩阵)的 \(\large Shape\) 与\(\large WE\)(词嵌入编码矩阵) 的\(\large Shape\)是一致的.
![]()
![]()
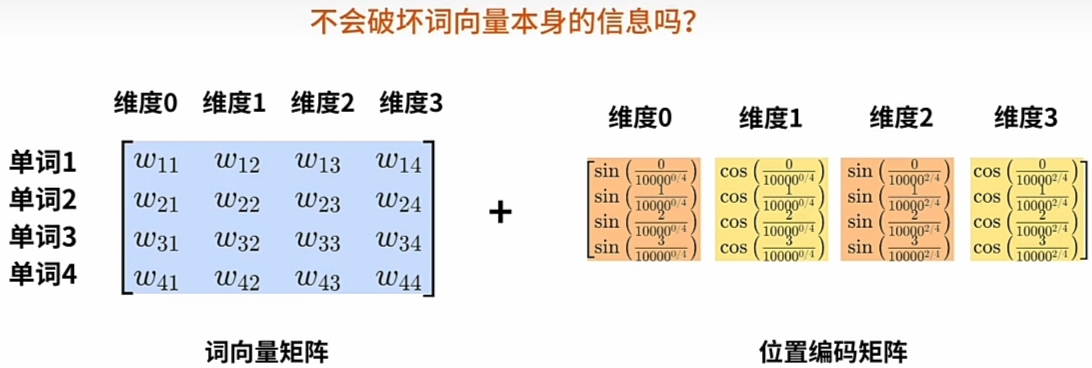
为什么可以直接 $\large WE $ 加上 \(\large PE\) 就有实际的意义?
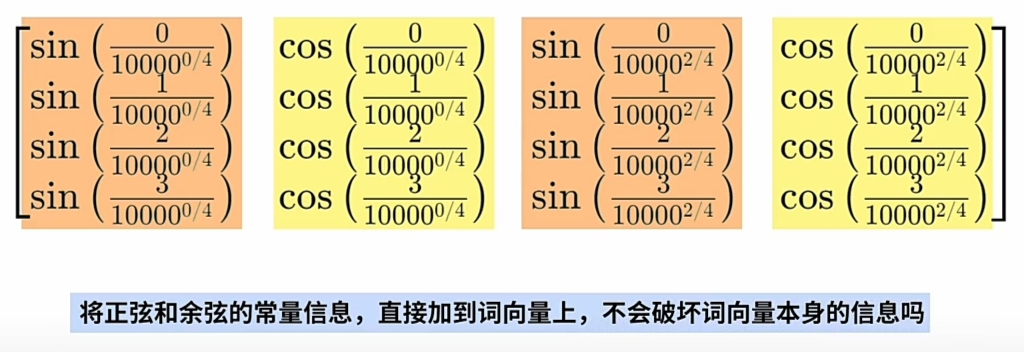
将 $\large WE $ 直接加上 $\large PE $(正弦或余弦的常量位置编码):- 不会破坏$\large WE $(词向量)本身的信息?
- 还能还原出原来\(\large Word\)及其\(\large 序列位置\) 的含义?
![]()

1 什么是 $\large PE $
$\large PE $发生在Transformer的"预训练阶段"对"大量的训练数据"进行统计分析总结数据规律。
Transformer设计“机器翻译任务”的“英译汉模型(统计概率)”为例:
- 要准备好“大量的训练数据”即大量配对互译的“英文句子” 与 “中文句子”。
用一对“Are you okay?”与 “你好吗?”例句为例.
预训练阶段:
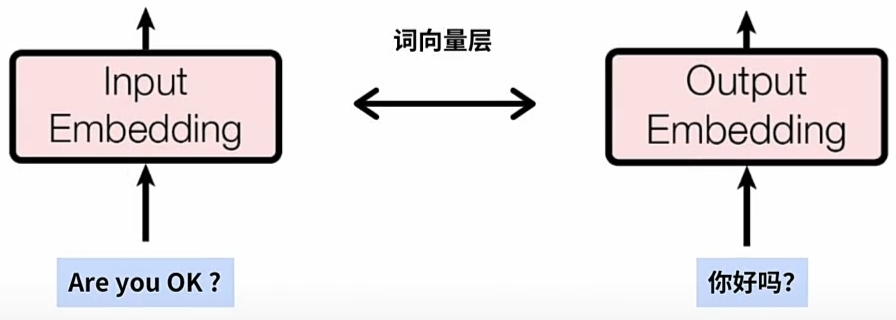
$\large WE $(Word Embedding) 词嵌入:
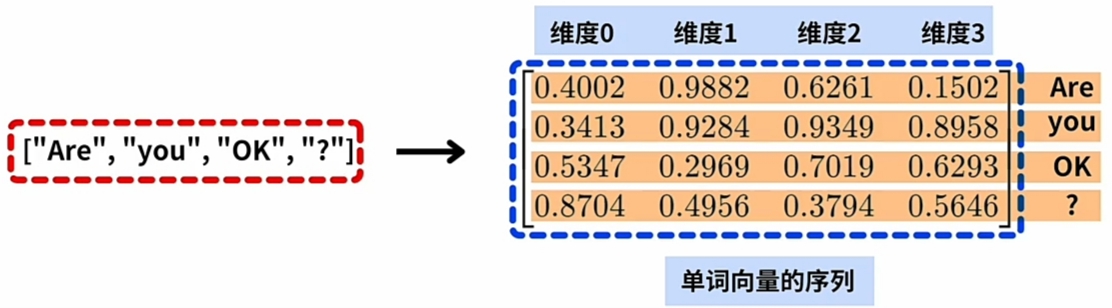
一对 配对的 英文与中文例句 分别送入\(\large Input\)与\(\large Output\)的\(\large Emebdding\)层:
\(\large Emebdding\)层完成后, 每一词 \(\large Word\) 对应 \(\large WE\) 的 一条词(嵌入)向量- "Are you okay?" 通过 \(\large Input\)侧的 \(\large Emebdding\)层, 得到英文例句的 $\large WE $
- "你好吗?" 通过 \(\large Output\)侧的 \(\large Emebdding\)层, 得到中文例句的 $\large WE $
![]()
![]()
\(\large PE\)(Positional Encoding) 词位置信息编码:
\(\large PE\)(Positional Encoding) 词位置信息编码 的goal(目标):
![]()
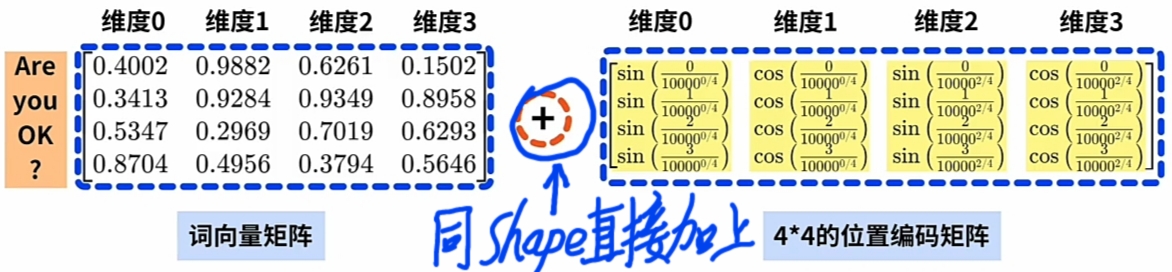
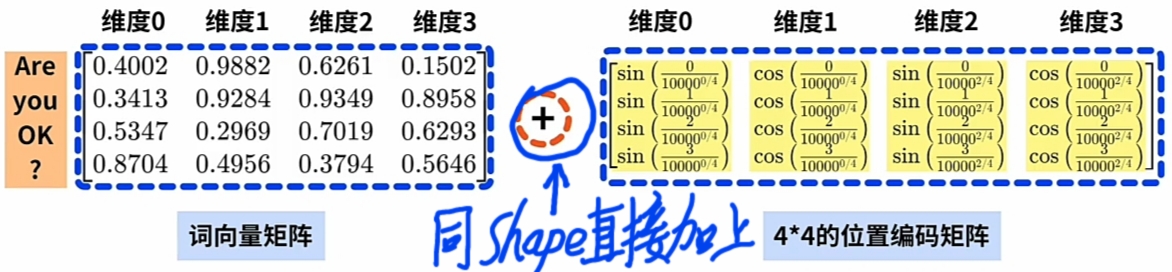
由 \(\large WE\) 矩阵, 计算同 \(\large shape\) 的 $\large PE $矩阵:
参考本文下方的“怎么计算 \(\large PE\)”章节。Transformer直接 \(\large WE\ +\ PE\), 实现在 \(\large WE\) 词向量 嵌入 \(\large PE\) 词位置信息.
![]()
预训练阶段
2 怎么计算 \(\large PE\)
- $\large PE $计算公式
![]()
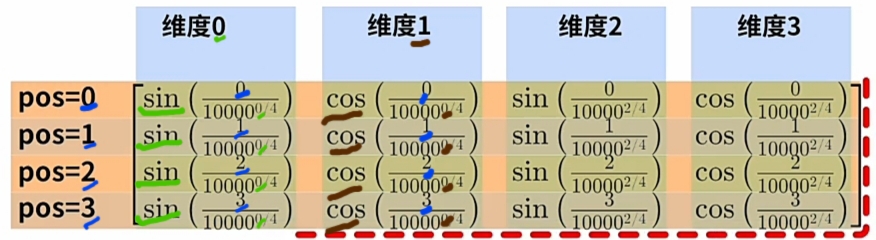
\(\large pos\) 当前Word 在输入Word Sequence 的常量位置(整数值, 由0开始编号):
![]()
\(\large d\) 当前Word对应"词向量"的"维度总数(整数值)"
假设"Are you okay?"每一Word对应"词向量"的"维度总数(整数值)" 为 4.
![]()
\(\large i\) 当前"词向量"的"当前维索引(整数值)"的一半
- 每一Word(词), 对应一"词(嵌入)向量";
- 每一"词(嵌入)向量"在"模型训练时"都统一设定为\(\large d\)维;
- 维索引由"0开始编号到\(\large d-1\)".
- 维索引(整数值)为奇数, 用\(\large sin\)正弦, 维索引(整数值)为偶数, 用\(\large cos\)余弦
![]()
计算出整个Word Sequence的每个 \(\large WE\) 的 \(\large PE\):
根据 \(\large pos\) 一一计算Word Sequence的每一Word的 \(\large PE\) ; 直到完成整个 \(\large PE\) 矩阵.
![]()
![]()
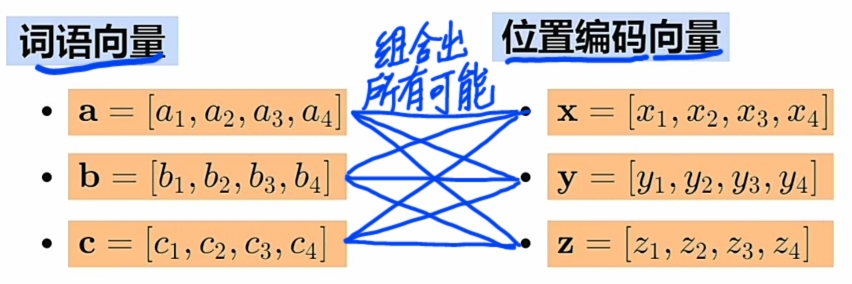
- Transformer“丰富训练数据”的内幕实现:
- 先用 不同\(\large WE\)(词向量) 与 不同 \(\large PE\) (位置编码) 生成combinations(所有组合);
- 实际训练时用生成的\(\large WE\)(词向量) 与 \(\large PE\) (位置编码)的combinations(所有组合);
- 图示:
![]()
- \(\large PE\)矩阵直接加上到其\(\large WE\)矩阵以嵌入位置信息。
![]()






3 $\large PE $的真正意义
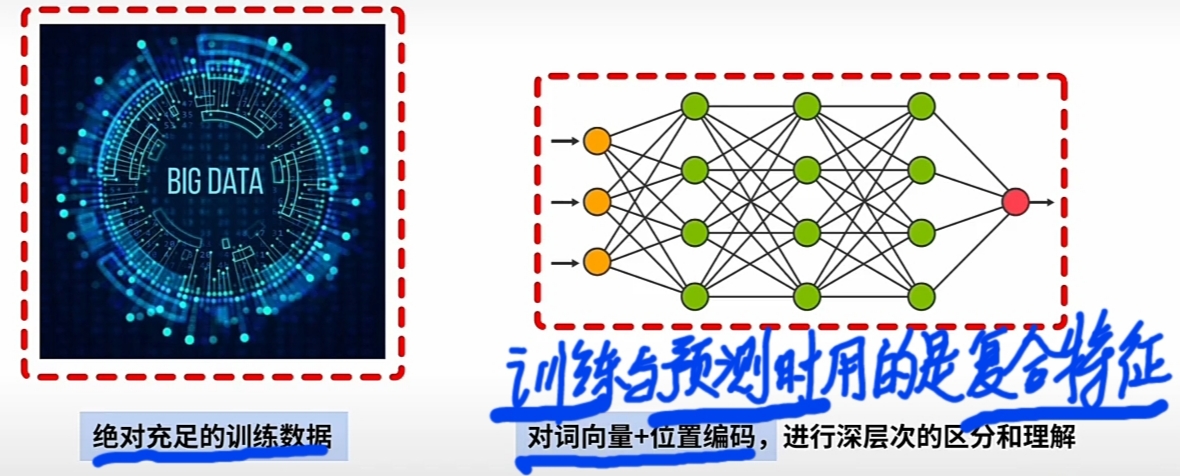
1 极大丰富预训练数据(实际训练用不同的\(\large WE\) 与 不同的\(\large PE\) 的 \(\large combinations\)).
- 使用远大于 \(\large WE\)(词向量)+\(\large PE\)(位置编码) 数量的 \(\large combinations\) 预训练.
训练并整合 \(\large WE\)(词向量)+\(\large PE\)(位置编码) 信息。是因为:
![]()
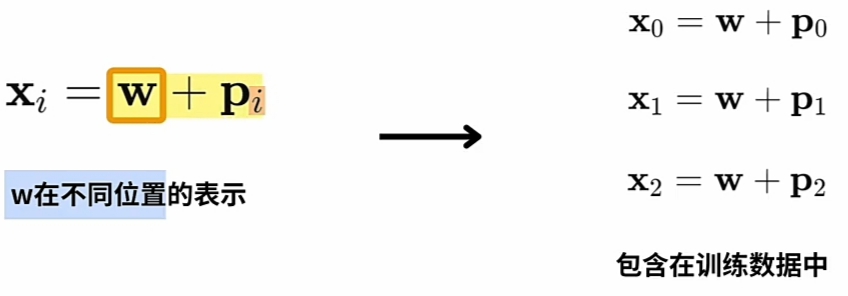
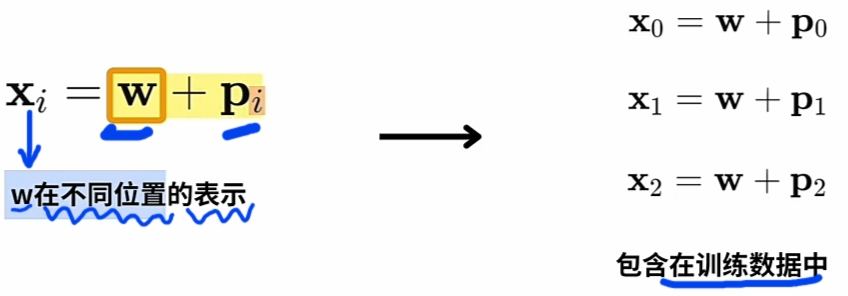
- 假设有: 三个不同\(\large WE\)(词向量) 与 三个不同\(\large PE\), 则实际训练用\(\large combinations\)):
![]()
![]()
![]()
- 使用远大于 \(\large WE\)(词向量)+\(\large PE\)(位置编码) 数量的 \(\large combinations\) 预训练.
2 为什么 Transformer 的\(\large PE\)能使“模型”理解“任一不同词”在“不同位置”的语义?
- Transformer的\(\large PE\)是统计概率模型的一部分
统计概率模型本质是:
预训练阶段: 先“统计概率分析”总结出凝聚在“预训练的数据”的“隐藏规律”
预测用阶段: 后“用模型”对“输入数据”应用与调整“预训阶段统计分析总结出的隐藏规律”. - 1 预训练阶段: Transformer Model实际用的是复合\(\large WE\ +\ PE\)的新特征.
预训练阶段, Transformer Model Designer 保障确定复合\(\large WE\ +\ PE\)的新特征是有效的. - 2 预训练阶段: 复合\(\large WE\ +\ PE\)的新特征的有效性
- 3 举例: 预训练数据上的 3个\(\large WE\) 与 3个\(\large PE\) 可组合出9个不同的复合新特征实例.
通过\(\large WE\) 与 \(\large PE\)的\(\large combinations\)极大丰富预训练数据,提高有效性。
![]()
![]()
![]()
![]()
![]()
- Transformer的\(\large PE\)是统计概率模型的一部分
3 数学上的“碰撞”特殊情况
- \(\large PE\)矩阵直接加上到其\(\large WE\)矩阵以嵌入位置信息, 不会破坏词向量本身的信息?
![]()
- 数学上的“碰撞”特殊情况:
![]()
- $\large WE $(词向量) 都是 "高维向量" 使"所有维度同时碰撞"的概率几乎为0.
![]()
- \(\large PE\)矩阵直接加上到其\(\large WE\)矩阵以嵌入位置信息, 不会破坏词向量本身的信息?







$\large PE $的代码实现

SciTech-BigDataAIML-LLM-Transformer Series-Positional Encoding: 位置编码: 统计模型(够多参数够高精度)+"够大数据"凝聚客观规律"预训练+深度NN(学习规律).的更多相关文章
- [NLP] 相对位置编码(二) Relative Positional Encodings - Transformer-XL
参考: 1. Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context https://arxiv.org/pdf ...
- 第五课第四周实验一:Embedding_plus_Positional_encoding 嵌入向量加入位置编码
目录 变压器预处理 包 1 - 位置编码 1.1 - 位置编码可视化 1.2 - 比较位置编码 1.2.1 - 相关性 1.2.2 - 欧几里得距离 2 - 语义嵌入 2.1 - 加载预训练嵌入 2. ...
- 【转载】BERT:用于语义理解的深度双向预训练转换器(Transformer)
BERT:用于语义理解的深度双向预训练转换器(Transformer) 鉴于最近BERT在人工智能领域特别火,但相关中文资料却很少,因此将BERT论文理论部分(1-3节)翻译成中文以方便大家后续研 ...
- [NLP] 相对位置编码(一) Relative Position Representatitons (RPR) - Transformer
对于Transformer模型的positional encoding,最初在Attention is all you need的文章中提出的是进行绝对位置编码,之后Shaw在2018年的文章中提出了 ...
- ICCV2021 | Vision Transformer中相对位置编码的反思与改进
前言 在计算机视觉中,相对位置编码的有效性还没有得到很好的研究,甚至仍然存在争议,本文分析了相对位置编码中的几个关键因素,提出了一种新的针对2D图像的相对位置编码方法,称为图像RPE(IRPE). ...
- 中文NER的那些事儿5. Transformer相对位置编码&TENER代码实现
这一章我们主要关注transformer在序列标注任务上的应用,作为2017年后最热的模型结构之一,在序列标注任务上原生transformer的表现并不尽如人意,效果比bilstm还要差不少,这背后有 ...
- 知识图谱顶会论文(KDD-2022) kgTransformer:复杂逻辑查询的预训练知识图谱Transformer
论文标题:Mask and Reason: Pre-Training Knowledge Graph Transformers for Complex Logical Queries 论文地址: ht ...
- 【译】深度双向Transformer预训练【BERT第一作者分享】
目录 NLP中的预训练 语境表示 语境表示相关研究 存在的问题 BERT的解决方案 任务一:Masked LM 任务二:预测下一句 BERT 输入表示 模型结构--Transformer编码器 Tra ...
- URL encoding(URL编码)
URL encoding(URL编码),也称作百分号编码(Percent-encoding),是指特定上下文的统一资源定位符(URL)编码机制UrlEncode:将字符串以URL编码返回值:字符串函数 ...
- 大数据与云计算的关系是什么,Hadoop又如何参与其中?Nosql在什么位置,与BI又有什么关系?
大数据与云计算的关系是什么,Hadoop又如何参与其中,Nosql在什么位置,与BI又有什么关系?以下这篇文字讲他们的关系讲的非常清楚. 在谈大数据的时候,首先谈到的就是大数据的4V特性,即类型复杂 ...
随机推荐
- 【代码】C语言|保留小数点后n位并四舍五入,便于处理运算和存储不善的浮点数
前言 有个人跟我说浮点数运算起来非常麻烦,总是算着算着丢失精度,导致计算结果取int的时候取不准.毕竟系统也没有自动根据这个数的精度四舍五入的功能. 比如int(2.999999999999999)= ...
- 【HUST】代数学|理想的分解习题
以下内容中,背景知识部分尽数由GPT生成,生成的方式是直接对问题进行提问,存在错误的小节我已经标注,不保证不存在其他错误. 习题部分是GPT生成后,我将看不懂的地方自己重写了一遍的结果.不保证完全正确 ...
- 信息资源管理文字题之“IT服务管理的核心流程和具体内容”
一.为了充分利用ERP信息系统资源,LX集团采用了各种先进的信息系统管理概念和方法,包括IT服务管理. 要求:说明IT服务管理流程包括那两大核心类别,分别说明他们个包含哪些具体流程 二.答案 答:两大 ...
- HarmonyOS NEXT开发实战教程—搜索页
今天忙里偷闲,分享一个搜索页实现过程,先上效果图: 界面部分比较简单,大体分为导航栏.历史搜索.猜你想搜和热搜榜几个部分,历史搜索采用用户首选项进行存储数据. 导航栏部分相关代码如下: Flex({d ...
- 【UEFI】DXE阶段从概念到代码
总述 DXE(Driver Execution Environment)阶段,是执行大部分系统初始化的阶段,也就是说是BIOS发挥作用,初始化整个主板的主战场.在这个阶段我们可以进行大量的驱动工作. ...
- GIM发布新版本了 (附rust CLI制作brew bottle流程)
GIM 发布新版本了!现在1.3.0版本可用了 https://github.com/davelet/git-intelligence-message/releases/tag/v1.3.0 .可以通 ...
- frp增加IP限制
核心设计理念 传统frp安全方案的不足 静态配置文件管理白名单IP,修改需要重启服务 分布式环境下多节点配置同步困难 缺乏实时阻断恶意IP的能力 Redis作为动态白名单存储的优势 实时生效:IP规则 ...
- Redis实战-缓存穿透、缓存雪崩、缓存击穿和缓存并发的区别和解决方案
正常处理流程 客户端请求正常的时候,先读缓存,如果数据命中,则返回缓存的值:否则,把从存储层中读取出来的数据缓存至缓存,同时返回客户端.但是,为了保证系统高可用和高性能,设计一个缓存系统时必须考虑 ...
- 2021NOI 省选训练赛day1T1 A. light
2021NOI 省选训练赛day1T1 A. light Problem 有一排\(n\)个灯,每个灯有一个颜色,用\(1\)到\(m\)表示.一开始所有灯都是关着的. 有\(q\)次操作,每次改变某 ...
- Fiddler破解钉钉禁止点赞 钉钉点赞一下转换1*10^7+个赞
破解钉钉禁止点赞 点一下1*10^7+个赞 说明:本文未经授权禁止转载 紧急upd 3.14号之后无法点超过一个赞,所以修改数据包时(unlock.html)的数字无法设置那么大,只能设置为1.当然, ...