论文解读《Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks》
发表时间:2019
期刊会议:IEEE Symposium on Security and Privacy (S&P)
论文单位:UC Santa Barbara
论文作者:Bolun Wang, Yuanshun Yao, Shawn Shan, Huiying Li, Bimal Viswanath, Haitao Zheng, Ben Y. Zhao
方向分类:Backdoor Attack
摘要
深度神经网络(DNN)缺乏透明度使其容易受到后门攻击,其中隐藏的关联或触发器会覆盖正常分类以产生意外结果。例如,如果输入中存在特定符号,带有后门的模型总是将一张脸识别为比尔·盖茨。后门可以无限期地保持隐藏,直到被输入激活,并且对许多安全或安全相关应用(例如,生物识别认证系统或自动驾驶汽车)带来严重的安全风险。
我们提出了第一个鲁棒和可推广的DNN后门攻击检测和缓解系统。我们的技术可以识别后门并重建可能的触发因素。我们通过输入过滤器、神经元修剪和遗忘来识别多种缓解技术。我们通过对各种DNNs的广泛实验证明了它们的功效,而不是先前工作中确定的两种后门注射方法。我们的技术也被证明对后门攻击的许多变体是稳健的。
背景
针对DNN的后门攻击

针对DNN的后门攻击的例证如上图所示。后门目标为标签4,触发图案为右下角白色方块。当注入后门时,训练集的一部分被修改以使触发器被冲压并且标签被修改为目标标签。用修改后的训练集训练后,模型将识别以触发器为目标标签的样本。同时,该模型仍然可以在没有触发的情况下识别任何样本的正确标签。

检测后门的关键直觉的简化说明如上图所示。上半图显示了一个干净的模型,其中需要更多的修改来移动B和C的样本跨越决策边界,以被错误分类到标签A中。下半图显示了受感染的模型,其中后门改变了决策边界并创建了靠近B和C的后门区域。这些后门区域减少了将B和C的样品错误分类到目标标签A中所需的修改量。触发器对于原始图片的扰动应该尽量小,避免被检测到,为了让我们更好理解,作者抽象的增加了一个Trigger Dimension维度。
防御假设
假设防御者可以访问训练好的DNN,以及一组正确标记的样本来测试模型的性能。防御者还可以访问计算资源以测试或修改DNN,例如GPU或基于GPU的云服务。
创新点
检测后门
我们希望对给定DNN是否被后门感染做出二元决策。如果被感染,我们还想知道后门攻击针对的是什么标签。

Tt表示触发器的大小,即触发器最大能产生多大的扰动。等式左边表示使任何输入被分类为Lt(一个感染的索引为t的标签)所需的最小扰动。等式右边表示使任何输入转换为未感染标签所需的扰动。作者检测后门的关键直觉是,在受感染的模型中,它需要比其他未受感染的标签更小的修改来导致错误分类到目标标签中。(很好理解,如果错误分类到未感染标签的扰动小于错误分类到感染标签的扰动,那么攻击者的触发器就设置的不合理了,或者说,攻击者是个脑残)
检测后门的具体步骤如下:
(1)对于给定的标签,我们将其视为定向后门攻击的潜在目标标签。我们设计了一个优化方案来找到将所有样本从其他标签错误分类到这个目标标签所需的“最小”触发器(这里的触发器也就是Reverse Engineering Triggers,具体实现细节请看下一小节)。在视觉域中,该触发器定义了导致错误分类的最小像素集合及其相关联的颜色强度。
(2)我们对模型中的每个输出标签重复步骤(1)。对于具有N个标签的模型,这会产生N个潜在的“触发器”。
(3)在计算N个潜在触发器之后,我们通过每个触发器候选具有的像素数来测量每个触发器的大小,即触发器正在替换多少像素。我们运行异常值检测算法(一种基于中值绝对偏差的简单技术)来检测任何触发候选是否明显小于其他候选。显著异常值代表真实触发器,与该触发器匹配的标签是后门攻击的目标标签。
识别后门
我们要识别后门的预期操作;更具体地说,我们希望对攻击使用的触发器进行逆向工程。
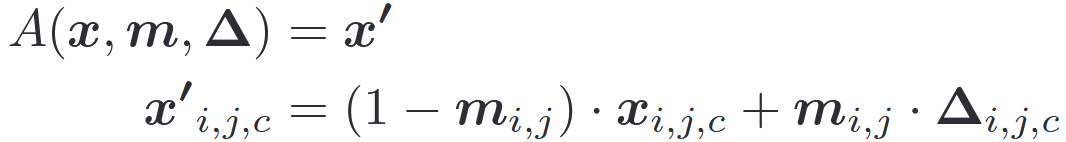
我们首先定义一个触发器注入的一般形式。A()表示对原始图像x施加触发的函数。Δ是触发模式,其是具有与输入图像相同维度(高度、宽度和颜色通道)的像素颜色强度的3D矩阵。m是称为掩码的2D矩阵,决定触发器可以覆盖原始图像的程度。这里,我们考虑2D遮罩(高度、宽度),其中相同的遮罩值应用于像素的所有颜色通道。掩码中的值范围从0到1。训练一个Reverse Engineering Triggers(逆向工程触发器)也就是训练Δ和m这两个参数。
当对于特定像素(i,j),当mi,j=1时,触发器完全覆盖原始颜色(x′i,j,c = xi,j,c),并且当mi,j=0时,原始颜色根本不被修改。先前的攻击仅使用二进制掩码值(0或1),因此适合这种通用形式。这种连续形式的掩模还使掩模可微,并帮助其集成到优化目标中。

优化有两个目标。对于给定的待分析目标标签(yt),第一个目标是找到将干净图像错误分类为yt的触发器(m,Δ)。第二个目标是找到“简洁”触发器,即仅修改图像有限部分的触发器。我们通过掩模m的L1范数来测量触发器的大小。总之,我们通过优化两个目标的加权和,将其公式化为多目标优化任务。最终公式如上图所示。
f()是DNN的预测函数。l()是衡量分类中误差的损失函数,在我们的实验中是交叉熵。λ是第二个目标的权重。较小的λ赋予控制触发器大小的权重较低,但可能产生具有较高成功率的错误分类。在我们的实验中,我们在优化过程中动态调整λ,以确保>99%的干净图像可以成功错误分类。我们使用Adam优化器来解决上述优化。
X是我们用来解决优化任务的干净图像集。它来自用户有权访问的干净数据集。在我们的实验中,我们使用训练集并将其输入到优化过程中,直到收敛。或者,用户也可以对测试集的一小部分进行采样。

上图比较了四种BadNets模型中的原始触发器和反向触发器(m,Δ)。我们发现反向触发器与原始触发器大致相似。在所有情况下,反向触发器都显示在与原始触发器相同的位置。

但是,反向触发器与原始触发器之间仍存在微小差异。如上图所示。在MNIST和PubFig中,反向触发比原始触发略小,缺少几个像素。在使用彩色图像的模型中,反向触发器具有许多非白色像素。这些差异可归因于两个原因。首先,当训练模型识别触发器时,它可能无法学习触发器的确切形状和颜色。这意味着模型中触发后门最“有效”的方式不是原来的注入触发器,而是一种稍微不同的形式。其次,我们的优化目标是惩罚更大的触发器。因此触发器中的一些冗余像素将在优化过程中被修剪,从而导致更小的触发器。结合起来,它导致我们的优化过程找到了与原始触发器相比更“紧凑”的后门触发器形式。
缓解后门
我们希望使后门无效。我们可以使用两种互补的方法来解决这个问题。首先,我们希望构建一个主动过滤器,检测并阻止攻击者提交的任何传入的对抗性输入。其次,我们希望“修补“DNN以移除后门,而不影响其对正常输入的分类性能。
Filter for Detecting Adversarial Inputs
我们为对抗性输入创建一个过滤器,识别并拒绝任何带有触发器的输入,让我们有时间修补模型。根据应用,这种方法还可以用于将“安全”输出标签分配给对抗性输入而不会被拒绝。
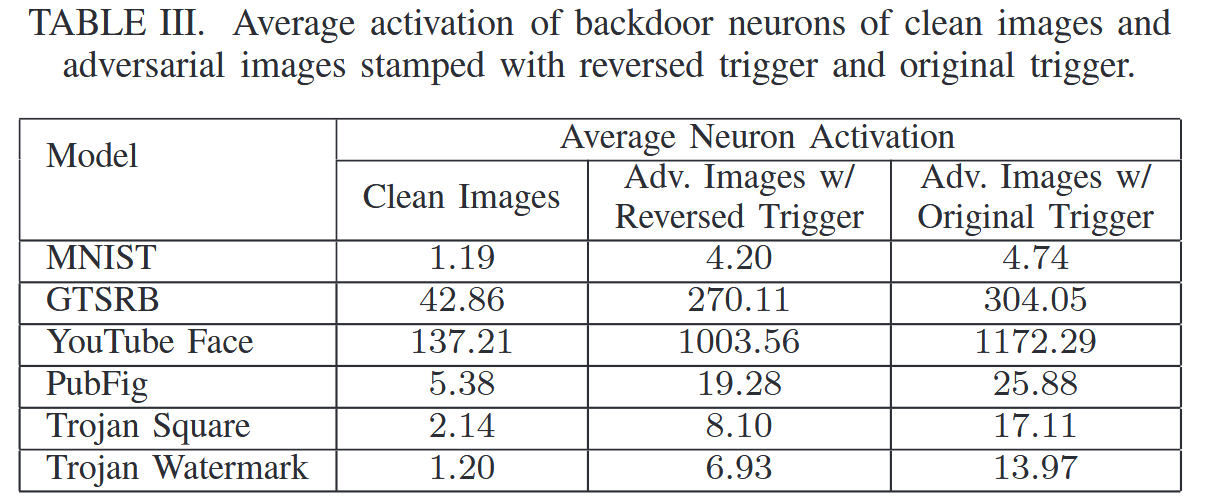
我们进一步研究了具有反向触发和原始触发的输入在内部层是否具有相似的神经元激活。具体来说,我们检查倒数第二层的神经元,因为这一层编码输入中的相关代表性模式。我们通过以下方式识别与后门最相关的神经元,提供干净和对抗性的图像,并观察目标层(倒数第二层)神经元激活的差异。我们通过测量神经元激活的差异来对神经元进行排序(作者这里没有描述清楚,我以我的理解解释一下这里怎么进行排序。因为模型都是相同的受感染模型,只是输入不同。作者首先比较了clean image和original trigger的输入,找到神经元激活差异最大的神经元位置,然后再测reversed trigger的输入,计算对应位置的神经元激活数量)。根据经验,我们发现前1%的神经元足以启用后门,即如果我们保留前1%的神经元并屏蔽其余的(设置为零),攻击仍然有效。
如果被原始触发器激活的前 1%的神经元也被反向设计的触发器激活(不是干净输入),我们就认为神经元激活是 “相似的”。表III显示了当喂食1,000个随机选择的干净和对抗性图像时,前1%神经元的平均神经元激活。
神经元激活是捕捉原始触发器和逆向工程触发器之间相似性的更好方式。因此,我们基于反向触发的神经元激活曲线来构建滤波器。这被测量为倒数第二层中前1%神经元的平均神经元激活。给定一些输入,滤波器将潜在的对抗性输入识别为激活曲线高于某个阈值的输入。可以使用对干净输入(已知没有触发器的输入)的测试来校准激活阈值。
Patching DNN via Neuron Pruning
直觉是使用反向触发器来帮助识别DNN中的后门相关组件,例如神经元,并移除它们。我们建议从DNN中修剪出后门相关的神经元,即在推理过程中将这些神经元的输出值设置为0。我们再次以干净输入和对抗性输入之间的差异为目标(使用反向触发)。我们再次瞄准倒数第二层,并按照最高等级优先的顺序修剪神经元(即,优先考虑那些在干净输入和对抗性输入之间显示最大激活差距的神经元)。为了最小化对干净输入的分类准确性的影响,当修剪后的模型不再响应反向触发时,我们停止修剪。
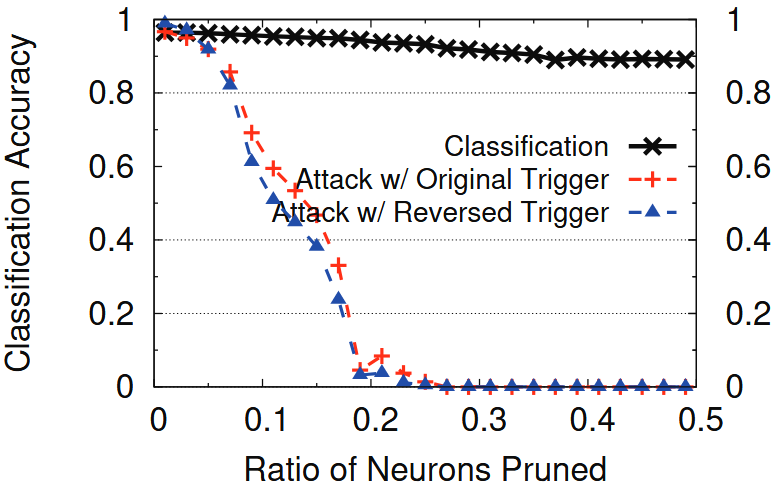
上图显示了在GTSRB中修剪不同比例神经元时的分类准确率和攻击成功率。修剪30%的神经元将攻击成功率降低到接近0%。注意,反向触发器的攻击成功率遵循与原始触发器相似的趋势,因此用作近似原始触发器的防御有效性的良好信号。同时,分类精度仅降低了5.06%。当然,防御者可以通过权衡攻击成功率的降低来实现更小的分类准确率下降(遵循上图中的曲线)。
Patching DNNs via Unlearning
训练DNN忘记原始触发器。我们可以使用反向触发器来训练受感染的DNN识别正确的标签,即使触发器存在。与神经元修剪相比,忘却允许模型通过训练来决定哪些权重(不是神经元)是有问题的,应该更新。

表IV比较了训练前后的攻击成功率和分类准确率。在所有模型中,我们设法将攻击成功率降低到<6.70%,而不会显著牺牲分类准确性。分类精度降低最大的是GTSRB,仅为3.6%。有趣的一点是,在一些模型中,尤其是木马攻击模型,打补丁后分类准确率有提升。请注意,当注入后门时,特洛伊木马攻击模型的分类准确性会下降。原始未感染的特洛伊木马攻击模型的分类准确率为77.2%(表IV中未显示),现在在修补后门时提高了这一准确率。
我们比较了这种遗忘与两种变体的功效。首先,我们考虑针对相同的训练样本进行再训练,但是对20%应用原始触发器而不是逆向工程触发器。如表IV所示,使用原始触发器的忘却在相似的分类精度下实现了略低的攻击者成功率。因此,用我们的反向触发器忘却是用原始触发器忘却的一个很好的近似。其次,我们比较了仅使用干净的训练数据(没有额外的触发器)的忘却。表IV最后一列的结果显示,忘却对于所有BadNets模型都是无效的(攻击成功率仍然很高:>93.37%),但是对于特洛伊木马攻击模型非常有效,对于特洛伊木马广场和特洛伊木马水印的攻击成功率分别下降到10.91%和0%。这似乎表明,特洛伊木马攻击模型对特定神经元的高度有针对性的重新调整,对遗忘更加敏感。有助于重置一些关键神经元的干净输入可以阻止攻击。相比之下,BadNets通过使用中毒数据集更新所有层来注入后门,并且似乎需要更多的工作来重新训练和减轻后门。
论文解读《Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks》的更多相关文章
- 《Population Based Training of Neural Networks》论文解读
很早之前看到这篇文章的时候,觉得这篇文章的思想很朴素,没有让人眼前一亮的东西就没有太在意.之后读到很多Multi-Agent或者并行训练的文章,都会提到这个算法,比如第一视角多人游戏(Quake ...
- ImageNet Classification with Deep Convolutional Neural Networks 论文解读
这个论文应该算是把深度学习应用到图片识别(ILSVRC,ImageNet large-scale Visual Recognition Challenge)上的具有重大意义的一篇文章.因为在之前,人们 ...
- 《Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks》论文笔记
论文题目<Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Ne ...
- Quantization aware training 量化背后的技术——Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
1,概述 模型量化属于模型压缩的范畴,模型压缩的目的旨在降低模型的内存大小,加速模型的推断速度(除了压缩之外,一些模型推断框架也可以通过内存,io,计算等优化来加速推断). 常见的模型压缩算法有:量化 ...
- Training Deep Neural Networks
http://handong1587.github.io/deep_learning/2015/10/09/training-dnn.html //转载于 Training Deep Neural ...
- Training (deep) Neural Networks Part: 1
Training (deep) Neural Networks Part: 1 Nowadays training deep learning models have become extremely ...
- [CVPR2015] Is object localization for free? – Weakly-supervised learning with convolutional neural networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333 } p. ...
- Training spiking neural networks for reinforcement learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 原文链接:https://arxiv.org/pdf/2005.05941.pdf Contents: Abstract Introduc ...
- CVPR 2018paper: DeepDefense: Training Deep Neural Networks with Improved Robustness第一讲
前言:好久不见了,最近一直瞎忙活,博客好久都没有更新了,表示道歉.希望大家在新的一年中工作顺利,学业进步,共勉! 今天我们介绍深度神经网络的缺点:无论模型有多深,无论是卷积还是RNN,都有的问题:以图 ...
- 论文翻译:BinaryConnect: Training Deep Neural Networks with binary weights during propagations
目录 摘要 1.引言 2.BinaryConnect 2.1 +1 or -1 2.2确定性与随机性二值化 2.3 Propagations vs updates 2.4 Clipping 2.5 A ...
随机推荐
- Zabbix-(1)安装
环境: VMware Workstation Pro 16.0 版本 系统 Centos7 内存 2G 处理器 1G 硬盘 20G 网络适配器 NAT 服务器地址:192.168.220.40 1.安 ...
- c++ 命名的强制类型转换
显式转换:显式将一种类型转换为另一种类型. References: C++中的显示数据类型转换 与命名的强制类型转换相比,旧式的强制类型转换从表现形式上来说不那么清晰明了,容易被看漏,所以一旦转换过程 ...
- Angular 18+ 高级教程 – Prettier, ESLint, Stylelint
前言 不熟悉 Prettier, ESLint, Stylelint 的朋友可以先看这篇 工具 – Prettier.ESLint.Stylelint. 首先,Angular 没有 built-in ...
- Angular 18+ 高级教程 – Angular Configuration (angular.json)
前言 记入一些基本的配置. Setup IP Address.SSL.Self-signed Certificate 如果你对 IP Address.SSL.Self-signed Certifica ...
- Angular 18+ 高级教程 – Signals
前言 首先,我必须先说明清楚.Signal 目前不是 Angular 的必备知识. 你的项目不使用 Signal 也不会少了条腿,断了胳膊. Angular 官方维护的 UI 组件库 Angular ...
- Time Zone, Leap Year, Date Format, Epoch Time 时区, 闰年, 日期格式
前言 以前有写过一篇了, 但很乱, 这篇就作为它的整理版吧. Leap Year 闰年 闰年是指那些有 366 天, 二月份有 29号 的年份. 比如 2020年 有 2月29日, 所以 2020 就 ...
- Nuke导出视频缺失 H.246格式 的解决办法
同事在使用Nuke导出视频时报错,报错提示:缺失 H.246格式 后来经过我的研究发现,Quicktime Player 在标准安装时,默认不关联一些格式(具体是哪些格式不清楚) Quicktime ...
- .NEET跨平台绘图基础库--SkiaSharp
SkiaSharp 是一个跨平台的 2D 图形 API,用于 .NET 平台,基于 Google 的 Skia 图形库.它提供了全面的 2D API,可以在移动.服务器和桌面模型上渲染图像.SkiaS ...
- Redis 发布订阅模式
概述 Redis 的发布/订阅是一种消息通信模式:发送者(Pub)向频道(Channel)发送消息,订阅者(Sub)接收频道上的消息.Redis 客户端可以订阅任意数量的频道,发送者也可以向任意频道发 ...
- 如何解决token过期问题 ?
首先 token 过期会导致请求不到数据 , 就不能准确渲染页面 ,此时的错误配置项的token是过期的,只要更新了token 拿着原先的配置项重新请求数据即可 :但是如果更新token的时候请求错误 ...