Discriminative Learning of Deep Convolutional Feature Point Descriptors 论文阅读笔记
介绍
该文提出一种基于深度学习的特征描述方法,并且对尺度变化、图像旋转、透射变换、非刚性变形、光照变化等具有很好的鲁棒性。该算法的整体思想并不复杂,使用孪生网络从图块中提取特征信息(得到一个128维的特征向量),并且使用L2距离来描述特征之间的差异,目标是让匹配图块特征之间的距离缩短,让不匹配图块特征之间的距离增大。
数据集及模型结构
数据集
论文使用的是一个叫做MVS的建筑物数据集,包含了1.5M张\(64 \times 64\)张的灰度图来自500K个3D points。
网络的结构:
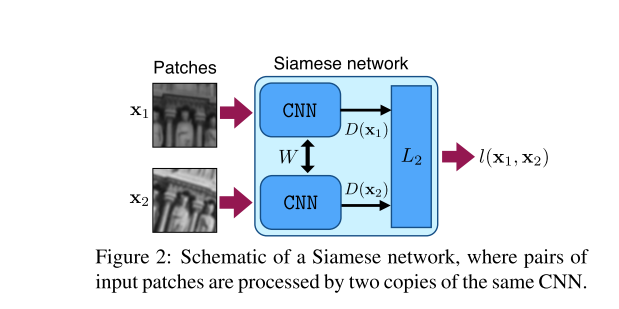
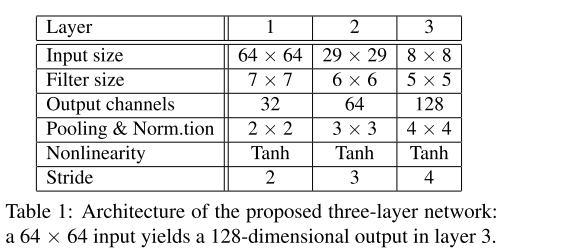
3.损失函数:
\left\|D\left(\mathbf{x}_{1}\right)-D\left(\mathbf{x}_{2}\right)\right\|_{2}, & p_{1}=p_{2} \\
\max \left(0, C-\left\|D\left(\mathbf{x}_{1}\right)-D\left(\mathbf{x}_{2}\right)\right\|_{2}\right), & p_{1} \neq p_{2}
\end{array}\right.
\]
解释一下,C是一个最小距离阈值;两个图像块$ x_1, x_2$,如果它们来自同一个3D point \(pi\),则使用(1)的上半部分计算损失函数,否则使用下半部分计算损失函数。
- Mining
论文作者提出了一个训练模型的创新方法:

随着训练的进行,随机选择的负向样本之间的距离很容易就超过阈值C,使得损失变成0,无法有效的对网络进行训练了。也就是说,随机选择的负向样本太简单了,他们本身之间的距离就很大,无法有效的训练网络。因此作者希望能够从数据集中寻找到“困难”的样本,什么才算是困难样本呢,对于负向样本而言,就是他们之间的距离很小,非常相似,但却不属于一个3D点;对于正向样本而言,就是他们属于同一个3D点,但特征之间的距离却很大。这样的样本对模型训练有很好的促进作用。为了实现这个目标,作者先随机采样了一个包含\(s_n\) 个点的负样本集,然后经过一次正向的运算(网络正向传播)并计算损失,然后仅保留其中\(s_n^H\)个点构成的困难样本子集,并将这部分的损失反向传播回去,对网络参数进行训练。对于正向样本也采用同样的策略,来挖掘困难样本。
结果:
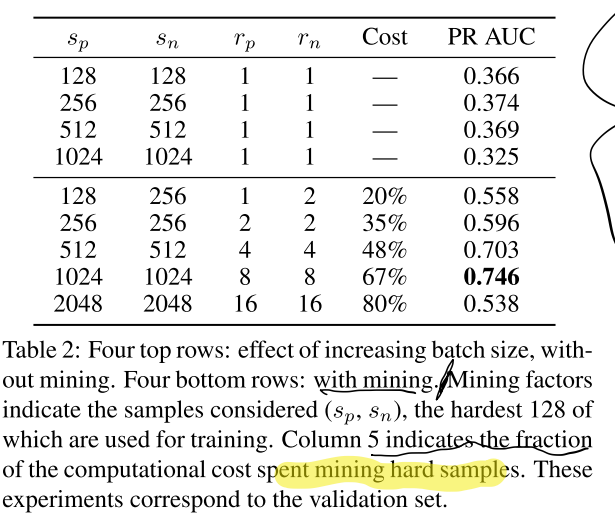
Last
 |
 |
这个PR curves应该与是某个指标有关,以后遇到了再查阅。 |
|---|
Discriminative Learning of Deep Convolutional Feature Point Descriptors 论文阅读笔记的更多相关文章
- Learning local feature descriptors with triplets and shallow convolutional neural networks 论文阅读笔记
题目翻译:学习 local feature descriptors 使用 triplets 还有浅的卷积神经网络.读罢此文,只觉收获满满,同时另外印象最深的也是一个浅(文章中会提及)字. 1 Cont ...
- 论文笔记之:UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS ICLR 2 ...
- 论文学习 :Learning a Deep Convolutional Network for Image Super-Resolution 2014
(Learning a Deep Convolutional Network for Image Super-Resolution, ECCV2014) 摘要:我们提出了一种单图像超分辨率的深度学习方 ...
- [论文阅读笔记] node2vec Scalable Feature Learning for Networks
[论文阅读笔记] node2vec:Scalable Feature Learning for Networks 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 由于DeepWal ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- 论文阅读笔记(二十一)【CVPR2017】:Deep Spatial-Temporal Fusion Network for Video-Based Person Re-Identification
Introduction (1)Motivation: 当前CNN无法提取图像序列的关系特征:RNN较为忽视视频序列前期的帧信息,也缺乏对于步态等具体信息的提取:Siamese损失和Triplet损失 ...
- [论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks
[论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks 本文结构 解决问题 主要贡献 算法 ...
- [论文阅读笔记] Structural Deep Network Embedding
[论文阅读笔记] Structural Deep Network Embedding 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 现有的表示学习方法大多采用浅层模型,这可能不能 ...
- [论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks
[论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问 ...
随机推荐
- 【LeetCode】72. Edit Distance 编辑距离(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 递归 记忆化搜索 动态规划 日期 题目地址:http ...
- Boost的反射库PFR
目录 目录 简介 使用方法 限制 总结 简介 Boost.PFR是一个Boost 1.75版本出的C++14的基础反射库,其使用非常简单,非常便捷,但是适用性也比较差,有很多的地方无法使用,适合比较简 ...
- <数据结构>并查集与树
作用 查:给定一个元素,查询它在哪个集合内 并:合并两个元素所在的集合 实现思路 对应关系 元素-->结点 集合-->树 多个集合-->森林 用树的根节点作为不同树的标志 合并时只需 ...
- docker学习:docker安装
Centos7 安装docker 下载安装 yum install docker-ce 启动docker systemctl start docker 创建并编写镜像加速文件 vim /etc/doc ...
- 【Python+Django+Pytest】数据库异常pymysql.err.InterfaceError: (0, '') 解决方案
问题背景: 接口自动化测试平台,在执行测试案例之外,还需要做以下五件事情(或步骤): 1.查询用户在数据准备中预置的测试套件层数据初始化相关sql (setUp_class方法中) 2.查询用户在数 ...
- 初识python: 字符串常用操作
直接上代码示例: #!/user/bin env python # author:Simple-Sir # time:20180914 # 字符串常用操作 name = 'lzh lyh' print ...
- Tomcat8/9的catalina.out中文乱码问题解决
OS: Red Hat Enterprise Linux Server release 7.8 (Maipo) Tomcat: 9 中文显示为???问号 在$CATALINA_HOME/conf下的l ...
- js监听网页页面滑动滚动事件,实现导航栏自动显示或隐藏
/** * 页面滑动滚动事件 * @param e *///0为隐藏,1为显示var s = 1;function scrollFunc(e) { // e存在就用e不存在就用windon.event ...
- centos7 修改网卡信息
修改网卡配置文件 vim /etc/sysconfig/network-scripts/ifcfg-eth0 有一些不是eth0 也可能是ens33 修改完成后使用下面命令进行重启 systemctl ...
- Java实现单词统计
原文链接: https://www.toutiao.com/i6764296608705151496/ 单词统计的是统计一个文件中单词出现的次数,比如下面的数据源 其中,最终出现的次数结果应该是下面的 ...