Apache Hudi集成Spark SQL抢先体验
Apache Hudi集成Spark SQL抢先体验
1. 摘要
社区小伙伴一直期待的Hudi整合Spark SQL的PR正在积极Review中并已经快接近尾声,Hudi集成Spark SQL预计会在下个版本正式发布,在集成Spark SQL后,会极大方便用户对Hudi表的DDL/DML操作,下面就来看看如何使用Spark SQL操作Hudi表。
2. 环境准备
首先需要将PR拉取到本地打包,生成SPARK_BUNDLE_JAR(hudi-spark-bundle_2.11-0.9.0-SNAPSHOT.jar)包
2.1 启动spark-sql
在配置完spark环境后可通过如下命令启动spark-sql
spark-sql --jars $PATH_TO_SPARK_BUNDLE_JAR --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' --conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
2.2 设置并发度
由于Hudi默认upsert/insert/delete的并发度是1500,对于演示的小规模数据集可设置更小的并发度。
set hoodie.upsert.shuffle.parallelism = 1;
set hoodie.insert.shuffle.parallelism = 1;
set hoodie.delete.shuffle.parallelism = 1;
同时设置不同步Hudi表元数据
set hoodie.datasource.meta.sync.enable=false;
3. Create Table
使用如下SQL创建表
create table test_hudi_table (
id int,
name string,
price double,
ts long,
dt string
) using hudi
partitioned by (dt)
options (
primaryKey = 'id',
type = 'mor'
)
location 'file:///tmp/test_hudi_table'
说明:表类型为MOR,主键为id,分区字段为dt,合并字段默认为ts。
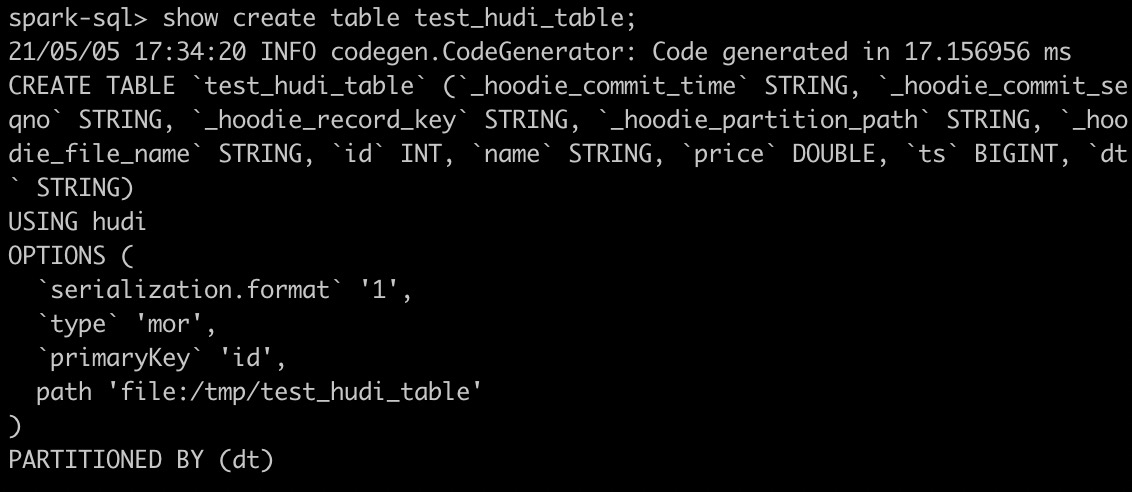
创建Hudi表后查看创建的Hudi表
show create table test_hudi_table
4. Insert Into
4.1 Insert
使用如下SQL插入一条记录
insert into test_hudi_table select 1 as id, 'hudi' as name, 10 as price, 1000 as ts, '2021-05-05' as dt
insert完成后查看Hudi表本地目录结构,生成的元数据、分区和数据与Spark Datasource写入均相同。

4.2 Select
使用如下SQL查询Hudi表数据
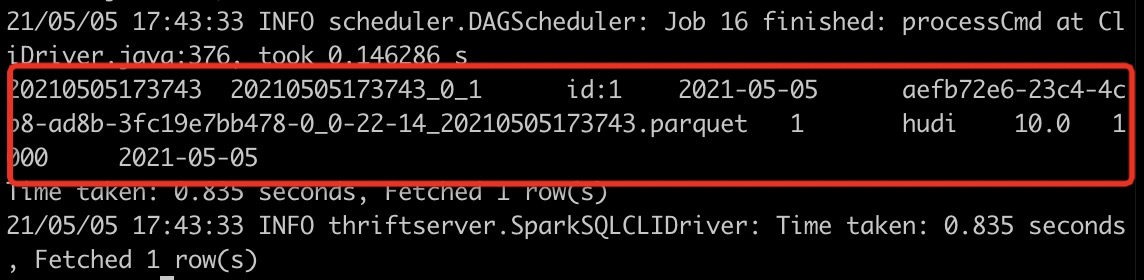
select * from test_hudi_table
查询结果如下
5. Update
5.1 Update
使用如下SQL将id为1的price字段值变更为20
update test_hudi_table set price = 20.0 where id = 1
5.2 Select
再次查询Hudi表数据
select * from test_hudi_table
查询结果如下,可以看到price已经变成了20.0

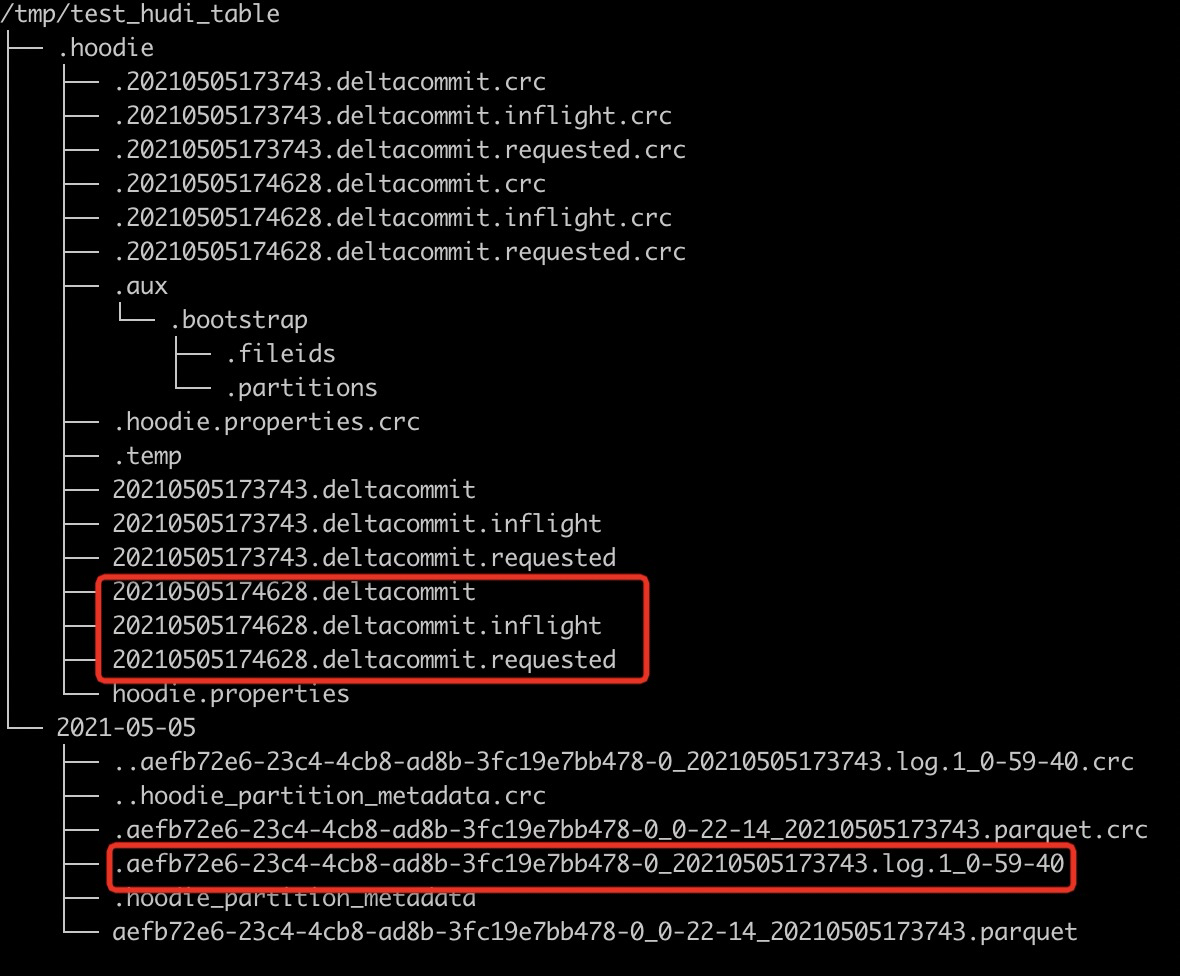
查看Hudi表的本地目录结构如下,可以看到在update之后又生成了一个deltacommit,同时生成了一个增量log文件。
6. Delete
6.1 Delete
使用如下SQL将id=1的记录删除
delete from test_hudi_table where id = 1
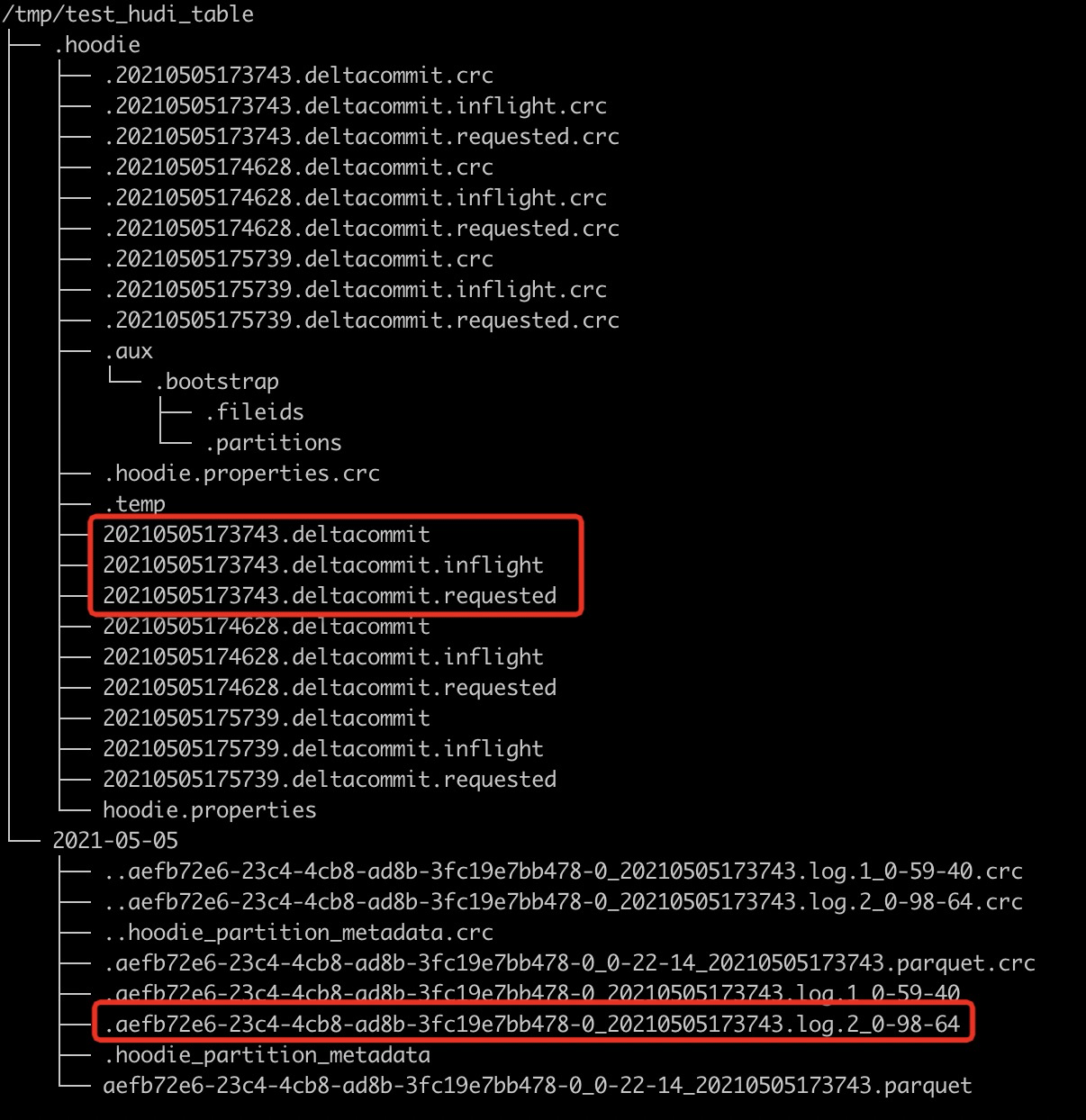
查看Hudi表的本地目录结构如下,可以看到delete之后又生成了一个deltacommit,同时生成了一个增量log文件。
6.2 Select
再次查询Hudi表
select * from test_hudi_table;
查询结果如下,可以看到已经查询不到任何数据了,表明Hudi表中已经不存在任何记录了。

7. Merge Into
7.1 Merge Into Insert
使用如下SQL向test_hudi_table插入数据
merge into test_hudi_table as t0
using (
select 1 as id, 'a1' as name, 10 as price, 1000 as ts, '2021-03-21' as dt
) as s0
on t0.id = s0.id
when not matched and s0.id % 2 = 1 then insert *
7.2 Select
查询Hudi表数据
select * from test_hudi_table
查询结果如下,可以看到Hudi表中存在一条记录
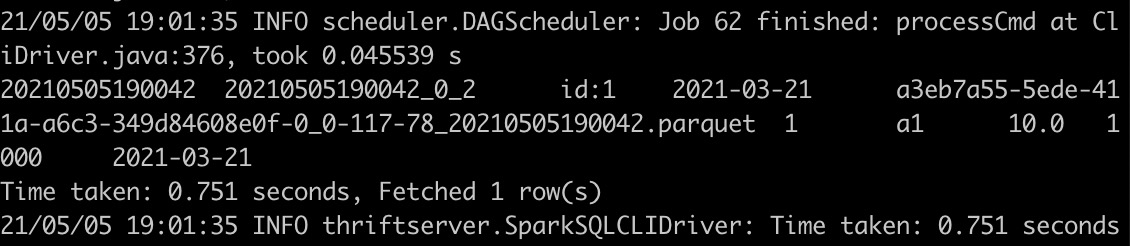
7.4 Merge Into Update
使用如下SQL更新数据
merge into test_hudi_table as t0
using (
select 1 as id, 'a1' as name, 12 as price, 1001 as ts, '2021-03-21' as dt
) as s0
on t0.id = s0.id
when matched and s0.id % 2 = 1 then update set *
7.5 Select
查询Hudi表
select * from test_hudi_table
查询结果如下,可以看到Hudi表中的分区已经更新了

7.6 Merge Into Delete
使用如下SQL删除数据
merge into test_hudi_table t0
using (
select 1 as s_id, 'a2' as s_name, 15 as s_price, 1001 as s_ts, '2021-03-21' as dt
) s0
on t0.id = s0.s_id
when matched and s_ts = 1001 then delete
查询结果如下,可以看到Hudi表中已经没有数据了

8. 删除表
使用如下命令删除Hudi表
drop table test_hudi_table;
使用show tables查看表是否存在
show tables;
可以看到已经没有表了

9. 总结
通过上面示例简单展示了通过Spark SQL Insert/Update/Delete Hudi表数据,通过SQL方式可以非常方便地操作Hudi表,降低了使用Hudi的门槛。另外Hudi集成Spark SQL工作将继续完善语法,尽量对标Snowflake和BigQuery的语法,如插入多张表(INSERT ALL WHEN condition1 INTO t1 WHEN condition2 into t2),变更Schema以及CALL Cleaner、CALL Clustering等Hudi表服务。
Apache Hudi集成Spark SQL抢先体验的更多相关文章
- Apache Hudi集成Apache Zeppelin实战
1. 简介 Apache Zeppelin 是一个提供交互数据分析且基于Web的笔记本.方便你做出可数据驱动的.可交互且可协作的精美文档,并且支持多种语言,包括 Scala(使用 Apache Spa ...
- 生态 | Apache Hudi集成Alluxio实践
原文链接:https://mp.weixin.qq.com/s/sT2-KK23tvPY2oziEH11Kw 1. 什么是Alluxio Alluxio为数据驱动型应用和存储系统构建了桥梁, 将数据从 ...
- Spark源码系列(九)Spark SQL初体验之解析过程详解
好久没更新博客了,之前学了一些R语言和机器学习的内容,做了一些笔记,之后也会放到博客上面来给大家共享.一个月前就打算更新Spark Sql的内容了,因为一些别的事情耽误了,今天就简单写点,Spark1 ...
- 重磅!Vertica集成Apache Hudi指南
1. 摘要 本文演示了使用外部表集成 Vertica 和 Apache Hudi. 在演示中我们使用 Spark 上的 Apache Hudi 将数据摄取到 S3 中,并使用 Vertica 外部表访 ...
- 恭喜!Apache Hudi社区新晋多位Committer
1. 介绍 经过Apache Hudi项目委员会讨论及投票,向Udit Mehrotra.Gary Li.Raymond Xu.Pratyaksh Sharma 4人发出Committer邀请,4人均 ...
- 详解 Apache Hudi Schema Evolution(模式演进)
Schema Evolution(模式演进)允许用户轻松更改 Hudi 表的当前模式,以适应随时间变化的数据. 从 0.11.0 版本开始,支持 Spark SQL(spark3.1.x 和 spar ...
- 使用 Apache Hudi 实现 SCD-2(渐变维度)
数据是当今分析世界的宝贵资产. 在向最终用户提供数据时,跟踪数据在一段时间内的变化非常重要. 渐变维度 (SCD) 是随时间推移存储和管理当前和历史数据的维度. 在 SCD 的类型中,我们将特别关注类 ...
- Spark SQL 之 Migration Guide
Spark SQL 之 Migration Guide 支持的Hive功能 转载请注明出处:http://www.cnblogs.com/BYRans/ Migration Guide 与Hive的兼 ...
- Spark SQL 官方文档-中文翻译
Spark SQL 官方文档-中文翻译 Spark版本:Spark 1.5.2 转载请注明出处:http://www.cnblogs.com/BYRans/ 1 概述(Overview) 2 Data ...
随机推荐
- concurrentHashMap的put方法详解
本文主要介绍ConcurrentHashMap的put操作如果有错误的地方欢迎大家指出. 1.ConcurrentHashMap的put操作 ConcurrentHashMap的put操作主要有3种方 ...
- 力扣 - 347. 前 K 个高频元素
目录 题目 思路1(哈希表与排序) 代码 复杂度分析 思路2(建堆) 代码 复杂度分析 题目 347. 前 K 个高频元素 思路1(哈希表与排序) 先用哈希表记录所有的值出现的次数 然后将按照出现的次 ...
- SyntaxError :invalid syntax Python常见错误
1.忘记在 if , elif , else , for , while , class ,def 声明末尾添加 ":" 2.使用 = 而不是 ==,= 是赋值操作符而 == 是等 ...
- UnboundLocalError: local variable 'foo' referenced before assignment Python常见错误
在定义局部变量前在函数中使用局部变量(此时有与局部变量同名的全局变量存在) 在函数中使用局部变来那个而同时又存在同名全局变量时是很复杂的, 使用规则:如果在函数中定义了任何东西,如果它只是在函数中使用 ...
- 高精度减法(c++)
高精度减法 每当要进行精度较高的运算时,就要用到高精度. 下图是各个类型的数值范围: 如果想不起各个类型占多少字节,可以采用下面的方法: printf("%d %d",sizeof ...
- [Fundamental of Power Electronics]-PART I-4.开关实现-0 序
4 开关实现 在前面的章节中我们已经看到,可以使用晶体管,二极管来作为Buck,Boost和其他一些DC-DC变换器的开关元件.也许有人会想为什么会这样,以及通常如何实现半导体的开关.这些都是值得被提 ...
- MRCTF My secret
My secret 知识点:wireshark基本操作,shadowsocks3.0源码利用,拼图(os脚本编写能力), 根据这里的信息可以知道,tcp所传输的源数据是在target address后 ...
- Java内置内存分析
Java内存分析 package com.chao.reflection; public class Test05 { public static void main(String[] args) { ...
- Java(133-151)【String类、static、Arrays类、Math类】
1.字符串概述和特点 string在lang包里面,因此可以直接使用 字符串的内容不可变 2.字符串的构造方法和直接创建 三种构造方法 package cn.itcast.day08.demo01; ...
- Day13_74_守护线程
守护线程 线程分为 用户线程 和 守护线程. setDeamon(boolean) 方法 :将该线程标记为守护线程或者用户线程. 线程对象.setDaemon(true); //false 表示用户线 ...