Apache Hudi集成Apache Zeppelin实战
1. 简介
Apache Zeppelin 是一个提供交互数据分析且基于Web的笔记本。方便你做出可数据驱动的、可交互且可协作的精美文档,并且支持多种语言,包括 Scala(使用 Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、Shell等等。当前Hive与SparkSQL已经支持查询Hudi的读优化视图和实时视图。所以理论上Zeppelin的notebook也应当拥有这样的查询能力。
2.实现效果
2.1 Hive
2.1.1 读优化视图
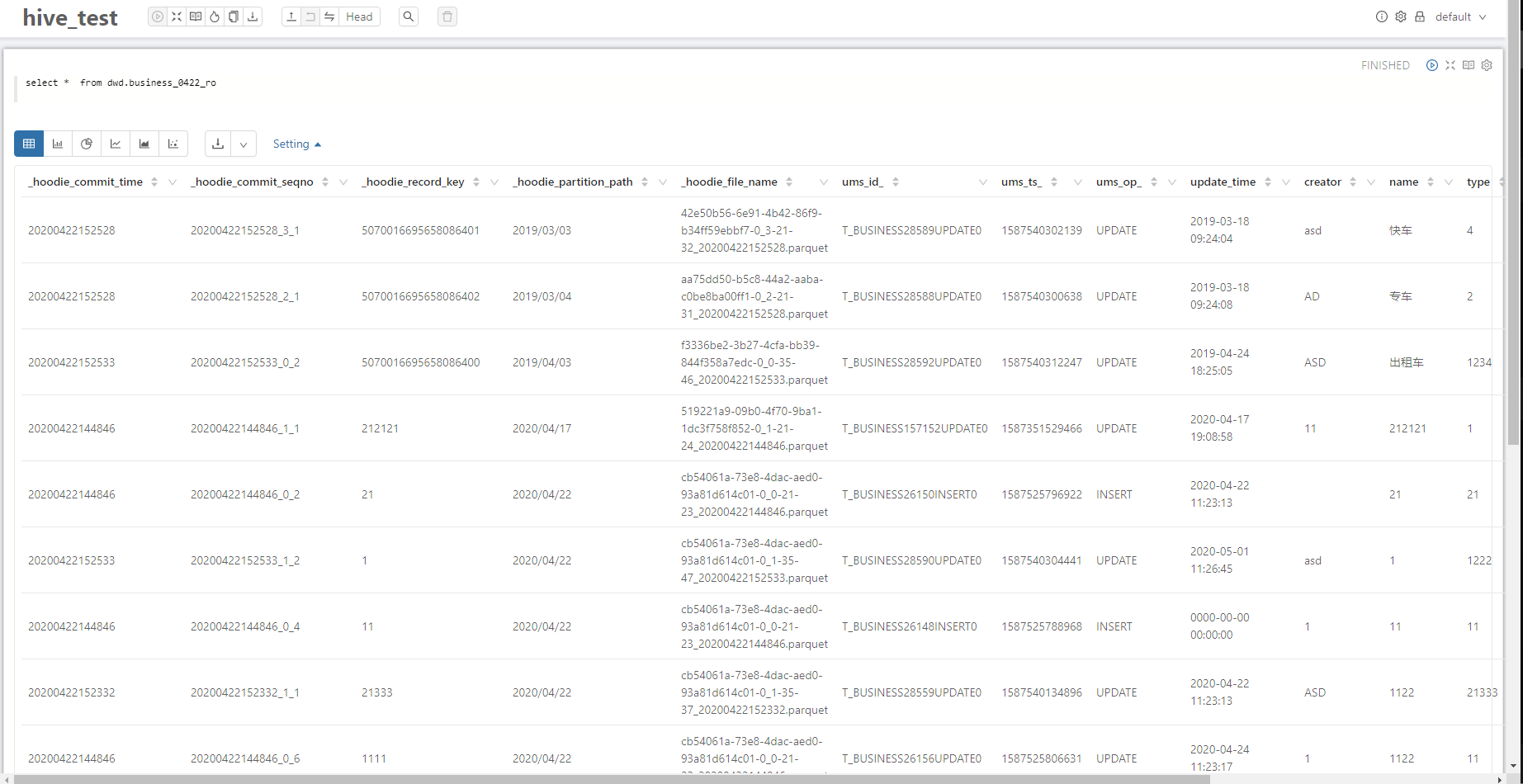
2.1.2 实时视图
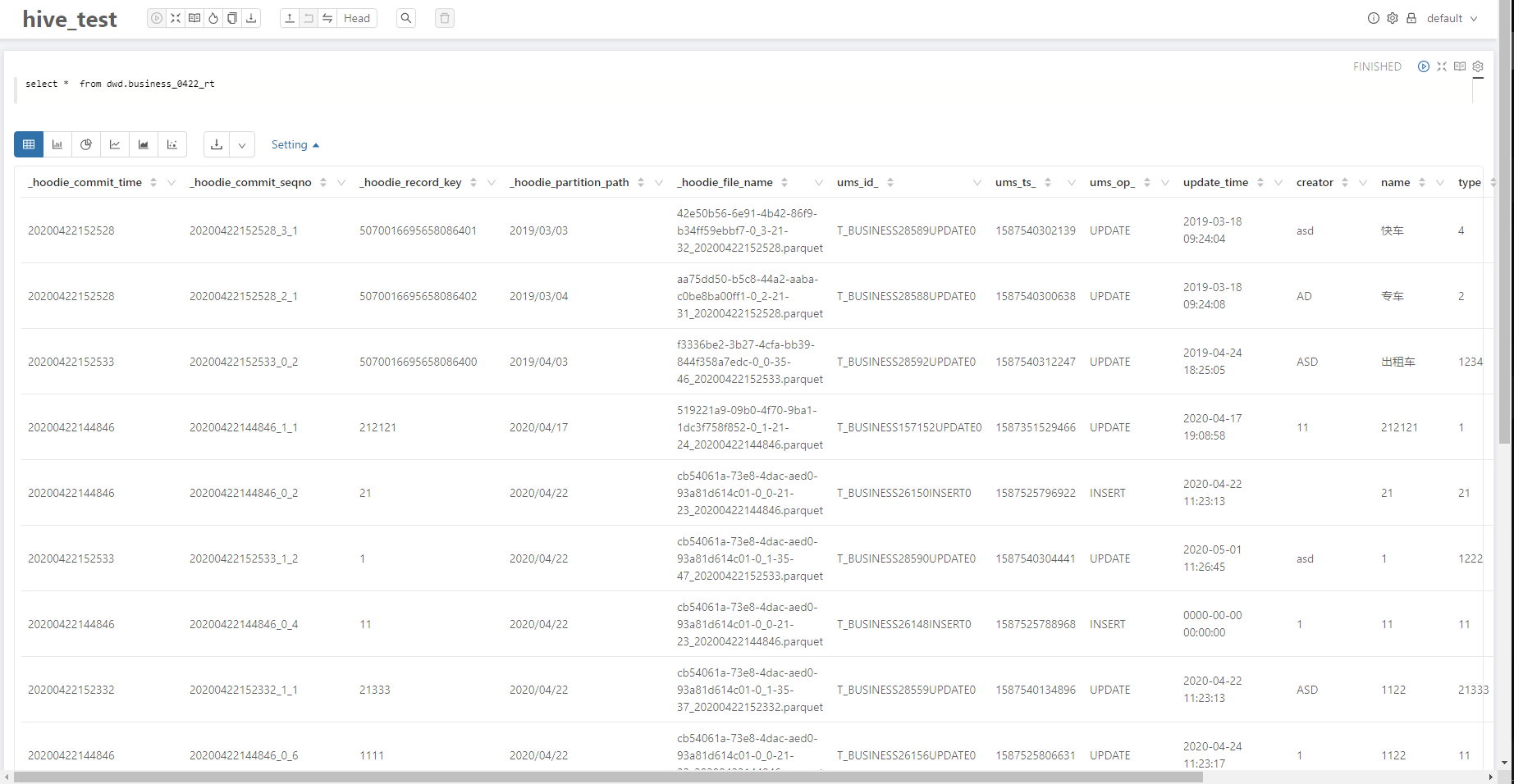
2.2 Spark SQL
2.2.1 读优化视图
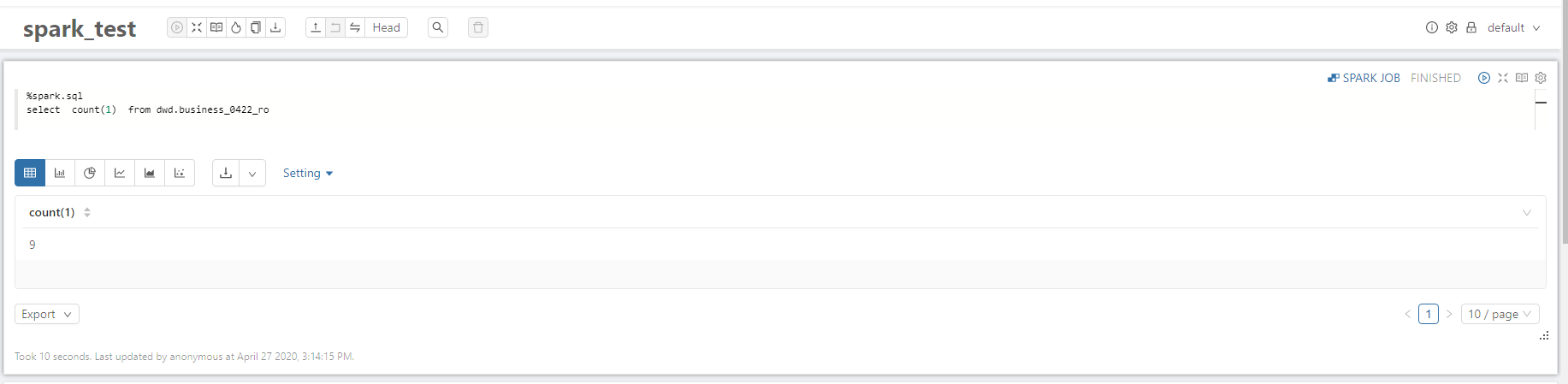
2.2.2 实时视图
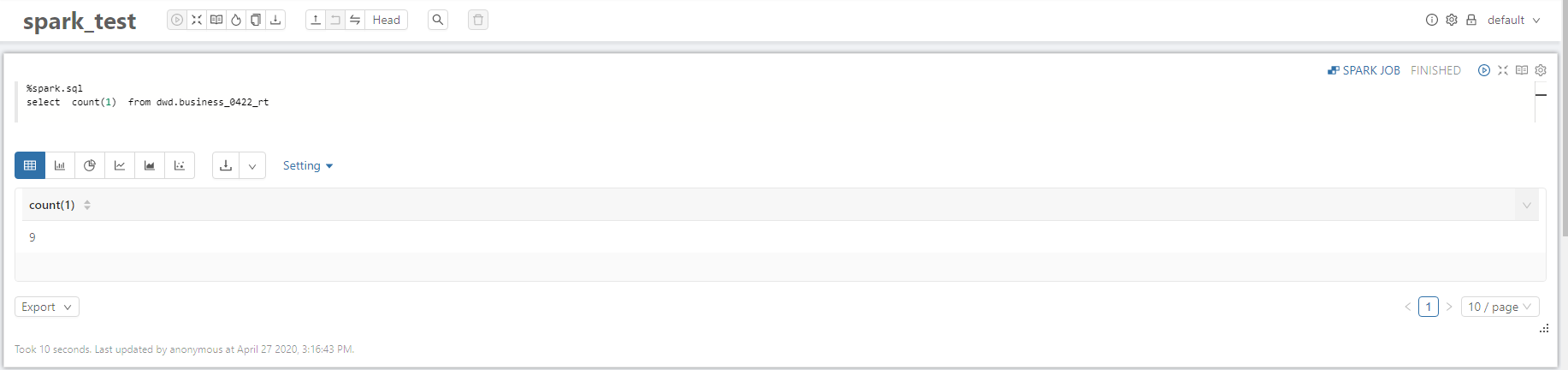
3.常见问题整理
3.1 Hudi包适配
cp hudi-hadoop-mr-bundle-0.5.2-SNAPSHOT.jar zeppelin/lib
cp hudi-hive-bundle-0.5.2-SNAPSHOT.jar zeppelin/lib
cp hudi-spark-bundle_2.11-0.5.2-SNAPSHOT.jar zeppelin/lib
Zeppelin启动时会默认加载lib下的包,对于Hudi这类外部依赖,适合直接放在zeppelin/lib下以避免 Hive或Spark SQL在集群上找不到对应Hudi依赖。
3. 2 parquet jar包适配
Hudi包的parquet版本为1.10,当前CDH集群parquet版本为1.9,所以在执行Hudi表查询时,会报很多jar包冲突的错。
解决方法:在zepeelin所在节点的spark/jars目录下将parquet包升级成1.10。
副作用:zeppelin 以外的saprk job 分配到 parquet 1.10的集群节点的任务可能会失败。
建议:zeppelin 以外的客户端也会有jar包冲突的问题。所以建议将集群的spark jar 、parquet jar以及相关依赖的jar做全面升级,更好地适配Hudi的能力。
3.3 Spark Interpreter适配
相同sql在Zeppelin上使用Spark SQL查询会出现比hive查询记录条数多的现象。
问题原因:当向Hive metastore中读写Parquet表时,Spark SQL默认将使用Spark SQL自带的Parquet SerDe(SerDe:Serialize/Deserilize的简称,目的是用于序列化和反序列化),而不是用Hive的SerDe,因为Spark SQL自带的SerDe拥有更好的性能。
这样导致了Spark SQL只会查询Hudi的流水记录,而不是最终的合并结果。
解决方法:set spark.sql.hive.convertMetastoreParquet=false
方法一:直接在页面编辑属性

方法二:编辑 zeppelin/conf/interpreter.json添加
interpreter
"spark.sql.hive.convertMetastoreParquet": {
"name": "spark.sql.hive.convertMetastoreParquet",
"value": false,
"type": "checkbox"
},
4. Hudi增量视图
对于Hudi增量视图,目前只支持通过写Spark 代码的形式拉取。考虑到Zeppelin在notebook上有直接执行代码和shell 命令的能力,后面考虑封装这些notebook,以支持sql的方式查询Hudi增量视图。
Apache Hudi集成Apache Zeppelin实战的更多相关文章
- Apache Hudi集成Spark SQL抢先体验
Apache Hudi集成Spark SQL抢先体验 1. 摘要 社区小伙伴一直期待的Hudi整合Spark SQL的PR正在积极Review中并已经快接近尾声,Hudi集成Spark SQL预计会在 ...
- Apache Hudi与Apache Flink集成
感谢王祥虎@wangxianghu 投稿 Apache Hudi是由Uber开发并开源的数据湖框架,它于2019年1月进入Apache孵化器孵化,次年5月份顺利毕业晋升为Apache顶级项目.是当前最 ...
- 生态 | Apache Hudi集成Alluxio实践
原文链接:https://mp.weixin.qq.com/s/sT2-KK23tvPY2oziEH11Kw 1. 什么是Alluxio Alluxio为数据驱动型应用和存储系统构建了桥梁, 将数据从 ...
- Apache Hudi + AWS S3 + Athena实战
Apache Hudi在阿里巴巴集团.EMIS Health,LinkNovate,Tathastu.AI,腾讯,Uber内使用,并且由Amazon AWS EMR和Google云平台支持,最近Ama ...
- 重磅!Vertica集成Apache Hudi指南
1. 摘要 本文演示了使用外部表集成 Vertica 和 Apache Hudi. 在演示中我们使用 Spark 上的 Apache Hudi 将数据摄取到 S3 中,并使用 Vertica 外部表访 ...
- 基于 Apache Hudi 和DBT 构建开放的Lakehouse
本博客的重点展示如何利用增量数据处理和执行字段级更新来构建一个开放式 Lakehouse. 我们很高兴地宣布,用户现在可以使用 Apache Hudi + dbt 来构建开放Lakehouse. 在深 ...
- Apache Hudi重磅特性解读之存量表高效迁移机制
1. 摘要 随着Apache Hudi变得越来越流行,一个挑战就是用户如何将存量的历史表迁移到Apache Hudi,Apache Hudi维护了记录级别的元数据以便提供upserts和增量拉取的核心 ...
- 恭喜!Apache Hudi社区新晋多位Committer
1. 介绍 经过Apache Hudi项目委员会讨论及投票,向Udit Mehrotra.Gary Li.Raymond Xu.Pratyaksh Sharma 4人发出Committer邀请,4人均 ...
- Apache Hudi助力nClouds加速数据交付
1. 概述 在nClouds上,当客户的业务决策取决于对近实时数据的访问时,客户通常会向我们寻求有关数据和分析平台的解决方案.但随着每天创建和收集的数据量都在增加,这使得使用传统技术进行数据分析成为一 ...
随机推荐
- 《Mathematical Analysis of Algorithms》中有关“就地排列”(In Situ Permutation)的算法分析
问题描述 把数列\((x_1,x_2,\cdots,x_n)\)变换顺序为\((x_{p(1)},x_{p(2)},\cdots,x_{p(n)})\),其中\(p\)是\(A=\{1,2,3,\cd ...
- MATLAB——文件读写(1)
1.文件打开关闭 (1)文件打开 fid=fopen(文件名,‘打开方式’)说明:其中fid用于存储文件句柄值,如果返回的句柄值大于0,则说明文件打开成功.文件名用字符串形式,表示待打开的数据文件.常 ...
- Mob之社会化分享集成ShareSDK
接着上篇顺便分享一篇自己使用 ShareSDK 的笔记,上篇我们集成了 SMSSDK 完成了短信接收验证码的功能,请参考Mob 之 短信验证集成 SMSSDK,如何在项目已经集成 SMSSDK 的情况 ...
- Blazor入门笔记(6)-组件间通信
1.环境 VS2019 16.5.1.NET Core SDK 3.1.200Blazor WebAssembly Templates 3.2.0-preview2.20160.5 2.简介 在使用B ...
- Light of future-冲刺Day 5
目录 1.SCRUM部分: 每个成员进度 SCRUM 会议的照片 签入记录 代码运行截图 用户浏览界面 订单详情界面 管理员浏览界面 新增后台界面 2.PM 报告: 时间表 燃尽图 任务总量变化曲线 ...
- touch多点触摸事件
touch--单点 targetTouches. changeTouches 多点: targetTouches--当前物体上的手指数 *不同物体上的手指不会互相干扰 不需要做多点触摸的时候---平均 ...
- 为什么要用内插字符串代替string.format
知道为什么要用内插字符串,只有踩过坑的人才能明白,如果你曾今使用string.format超5个以上占位符,那其中的痛苦我想你肯定是能够共鸣的. 一:痛苦经历 先上一段曾今写过的一段代码,大家来体会一 ...
- LVS 集群与存储《路由转发》
LVS 集群与存储<路由转发> 集群简介 u 什么是集群 • 一组通过高 ...
- 如何在 Array.forEach 中正确使用 Async
本文译自How to use async functions with Array.forEach in Javascript - Tamás Sallai. 0. 如何异步遍历元素 在第一篇文章中, ...
- dockerfile_php_apache
apache-alpine.docker php-apache.docker php-alpine php-apache-alpine.docker FROM httpd:2.4.39-alpine