RDD





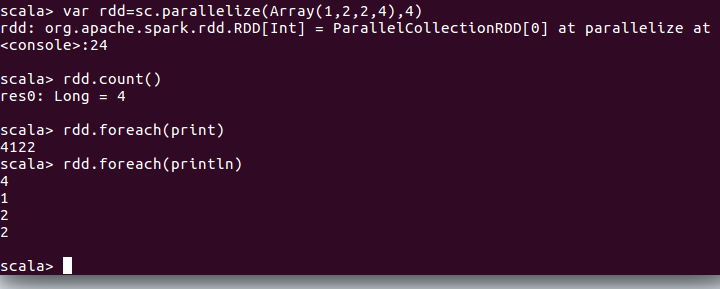




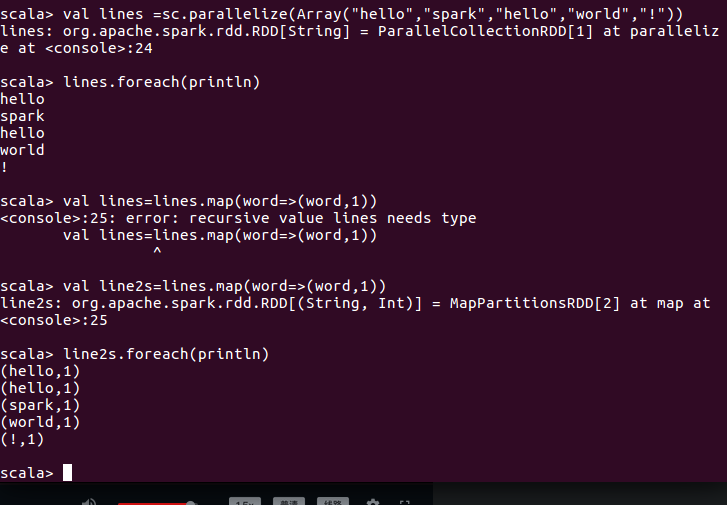

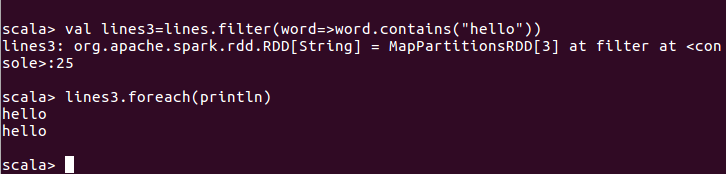

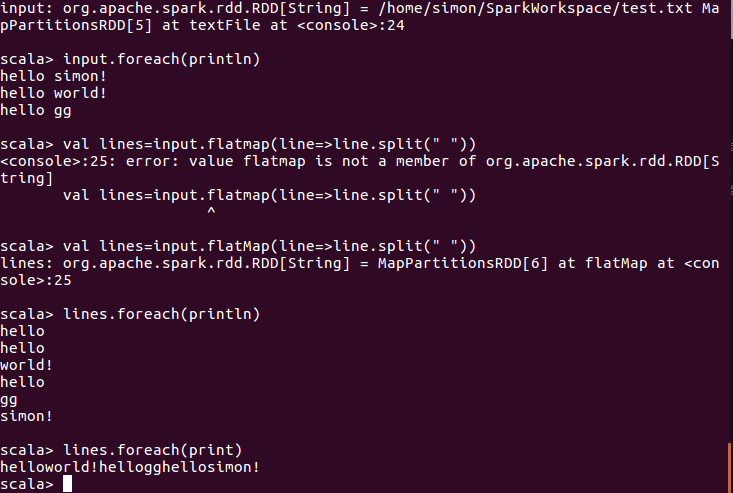
scala> val rdd1=sc.parallelize(Array("coffe","coffe","hellp","hellp","pandas","mokey") )
rdd1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[8] at parallelize at <console>:24
scala> val rdd1=sc.parallelize(Array("coffe","coffe","hellp","hellp","pandas","mokey"))
rdd1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[9] at parallelize at <console>:24
scala> val rdd2=sc.parallelize(Array("coe","coe","help","help","pandas","mokey"))
rdd2: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[10] at parallelize at <console>:24
scala> val rdd1_distinct=rdd1.distinct()
rdd1_distinct: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[13] at distinct at <console>:25
scala> rdd1_distinct.foreach(println)
hellp
mokey
pandas
coffe
scala> val rdd_union=rdd1.union(rdd2)
rdd_union: org.apache.spark.rdd.RDD[String] = UnionRDD[14] at union at <console>:27
scala> rdd1_union.foreach(println)
<console>:24: error: not found: value rdd1_union
rdd1_union.foreach(println)
^
scala> rdd_union.foreach(println)
pandas
mokey
coffe
hellp
coffe
hellp
pandas
mokey
coe
help
help
coe
scala> val rdd_intersection=rdd1.intersession(rdd2)
<console>:27: error: value intersession is not a member of org.apache.spark.rdd.RDD[String]
val rdd_intersection=rdd1.intersession(rdd2)
^
scala> val rdd_intersection=rdd1.intersection(rdd2)
rdd_intersection: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[20] at intersection at <console>:27
scala> rdd_intersection.foreach(println)
mokey
pandas
scala> val rdd_sub=rdd1.subtract(rdd2)
rdd_sub: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[24] at subtract at <console>:27
scala> rdd_sub.foreach(prinln)
<console>:26: error: not found: value prinln
rdd_sub.foreach(prinln)
^
scala> rdd_sub.foreach(println)
coffe
coffe
hellp
hellp
scala>



scala> val rdd=sc.parallelize(Array(1,2,2,3))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[25] at parallelize at <console>:24
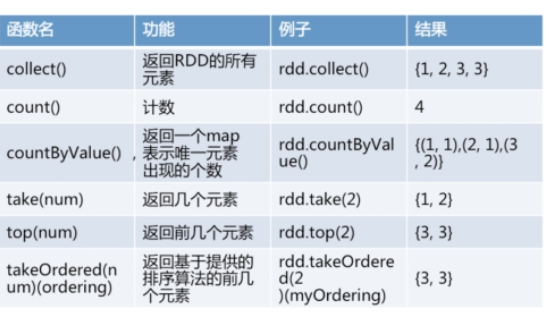
scala> rdd.collect()
res16: Array[Int] = Array(1, 2, 2, 3)
scala> rdd.reduce((x,y)=>x+y)
res18: Int = 8

scala> rdd.take(2)
res19: Array[Int] = Array(1, 2)
scala> rdd.take(3)
res20: Array[Int] = Array(1, 2, 2)
scala>

scala> rdd.top(1)
res21: Array[Int] = Array(3)
scala> rdd.top(2)
res22: Array[Int] = Array(3, 2)
scala> rdd.top(3)
res23: Array[Int] = Array(3, 2, 2)

RDD的更多相关文章
- Spark RDD 核心总结
摘要: 1.RDD的五大属性 1.1 partitions(分区) 1.2 partitioner(分区方法) 1.3 dependencies(依赖关系) 1.4 compute(获取分区迭代列表) ...
- Spark笔记:复杂RDD的API的理解(下)
本篇接着谈谈那些稍微复杂的API. 1) flatMapValues:针对Pair RDD中的每个值应用一个返回迭代器的函数,然后对返回的每个元素都生成一个对应原键的键值对记录 这个方法我最开始接 ...
- Spark笔记:复杂RDD的API的理解(上)
本篇接着讲解RDD的API,讲解那些不是很容易理解的API,同时本篇文章还将展示如何将外部的函数引入到RDD的API里使用,最后通过对RDD的API深入学习,我们还讲讲一些和RDD开发相关的scala ...
- Spark笔记:RDD基本操作(下)
上一篇里我提到可以把RDD当作一个数组,这样我们在学习spark的API时候很多问题就能很好理解了.上篇文章里的API也都是基于RDD是数组的数据模型而进行操作的. Spark是一个计算框架,是对ma ...
- Spark笔记:RDD基本操作(上)
本文主要是讲解spark里RDD的基础操作.RDD是spark特有的数据模型,谈到RDD就会提到什么弹性分布式数据集,什么有向无环图,本文暂时不去展开这些高深概念,在阅读本文时候,大家可以就把RDD当 ...
- Spark核心——RDD
Spark中最核心的概念为RDD(Resilient Distributed DataSets)中文为:弹性分布式数据集,RDD为对分布式内存对象的 抽象它表示一个被分区不可变且能并行操作的数据集:R ...
- 【原】Learning Spark (Python版) 学习笔记(一)----RDD 基本概念与命令
<Learning Spark>这本书算是Spark入门的必读书了,中文版是<Spark快速大数据分析>,不过豆瓣书评很有意思的是,英文原版评分7.4,评论都说入门而已深入不足 ...
- Spark Rdd coalesce()方法和repartition()方法
在Spark的Rdd中,Rdd是分区的. 有时候需要重新设置Rdd的分区数量,比如Rdd的分区中,Rdd分区比较多,但是每个Rdd的数据量比较小,需要设置一个比较合理的分区.或者需要把Rdd的分区数量 ...
- RDD/Dataset/DataFrame互转
1.RDD -> Dataset val ds = rdd.toDS() 2.RDD -> DataFrame val df = spark.read.json(rdd) 3.Datase ...
- 深入理解Spark(一):Spark核心概念RDD
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此,RDD支持 ...
随机推荐
- spool
一.常用设置 set lin 1000 --一行可容纳字符数{80|n};输出大于设置值,则折行显示set wrap on --输出行长度大于设置长度时(set lin n设置);值为on,多余字符另 ...
- 一、springBoot简介与环境搭建
前言:学习计划 1.springBoot环境搭建 2.springBoot入门 3.srpingBoot整合Mybatis 4.springBoot整合Redis,Redis集群 5.springBo ...
- Linux:Day5 shell编程初步、grep
bash的基本特性(3) 1.提供了编程环境 程序编程风格: 过程式:以指令为中心,数据服务于指令: 对象式:以数据为中心,指令服务于数据: shell程序:提供了编程能力,解释执行:过程式.解释执行 ...
- (1)ESP8266微信门铃
http://rayuu.com/2017/11/13/esp8266-wechat-doorbell/(留做参考) 就是当门铃按键按下,微信会收到消息提醒. 若在家就算了,没在家会受到远程提示. 自 ...
- 根据考试成绩输出对应的礼物,90分以上爸爸给买电脑,80分以上爸爸给买手机, 60分以上爸爸请吃一顿大餐,60分以下爸爸给买学习资料。 要求:该题使用多重if完成
package com.Summer_0417.cn; import java.util.Scanner; /** * @author Summer * 根据考试成绩输出对应的礼物, * 90分以上爸 ...
- 环境部署(三):Linux下安装Git
Git是一个开源的分布式版本控制系统,可以有效.高速的处理从很小到非常大的项目版本管理,是目前使用范围最广的版本管理工具. 这篇博客,介绍下Linux下安装Git的步骤,仅供参考,当然,还是yum安装 ...
- Java关键字(四)——final
对于Java中的 final 关键字,我们首先可以从字面意思上去理解,百度翻译显示如下: 也就是说 final 英文意思表示是最后的,不可更改的.那么对应在 Java 中也是表达这样的意思,可以用 f ...
- HTML+CSS之盒子模型
一.元素分类 CSS中html的标签元素大体分为三种类型 1.块状元素 @特点: #每个块级元素都从新的一行开始,并且其后的元素也另起一行(一个块级元素独占一行) #元素的高度.宽度.行高以及顶和底边 ...
- 线程GIL锁 线程队列 回调函数
----------------------------------无法改变风向,可以调整风帆;无法左右天气,可以调整心情.如果事情无法改变,那就去改变观念. # # ---------------- ...
- 剑指offer--1.二维数组中的查找
题目:在一个二维数组中(每个一维数组的长度相同),每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序.请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数. ...