Python学习笔记之爬虫
爬虫调度端:启动爬虫,停止爬虫,监视爬虫运行情况
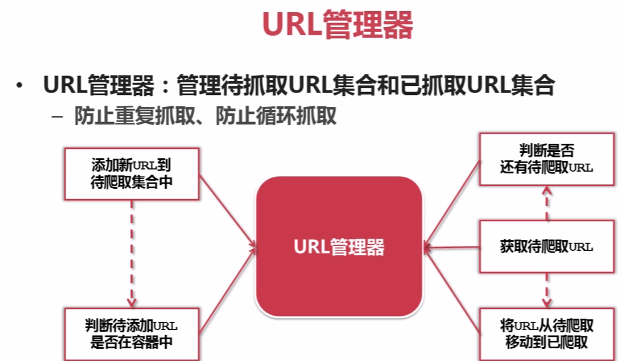
URL管理器:对将要爬取的和已经爬取过的URL进行管理;可取出带爬取的URL,将其传送给“网页下载器”
网页下载器:将URL指定的网页下载,存储成一个字符串,在传送给“网页解析器”
网页解析器:解析网页可解析出①有价值的数据②另一方面,每个网页都包含有指向其他网页的URL,解析出来后可补充进“URL管理器”

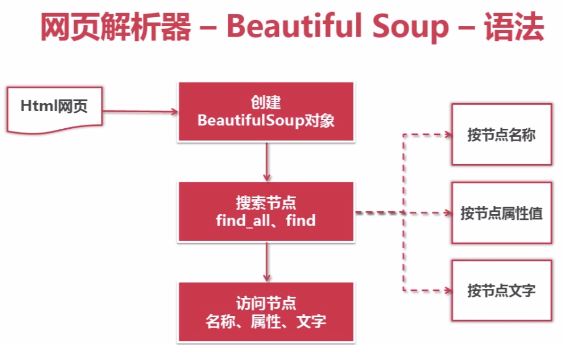
网页解析器——Beautiful Soup-语法:
例如以下代码:

对应的代码:
1、创建BeautifulSoap对象
2、搜索节点(find_all,find)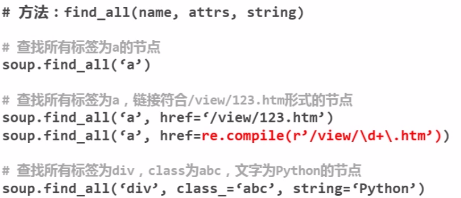
3、访问节点信息
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
import re
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p> <p class="story">...</p>
""" soup = BeautifulSoup(html_doc,'html.parser', from_encoding='utf-8')#(文档字符串,解析器,指定编码utf-8)
print('获取所有的连接:')
links = soup.find_all('a')
for link in links:
print link.name, link['href'],link.get_text() print('获取Lacie的连接:')
link_node = soup.find('a', href='http://example.com/lacie')#text='Lacie'
print link_node.name,link_node['href'],link_node.get_text() print('正则匹配')
link_node = soup.find('a', href=re.compile(r'ill'))
print link_node.name,link_node['href'],link.get_text() print('获取p段落文字:')
p_node = soup.find('p', class_='title')#class_
print p_node.name, p_node.get_text()
Python学习笔记之爬虫的更多相关文章
- python学习笔记:"爬虫+有道词典"实现一个简单的英译汉程序
1.有道的翻译 网页:www.youdao.com Fig1 Fig2 Fig3 Fig4 再次点击"自动翻译"->选中'Network'->选中'第一项',如下: F ...
- 吴裕雄--python学习笔记:爬虫基础
一.什么是爬虫 爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息. 二.Python爬虫架构 Python 爬虫架构主要由五个部分组成,分别是调度器.URL管理器.网页下载器.网 ...
- Python学习笔记——与爬虫相关的网络知识
1 关于URL URL(Uniform / Universal Resource Locator):统一资源定位符,用于完整地描述Internet上网页和其他资源的地址的一种标识方法 URL是爬虫的入 ...
- 吴裕雄--python学习笔记:爬虫包的更换
python 3.x报错:No module named 'cookielib'或No module named 'urllib2' 1. ModuleNotFoundError: No module ...
- 吴裕雄--python学习笔记:爬虫
import chardet import urllib.request page = urllib.request.urlopen('http://photo.sina.com.cn/') #打开网 ...
- Python学习笔记_爬虫数据存储为xlsx格式的方法
import requests from bs4 import BeautifulSoup import openpyxl wb=openpyxl.Workbook() sheet=wb.active ...
- golang学习笔记17 爬虫技术路线图,python,java,nodejs,go语言,scrapy主流框架介绍
golang学习笔记17 爬虫技术路线图,python,java,nodejs,go语言,scrapy主流框架介绍 go语言爬虫框架:gocolly/colly,goquery,colly,chrom ...
- python学习笔记目录
人生苦短,我学python学习笔记目录: week1 python入门week2 python基础week3 python进阶week4 python模块week5 python高阶week6 数据结 ...
- Python学习笔记之基础篇(-)python介绍与安装
Python学习笔记之基础篇(-)初识python Python的理念:崇尚优美.清晰.简单,是一个优秀并广泛使用的语言. python的历史: 1989年,为了打发圣诞节假期,作者Guido开始写P ...
随机推荐
- CF&&CC百套计划3 Codeforces Round #204 (Div. 1) A. Jeff and Rounding
http://codeforces.com/problemset/problem/351/A 题意: 2*n个数,选n个数上取整,n个数下取整 最小化 abs(取整之后数的和-原来数的和) 先使所有的 ...
- Nginx错误日志与优化专题
一.Nginx配置和内核优化 实现突破十万并发 二.一次Nignx的502页面的错误记录 (1)错误页面显示 错误日志: // :: [error] #: * recv() failed (: Con ...
- Java并发编程原理与实战二十二:Condition的使用
Condition的使用 Condition用于实现条件锁,可以唤醒指定的阻塞线程.下面来实现一个多线程顺序打印a,b,c的例子. 先来看用wait和notify的实现: public class D ...
- [译]Quartz.NET 框架 教程(中文版)2.2.x 之第八课 调度监听器
第八课 调度监听器 调度监听器和触发监听器和触发监听器.作业任务监听器非常相似,只是调度监听器在调度器内接收通知事件,而不需要关联具体的触发器或作业任务事件. 跟调度监听器相关的事件,添加作业任务/触 ...
- 浅谈ASP.net处理XML数据
XML是一种可扩展的标记语言,比之之前谈到的html有着很大的灵活性,虽然它只是与HTML仅有一个字母只差,但两者有很大的区别. XML也是标记语言,所以它每个标签必须要闭合,而HTML偶尔忘了闭合也 ...
- 支付宝hr终面,忐忑的等待结果
上周一,内推网投了支付宝上海的 高级java软件开发工程师:阿里效率就是高,不到30分钟电话就过来了!约的上周五14:00面试:上周五技术面了2轮,第一轮是主管面试,貌似给了p6;第二轮部门总监面试, ...
- ubuntun16.04+cuda9.0+cudnn7+anaconda3+pytorch+anaconda3下py2安装pytorch
一.电脑配置 说明: 电脑配置: LEGION笔记本CPU Inter Core i7 8代GPU NVIDIA GeForce GTX1060Windows10 所需的环境: Anaconda3(6 ...
- 读后感+资源-----java8函数式编程pdf
花了两周时间工作之余抽空读完了这本书,对lamdba以及java的理解又有了一个新的认识(装个逼,哈哈) 以前看视频学习的还是太基本了,感觉读书更容易理解背后的设计思想和编程思路 这本书还是挺不错,就 ...
- 渗透测试的WINDOWS NTFS技巧集合
译者:zzzhhh 这篇文章是来自SEC Consult Vulnerability Lab的ReneFreingruber (@ReneFreingruber),分享了过去几年从各种博客文章中收集的 ...
- Linux input子系统学习总结(一)---- 三个重要的结构体
一 . 总体架构 图 上层是图形界面和应用程序,通过监听设备节点,获取用户相应的输入事件,根据输入事件来做出相应的反应:eventX (X从0开始)表示 按键事件,mice 表示鼠标事件 Input ...