HBase(二)CentOS7.5搭建HBase1.2.6HA集群
一、安装前提
1、HBase 依赖于 HDFS 做底层的数据存储
2、HBase 依赖于 MapReduce 做数据计算
3、HBase 依赖于 ZooKeeper 做服务协调
4、HBase源码是java编写的,安装需要依赖JDK
1、版本选择
打开官方的版本说明http://hbase.apache.org/1.2/book.html
JDK的选择
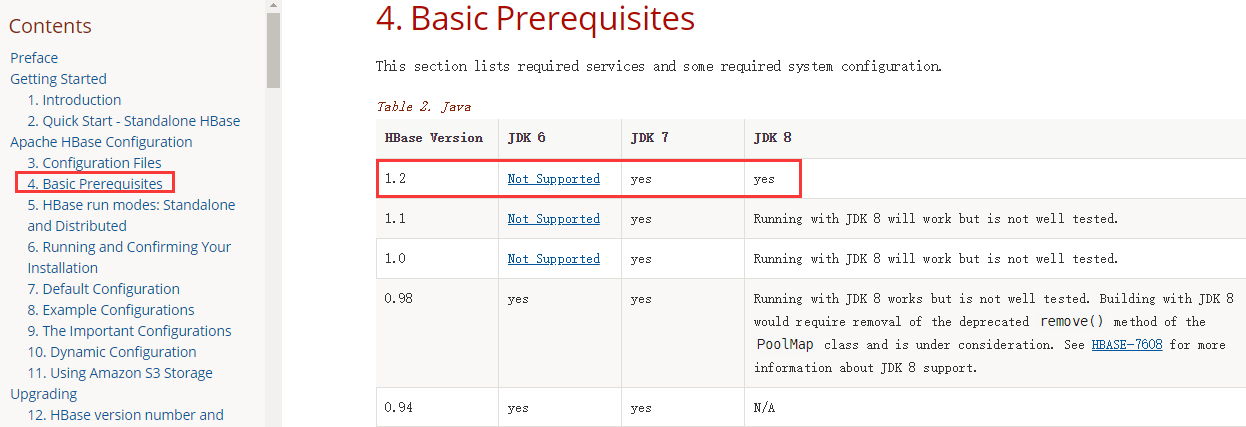
Hadoop的选择

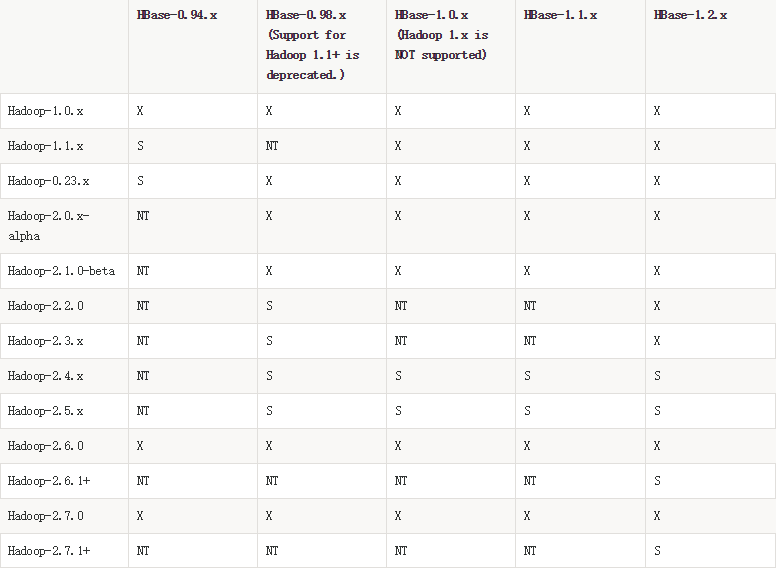
此处我们的hadoop版本用的的是2.7.6,HBase选择的版本是1.2.6
2、下载安装包
官网下载地址:http://archive.apache.org/dist/hbase/

3、完全分布式部署
默认情况下,HBase以独立模式运行。提供独立模式和伪分布模式都是为了进行小规模测试。
对于生产环境,分布式模式是合适的。在分布式模式下,HBase守护程序的多个实例在群集中的多个服务器上运行。
| 节点IP | 节点名称 | Master | BackupMaster | RegionServer | Zookeeper | HDFS |
| 192.168.100.21 | node21 | √ | √ | √ | √ | |
| 192.168.100.22 | node22 | √ | √ | √ | √ | |
| 192.168.100.23 | node23 | √ | √ | √ |
Zookeeper集群安装参考:CentOS7.5搭建Zookeeper3.4.12集群
Hadoop集群安装参考:CentOS7.5搭建Hadoop2.7.6完全分布式集群
二、HBase的集群安装
安装过程参考官方文档:http://hbase.apache.org/1.2/book.html#standalone_dist
1、上传解压缩
解压 HBase 到指定目录:
[admin@node21 software]$ tar zxvf hbase-1.2.6-bin.tar.gz -C /opt/module/
2、修改配置文件
配置文件在/opt/module/hbase-1.2.6/conf目录下
hbase-env.sh 修改内容:
export JAVA_HOME=/opt/module/jdk1.8
export HBASE_MANAGES_ZK=false
hbase-site.xml 修改内容:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node21,node22,node23</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/module/zookeeper-3.4.12/Data</value>
</property>
</configuration>
region servers修改内容:
node21
node22
node23
在 conf 目录下创建 backup-masters 文件,添加备机名
$ echo node22 > conf/backup-masters
3、软连接Hadoop配置
[admin@node21 ~]$ ln -s /opt/module/hadoop-2.7.6/etc/hadoop/hdfs-site.xml /opt/module/hbase-1.2.6/conf/
4、替换Hbase依赖的Jar包
由于 HBase 需要依赖 Hadoop,所以替换 HBase 的 lib 目录下的 jar 包,以解决兼容问题:
1) 删除原有的 jar:
[admin@node21 ~]$ rm -rf /opt/module/hbase-1.2./lib/hadoop-*
[admin@node21 ~]$ rm -rf /opt/module/hbase-1.2./lib/zookeeper-3.4..jar
2) 拷贝新 jar,涉及的 jar 有:
hadoop-annotations-2.7.6.jar hadoop-mapreduce-client-app-2.7.6.jar hadoop-mapreduce-client-hs-plugins-2.7.6.jar
hadoop-auth-2.7.6.jar hadoop-mapreduce-client-common-2.7.6.jar hadoop-mapreduce-client-jobclient-2.7.6.jar
hadoop-common-2.7.6.jar hadoop-mapreduce-client-core-2.7.6.jar hadoop-mapreduce-client-shuffle-2.7.6.jar
hadoop-hdfs-2.7.6.jar hadoop-mapreduce-client-hs-2.7.6.jar hadoop-yarn-api-2.7.6.jar
hadoop-yarn-client-2.7.6.jar hadoop-yarn-common-2.7.6.jar hadoop-yarn-server-common-2.7.6.jar
zookeeper-3.4.12.jar
尖叫提示:这些 jar 包的对应版本应替换成你目前使用的 hadoop 版本,具体情况具体分析。
[admin@node21 ~]$ find /opt/module/hadoop-2.7.6/ -name hadoop-annotations*
然后将找到的 jar 包复制到 HBase 的 lib 目录下即可。
5、分发安装包到其他节点
[admin@node21 ~]$ scp -r /opt/module/hbase-1.2./ node22:/opt/module/
[admin@node21 ~]$ scp -r /opt/module/hbase-1.2./ node23:/opt/module/
6、配置环境变量
所有服务器都有进行配置
[admin@node21 ~]$ vi /etc/profile
#HBase
export HBASE_HOME=/opt/module/hbase-1.2.6
export PATH=$PATH:$HBASE_HOME/bin
使环境变量立即生效
[admin@node21 ~]$ source /etc/profile
7、同步时间
尖叫提示: HBase 集群对于时间的同步要求的比HDFS严格,如果集群之间的节点时间不同步,会导致 region server 无法启动,抛出ClockOutOfSyncException 异常。所以,集群启动之前千万记住要进行 时间同步,要求相差不要超过 30s.
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
<description>Time difference of regionserver from master</description>
</property>
三、启动HBase集群
严格按照启动顺序进行
1、启动zookeeper集群
每个zookeeper节点都要执行以下命令
[admin@node21 ~]$ zkServer.sh start
2、启动Hadoop集群
如果需要运行MapReduce程序则启动yarn集群,否则不需要启动
[admin@node21 ~]$ start-dfs.sh
[admin@node22 ~]$ start-yarn.sh
3、启动HBase集群
保证 ZooKeeper 集群和 HDFS 集群启动正常的情况下启动 HBase 集群 启动命令:start-hbase.sh,在哪台节点上执行此命令,哪个节点就是主节点
启动方式 1:
[admin@node21 ~]$ start-hbase.sh
starting master, logging to /opt/module/hbase-1.2./logs/hbase-admin-master-node21.out
node23: starting regionserver, logging to /opt/module/hbase-1.2./logs/hbase-admin-regionserver-node23.out
node21: starting regionserver, logging to /opt/module/hbase-1.2./logs/hbase-admin-regionserver-node21.out
node22: starting regionserver, logging to /opt/module/hbase-1.2./logs/hbase-admin-regionserver-node22.out
node22: starting master, logging to /opt/module/hbase-1.2./logs/hbase-admin-master-node22.out
启动方式 2:
$ hbase-daemon.sh start master
$ hbase-daemon.sh start regionserver
观看启动日志可以看到:
(1)首先在命令执行节点启动 master
(2)然后分别在 node21,node22,node23 启动 regionserver
(3)然后在 backup-masters 文件中配置的备节点上再启动一个 master 主进程
尖叫提 示: 如果使用的是 JDK8 以 上 版 本 , 则 应 在 hbase-evn.sh 中 移除 “HBASE_MASTER_OPTS”和“HBASE_REGIONSERVER_OPTS”配置。
4、停止HBase集群
[admin@node21 ~]$ stop-hbase.sh
四、验证启动是否正常
1、检查各进程是否启动正常
主节点和备用节点都启动 hmaster 进程,各从节点都启动 hregionserver 进程,按照对应的配置信息各个节点应该要启动的进程如下所示
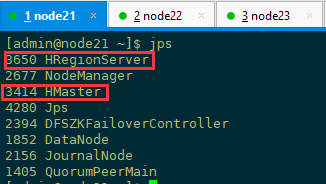
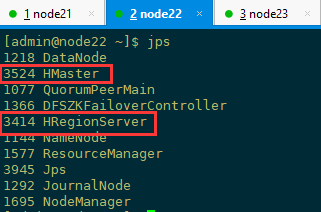
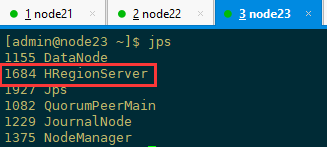
2、通过访问浏览器页面查看
WebUI地址查看:http://node21:16010/master-status
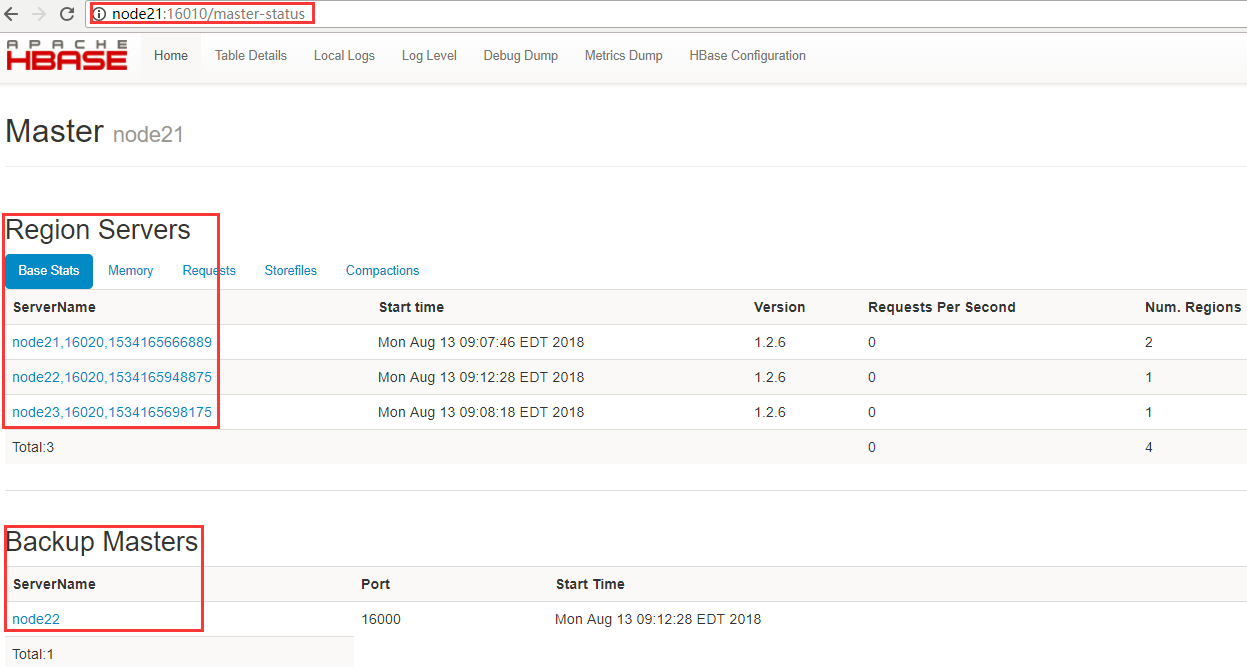
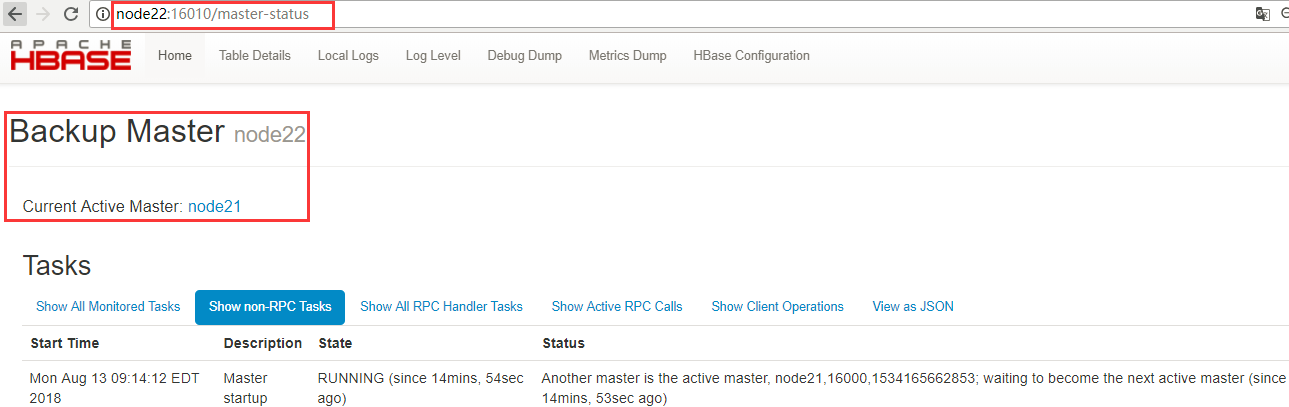
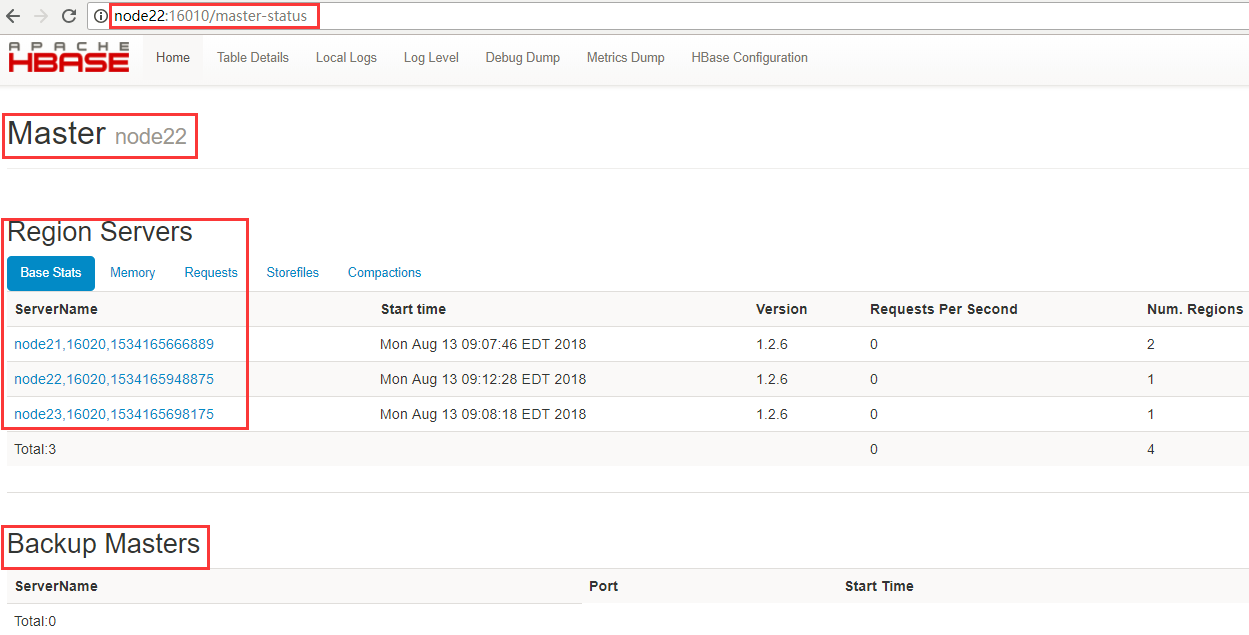
3、验证高可用
干掉node21上的hbase进程,观察备用节点是否启用
[admin@node21 ~]$ kill -9 3414
node21界面访问失败,node22变成主节点
4、手动启动进程
启动HMaster进程,当node21节点上的HMaster进程起来后又会成为备用Master,状态可通过webUI查看。
[admin@node21 ~]$ jps
HRegionServer
NodeManager
DFSZKFailoverController
Jps
DataNode
JournalNode
QuorumPeerMain
[admin@node21 ~]$ hbase-daemon.sh start master
starting master, logging to /opt/module/hbase-1.2./logs/hbase-admin-master-node21.out
[admin@node21 ~]$ jps
HRegionServer
NodeManager
HMaster
Jps
DFSZKFailoverController
DataNode
JournalNode
QuorumPeerMain
启动HRegionServer进程
$ hbase-daemon.sh start regionserver
HBase(二)CentOS7.5搭建HBase1.2.6HA集群的更多相关文章
- Storm(二)CentOS7.5搭建Storm1.2.2集群
一.Storm的下载 官网下载地址:http://storm.apache.org/downloads.html 这里下载最新的版本storm1.2.2,进入之后选择一个镜像下载 二.Storm伪分布 ...
- CentOS7.5搭建spark2.3.1集群
一 下载安装包 1 官方下载 官方下载地址:http://spark.apache.org/downloads.html 2 安装前提 Java8 安装成功 zookeeper 安 ...
- CentOS7.5搭建Solr7.4.0集群服务
一.Solr集群概念 solr单机版搭建参考: https://www.cnblogs.com/frankdeng/p/9615253.html 1.概念 SolrCloud(solr 云)是Solr ...
- centos7 下搭建hadoop2.9 分布式集群
首先说明,本文记录的是博主搭建的3节点的完全分布式hadoop集群的过程,环境是centos 7,1个nameNode,2个dataNode,如下: 1.首先,创建好3个Centos7的虚拟机,具体的 ...
- CentOS7.5搭建ELK6.2.4集群及插件安装
一 简介 Elasticsearch是一个高度可扩展的开源全文搜索和分析引擎.它允许您快速,近实时地存储,搜索和分析大量数据.它通常用作支持具有复杂搜索功能和需求的应用程序的底层引擎/技术. 下载地址 ...
- CentOS7.5搭建ES6.2.4集群与简单测试
一 简介 Elasticsearch是一个高度可扩展的开源全文搜索和分析引擎.它允许您快速,近实时地存储,搜索和分析大量数据.它通常用作支持具有复杂搜索功能和需求的应用程序的底层引擎/技术. 下载地址 ...
- Zookeeper(一)CentOS7.5搭建Zookeeper3.4.12集群与命令行操作
一. 分布式安装部署 1.0 下载地址 官网首页: https://zookeeper.apache.org/ 下载地址: http://mirror.bit.edu.cn/apache/zookee ...
- centos7环境搭建Eureka-Server注册中心集群
目的:测试和线上使用这套独立的Eureka-Server注册中心集群,目前3台虚拟机集群,后续可直接修改配置文件进行新增或减少集群机器. 系统环境: Centos7x64 java8+(JDK1.8+ ...
- 在CentOS7下搭建Hadoop2.9.0集群
系统环境:CentOS 7 JDK版本:jdk-8u191-linux-x64 MYSQL版本:5.7.26 Hadoop版本:2.9.0 Hive版本:2.3.4 Host Name Ip User ...
随机推荐
- 转:CocoaPods pod install/pod update更新慢的问题
最近使用CocoaPods来添加第三方类库,无论是执行pod install还是pod update都卡在了Analyzing dependencies不动 原因在于当执行以上两个命令的时候会升级Co ...
- 使用 Collections 实现排序 sort方法 对List 实体类实现Comparable类 示例
package com.test.jj; import java.util.ArrayList; import java.util.Collections; public class Test { A ...
- bzoj千题计划163:bzoj1060: [ZJOI2007]时态同步
http://www.lydsy.com/JudgeOnline/problem.php?id=1060 以激发器所在节点为根 终止节点一定是叶节点 记录点的子树内最深的终止节点 然后从根往下使用道具 ...
- Linux学习4-信号
信号 信号是Unix和Linux系统响应某些条件而产生的一个条件.接收到该信号的进程会相应的采取一些行动. 信号是由于某些错误条件而生成的,如内存冲突,浮点处理器错误或非法指令等.它们由shell ...
- 莫队-小Z的袜子
----普通莫队 首先清楚概率怎么求假设我们要求从区间l到r中拿出一对袜子的概率sum[i]为第i种袜子在l到r中的数量 $$\frac{\sum_{i=l}^{r} {[sum[i] \times ...
- Django外键关系:一对一、一对多,多对多
1. 一对多 model.py class UserTest(models.Model): name = models.CharField(max_length = 16 ) sex = models ...
- 【译】第七篇 SQL Server代理作业活动监视器
本篇文章是SQL Server代理系列的第七篇,详细内容请参考原文 在这一系列的上一篇,你创建并配置SQL Server代理作业.每个作业有一个或多个步骤,可能包含大量的工作流.在这篇文章中,将查看作 ...
- C. Connect Three(构造)
题目链接:http://codeforces.com/contest/1087/problem/C 题目大意:给你三个点的坐标,让你用尽可能少的方块,让这三个点连起来. 具体思路: 我们先对这三个点进 ...
- linux中set、unset、export、env、declare,readonly的区别以及用法
set命令显示当前shell的变量,包括当前用户的变量; env命令显示当前用户的变量; export命令显示当前导出成用户变量的shell变量. 每个shell有自己特有 ...
- python面向对象——类
from:http://www.runoob.com/python3/python3-class.html Python3 面向对象 Python从设计之初就已经是一门面向对象的语言,正因为如此,在P ...