Storm(二)CentOS7.5搭建Storm1.2.2集群
一.Storm的下载
官网下载地址:http://storm.apache.org/downloads.html
这里下载最新的版本storm1.2.2,进入之后选择一个镜像下载
二.Storm伪分布式安装
1.环境准备
JDK 1.7+ 验证: java -version
Python 2.6.6+ 验证:python -V
2.解压安装包
[admin@node21 software]$ tar zxvf apache-storm-1.2..tar.gz -C /opt/module/
3.创建logs文件目录
[admin@node21 software]$ cd /opt/module/apache-storm-1.2.
[admin@node21 apache-storm-1.2.]$ mkdir logs
4.启动storm
- 查看帮助
[admin@node21 apache-storm-1.2.]$ ./bin/storm help
帮助如下
[admin@node21 storm-1.2.]$ ./bin/storm help
Commands:
activate
blobstore
classpath
deactivate
dev-zookeeper
drpc
get-errors
heartbeats
help
jar
kill
kill_workers
list
localconfvalue
logviewer
monitor
nimbus
node-health-check
pacemaker
rebalance
remoteconfvalue
repl
set_log_level
shell
sql
supervisor
ui
upload-credentials
version Help:
help
help <command> Documentation for the storm client can be found at http://storm.apache.org/documentation/Command-line-client.html Configs can be overridden using one or more -c flags, e.g. "storm list -c nimbus.host=nimbus.mycompany.com"
- 启动Zookeeper
[admin@node21 apache-storm-1.2.]$ ./bin/storm dev-zookeeper >> ./logs/zk.out >& &
- 启动Nimbus
[admin@node21 apache-storm-1.2.]$ ./bin/storm nimbus >> ./logs/nimbus.out >& &
- 启动Storm UI
[admin@node21 apache-storm-1.2.]$ ./bin/storm ui >> ./logs/ui.out >& &
- 启动Supervisor
[admin@node21 apache-storm-1.2.]$ ./bin/storm supervisor >> ./logs/supervisor.out >& &
- 启动Logviewer
[admin@node21 apache-storm-1.2.]$ ./bin/storm logviewer ./logs/logviewer.out 2>&1 &
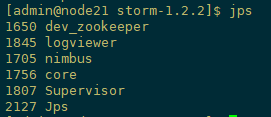
5.查看进程
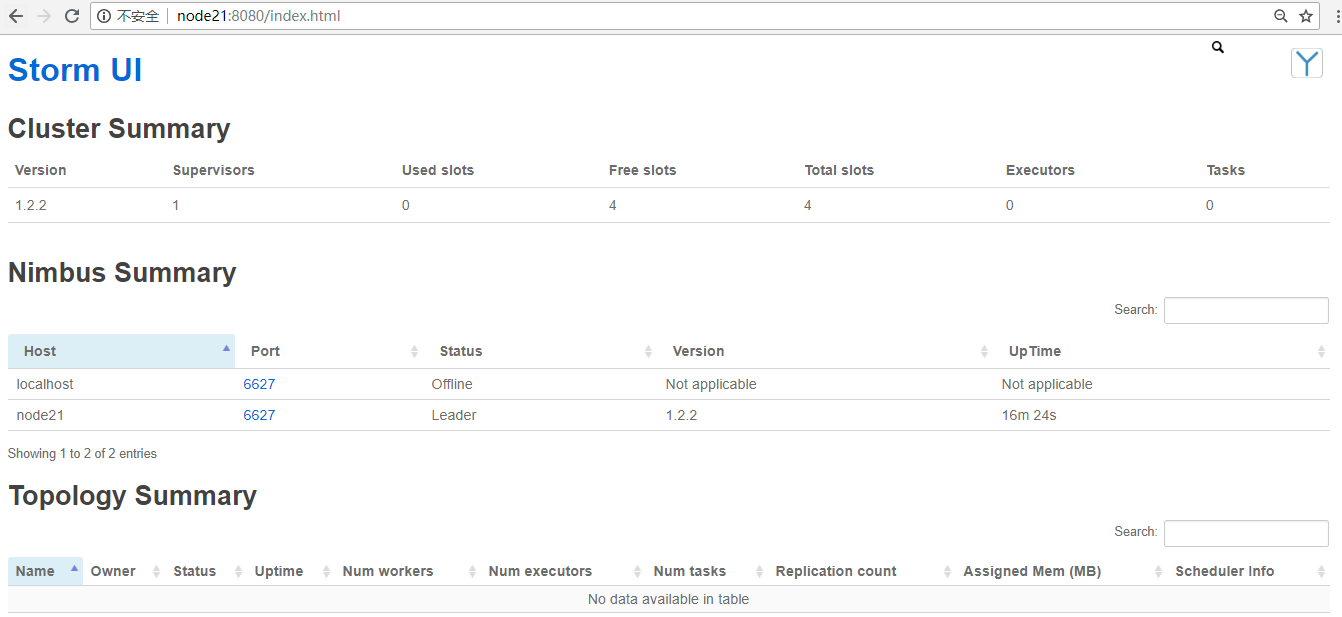
6.WebUI查看
WebUI查看地址:http://node21:8080/
三.Storm分布式集群安装
官网集群配置文档:http://storm.apache.org/releases/1.2.2/Setting-up-a-Storm-cluster.html
1.集群部署
| IP | 节点名称 | Jdk,Python | Zookeeper | Nimbus | Supervisor |
| 192.168.100.21 | node21 | Jdk,Python | Zookeeper | Nimbus | |
| 192.168.100.22 | node22 | Jdk,Python | Zookeeper | Supervisor | |
| 192.168.100.23 | node23 | Jdk,Python | Zookeeper | Supervisor |
Zookeeper集群安装参考: CentOS7.5搭建Zookeeper3.4.12集群与命令行操作
2.安装环境解压安装包
[admin@node21 software]$ tar zxvf apache-storm-1.2..tar.gz -C /opt/module/
[admin@node21 software]$ cd /opt/module/
[admin@node21 module]$ mv apache-storm-1.2./ storm-1.2.
[admin@node21 module]$ cd storm-1.2.
[admin@node21 storm-1.2.]$ mkdir logs
3.修改yaml配置文件
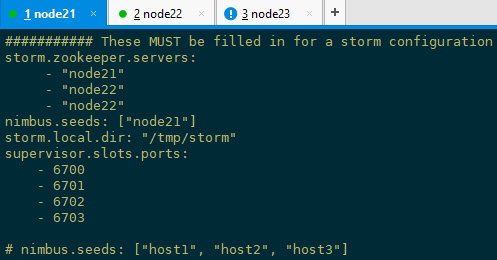
[admin@node21 storm-1.2.]$ vi conf/storm.yaml
1)storm.zookeeper.servers:这是Storm集群的Zookeeper集群中的主机列表。
2)storm.local.dir:Nimbus和Supervisor守护进程需要本地磁盘上的目录来存储少量状态(如jar,confs和类似的东西)。您应该在每台计算机上创建该目录,为其提供适当的权限,然后使用此配置填写目录位置。
3)nimbus.seeds:工作节点需要知道哪些机器是主机的候选者才能下载拓扑罐和confs。
4)supervisor.slots.ports:对于每个工作者计算机,您可以使用此配置配置在该计算机上运行的工作程序数。每个工作人员使用单个端口接收消息,此设置定义哪些端口可以使用。如果您在此处定义了五个端口,那么Storm将分配最多五个工作人员在此计算机上运行。如果定义三个端口,Storm最多只能运行三个端口。默认情况下,此设置配置为在端口6700,6701,6702和6703上运行4个工作程序。
4.分发Storm到其他节点
[admin@node21 module]$ scp -r storm-1.2./ node22:`pwd`
[admin@node21 module]$ scp -r storm-1.2./ node23:`pwd`
5.配置环境变量
[admin@node21 module]$ sudo vi /etc/profile
export STORM_HOME=/opt/module/storm-1.2.
export PATH=$PATH:$STORM_HOME/bin
[admin@node21 module]$ source /etc/profile
6.启动集群
- 启动zookeeper集群,各个节点执行
$ zkServer.sh start
- 启动storm集群
node21上启动Nimbus,启动webUI
[admin@node21 storm-1.2.]$ ./bin/storm nimbus >> ./logs/nimbus.out >& &
[admin@node21 storm-1.2.]$ ./bin/storm ui >> ./logs/ui.out >& &
node22和node23启动supervisor,按照配置,每启动一个supervisor就有了4个slots
[admin@node22 storm-1.2.]$ ./bin/storm supervisor >> ./logs/supervisor.out >& &
[admin@node23 storm-1.2.]$ ./bin/storm supervisor >> ./logs/supervisor.out >& &
7.查看进程


8.查看WebUI
WebUI查看地址:http://node21:8080/
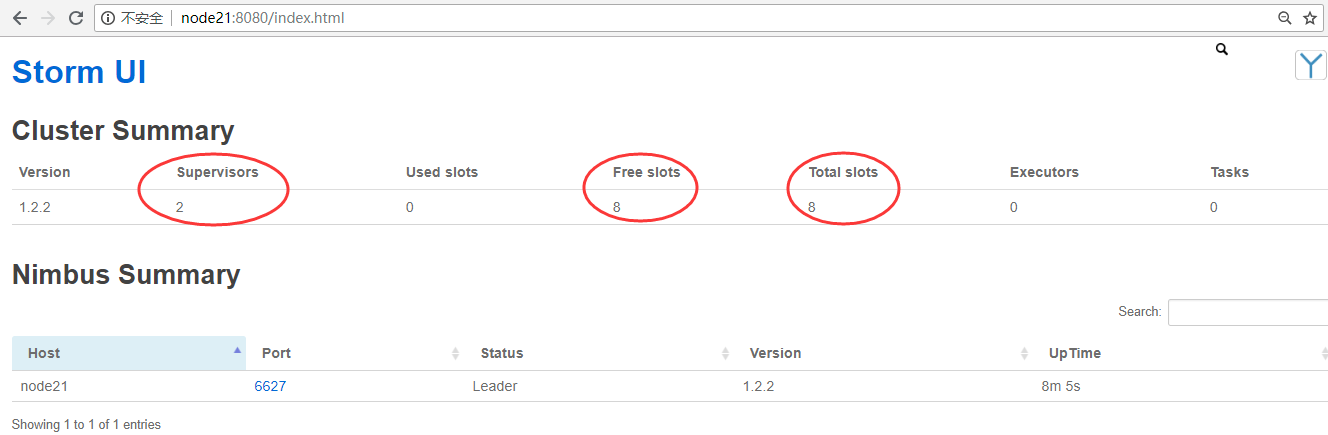
9.编写storm服务脚本
node21上 start-stormCluster.sh
#!/bin/bash
echo "******************** 正在启动nimbus服务 *******************"
ssh admin@node21 '/opt/module/storm-1.2.2/bin/storm nimbus >> /opt/module/storm-1.2.2/logs/nimbus.out 2>&1 &'
echo "********************* 正在启动webUi服务 ******************"
ssh admin@node21 '/opt/module/storm-1.2.2/bin/storm ui >> /opt/module/storm-1.2.2/logs/ui.out 2>&1 &'
echo "******************** 正在启动supervisor服务 *******************"
ssh admin@node22 '/opt/module/storm-1.2.2/bin/storm supervisor >> /opt/module/storm-1.2.2/logs/supervisor.out 2>&1 &'
ssh admin@node23 '/opt/module/storm-1.2.2/bin/storm supervisor >> /opt/module/storm-1.2.2/logs/supervisor.out 2>&1 &'
echo "****************** 服务启动成功 *******************"*
给脚本赋权限 :chmod +x 脚本名称
四.故障排除
参考文档:http://storm.apache.org/releases/1.2.2/Troubleshooting.html
Storm(二)CentOS7.5搭建Storm1.2.2集群的更多相关文章
- HBase(二)CentOS7.5搭建HBase1.2.6HA集群
一.安装前提 1.HBase 依赖于 HDFS 做底层的数据存储 2.HBase 依赖于 MapReduce 做数据计算 3.HBase 依赖于 ZooKeeper 做服务协调 4.HBase源码是j ...
- CentOS7.5搭建spark2.3.1集群
一 下载安装包 1 官方下载 官方下载地址:http://spark.apache.org/downloads.html 2 安装前提 Java8 安装成功 zookeeper 安 ...
- CentOS7.5搭建Solr7.4.0集群服务
一.Solr集群概念 solr单机版搭建参考: https://www.cnblogs.com/frankdeng/p/9615253.html 1.概念 SolrCloud(solr 云)是Solr ...
- centos7 下搭建hadoop2.9 分布式集群
首先说明,本文记录的是博主搭建的3节点的完全分布式hadoop集群的过程,环境是centos 7,1个nameNode,2个dataNode,如下: 1.首先,创建好3个Centos7的虚拟机,具体的 ...
- CentOS7.5搭建ELK6.2.4集群及插件安装
一 简介 Elasticsearch是一个高度可扩展的开源全文搜索和分析引擎.它允许您快速,近实时地存储,搜索和分析大量数据.它通常用作支持具有复杂搜索功能和需求的应用程序的底层引擎/技术. 下载地址 ...
- CentOS7.5搭建ES6.2.4集群与简单测试
一 简介 Elasticsearch是一个高度可扩展的开源全文搜索和分析引擎.它允许您快速,近实时地存储,搜索和分析大量数据.它通常用作支持具有复杂搜索功能和需求的应用程序的底层引擎/技术. 下载地址 ...
- Zookeeper(一)CentOS7.5搭建Zookeeper3.4.12集群与命令行操作
一. 分布式安装部署 1.0 下载地址 官网首页: https://zookeeper.apache.org/ 下载地址: http://mirror.bit.edu.cn/apache/zookee ...
- centos7环境搭建Eureka-Server注册中心集群
目的:测试和线上使用这套独立的Eureka-Server注册中心集群,目前3台虚拟机集群,后续可直接修改配置文件进行新增或减少集群机器. 系统环境: Centos7x64 java8+(JDK1.8+ ...
- 在CentOS7下搭建Hadoop2.9.0集群
系统环境:CentOS 7 JDK版本:jdk-8u191-linux-x64 MYSQL版本:5.7.26 Hadoop版本:2.9.0 Hive版本:2.3.4 Host Name Ip User ...
随机推荐
- numpy取反操作符和Boolean类型
numpy~运算符和Boolean类型变量 觉得有用的话,欢迎一起讨论相互学习~Follow Me numpy中取反运算符~可以将Boolean类型值取反,这在使用boolean类型数组选择数组中固定 ...
- Linux服务器上使用curl命令发送报文
报文格式如下: curl -l -H "Content-type: application/json" -X POST -d 'postdata' http://172.20.10 ...
- Linux系统中连接使用NAS
在使用NAS时,需要先确定NAS上的NFS服务和SMB的服务都开启了: 然后需要用NAS上的用户去登录,这里用的是admin: # smbclient -L 192.168.1.40 -U admin ...
- 【重要】Nginx模块Lua-Nginx-Module学习笔记(三)Nginx + Lua + Redis 已安装成功(非openresty 方式安装)
源码地址:https://github.com/Tinywan/Lua-Nginx-Redis 一. 目标 使用Redis做分布式缓存:使用lua API来访问redis缓存:使用nginx向客户端提 ...
- How to Tell Science Stories with Maps
Reported Features How to Tell Science Stories with Maps August 25, 2015 Greg Miller This map, part ...
- 关于mysql 5.7版本“报[Err] 1093 - You can't specify target table 'XXX' for update in FROM clause”错误的bug
不同于oracle和sqlserver,mysql并不支持在更新某个表的数据时又查询了它,而查询的数据又做了更新的条件,因此我们需要使用如下的语句绕过: , notice_code ) a) ; 本地 ...
- Spyder之Object Inspector组件
Spyder之Object Inspector组件 最新版的Spyder已经把它修改为Help组件了. Quick access to documentation is a must for ever ...
- soj1011. Lenny's Lucky Lotto
1011. Lenny's Lucky Lotto Constraints Time Limit: 1 secs, Memory Limit: 32 MB Description Lenny like ...
- soj1010. Zipper
1010. Zipper Constraints Time Limit: 1 secs, Memory Limit: 32 MB Description Given three strings, yo ...
- jetty 热部署
1,在pom.xml文件中配置jetty插件的参数:scanIntervalSeconds <plugin> <groupId>org.mortbay.jetty</gr ...