centos7 下搭建hadoop2.9 分布式集群
首先说明,本文记录的是博主搭建的3节点的完全分布式hadoop集群的过程,环境是centos 7,1个nameNode,2个dataNode,如下:
1、首先,创建好3个Centos7的虚拟机,具体的操作可以参考网上其他教程,这个给个链接《windows环境安装VMware,并且安装CentOS7 虚拟机》
2、完成虚拟机的java环境的搭建,可以参考我的博客《centos7 安装jdk 1.8》
3、关闭或者禁用防火墙, systemctl stop firewalld.service 关闭防火墙;systemctl disable firewalld.service 关闭防火墙
firewall-cmd --state 查看状态

4、修改hosts文件,vim /etc/hosts ,注释原有的内容,加入如下内容,ip地址为你自己的虚拟机的IP地址:
192.168.10.128 master.hadoop
192.168.10.129 slave1.hadoop
192.168.10.130 slave2.hadoop
more /etc/hosts查看是否正确,需要重启后方能生效。重启命令 reboot now
此处可以添加ssh key,创建无密码的公钥
a、在master机器上输入 ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa 创建一个无密码的公钥,-t是类型的意思,dsa是生成的密钥类型,-P是密码,’’表示无密码,-f后是秘钥生成后保存的位置
b、在master机器上输入 cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys 将公钥id_dsa.pub添加进keys,这样就可以实现无密登陆ssh
c、在master机器上输入 ssh master 测试免密码登陆
d、在slave1.hadoop主机上执行 mkdir ~/.ssh
e、在slave2.hadoop主机上执行 mkdir ~/.ssh
f、在master机器上输入 scp ~/.ssh/authorized_keys root@slave1.hadoop:~/.ssh/authorized_keys 将主节点的公钥信息导入slave1.hadoop节点,导入时要输入一下slave1.hadoop机器的登陆密码
g、在master机器上输入 scp ~/.ssh/authorized_keys root@slave2.hadoop:~/.ssh/authorized_keys 将主节点的公钥信息导入slave2.hadoop节点,导入时要输入一下slave2.hadoop机器的登陆密码
h、在三台机器上分别执行 chmod ~/.ssh/authorized_keys 赋予密钥文件权限
i、在master节点上分别输入 ssh slave1.hadoop和 ssh slave2.hadoop测试是否配置ssh成功
5、进入home目录,mkdir hadoop 创建一个hadoop的文件夹。上传下载好的hadoop包到该目录,hadoop2.9下载地址;
http://hadoop.apache.org/->左边点Releases->点mirror site->点http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common->下载hadoop-2.9.0.tar.gz;
tar -zxvf hadoop-2.9.0.tar.gz 解压tar包
6、配置hadoop,此节点可暂时先配置128master,然后通过scp的方式复制到两个从节点
a、vim /home/hadoop/hadoop-2.9.0/etc/hadoop/core-site.xml,在<configuration>节点中增加如下内容:
<property>
<name>fs.default.name</name>
<value>hdfs://master.hadoop:</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value></value>
</property>
b、vim /home/hadoop/hadoop-2.9.0/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master.hadoop:</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
c、cp /home/hadoop/hadoop-2.9.0/etc/hadoop/mapred-site.xml.template /home/hadoop/hadoop-2.9.0/etc/hadoop/mapred-site.xml
vim /home/hadoop/hadoop-2.9.0/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>master.hadoop:</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master.hadoop:</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master.hadoop:</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>http://master.hadoop:</value>
</property>
</configuration>
d、vim /home/hadoop/hadoop-2.9.0/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property> <name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master.hadoop:</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master.hadoop:</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master.hadoop:</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master.hadoop:</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master.hadoop:</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master.hadoop</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value></value>
</property>
</configuration>
7、配置/home/hadoop/hadoop-2.9.0/etc/hadoop目录下hadoop.env.sh、yarn-env.sh的JAVA_HOME
取消JAVA_HOME的注释,设置为 export JAVA_HOME=/home/java/jdk1.8.0_11
8、配置/home/hadoop/hadoop-2.9.0/etc/hadoop目录下的slaves,删除默认的localhost,添加2个slave节点:
slave1.hadoop
slave2.hadoop
9、将master服务器上配置好的Hadoop复制到各个节点对应位置上,通过scp传送:
scp -r /home/hadoop 192.168.10.129:/home/
scp -r /home/hadoop 192.168.10.130:/home/
10、启动hadoop。在master节点启动hadoop服务,各个从节点会自动启动,进入/home/hadoop/hadoop-2.9.0/sbin/目录,hadoop的启动和停止都在master上进行;
a、初始化,输入命令:hdfs namenode -format
b、启动命令:start-all.sh

c、输入jps命令查看相关信息,master上截图如下:
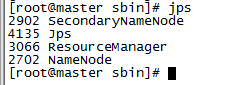
d、slave节点上输入jps查看:
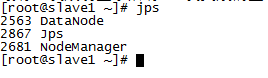
e、停止命令:stop-all.sh
11、访问,输入http://192.168.10.128:50070,看到如下界面:
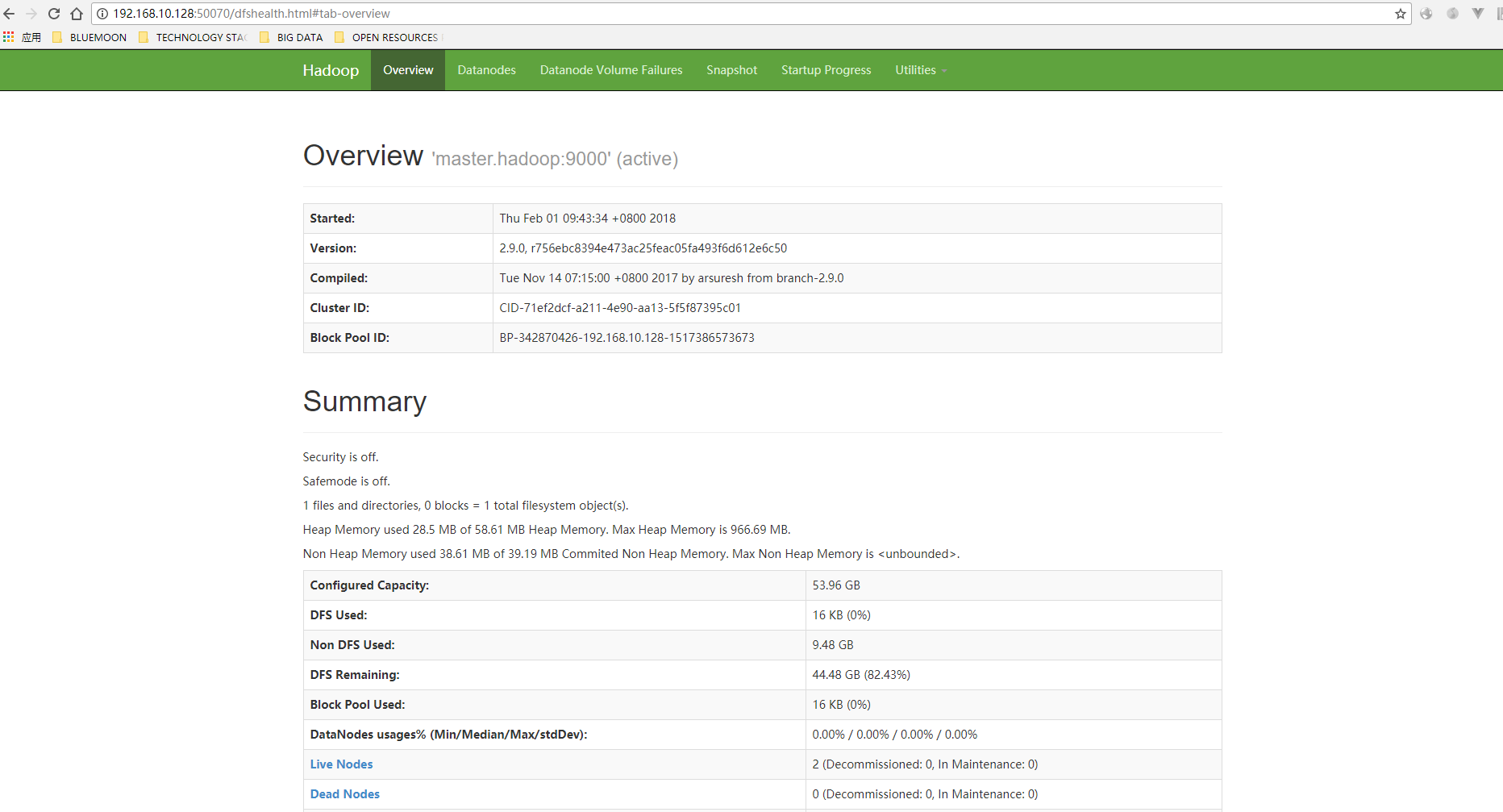
输入http://192.168.10.128:8088,看到如下界面:
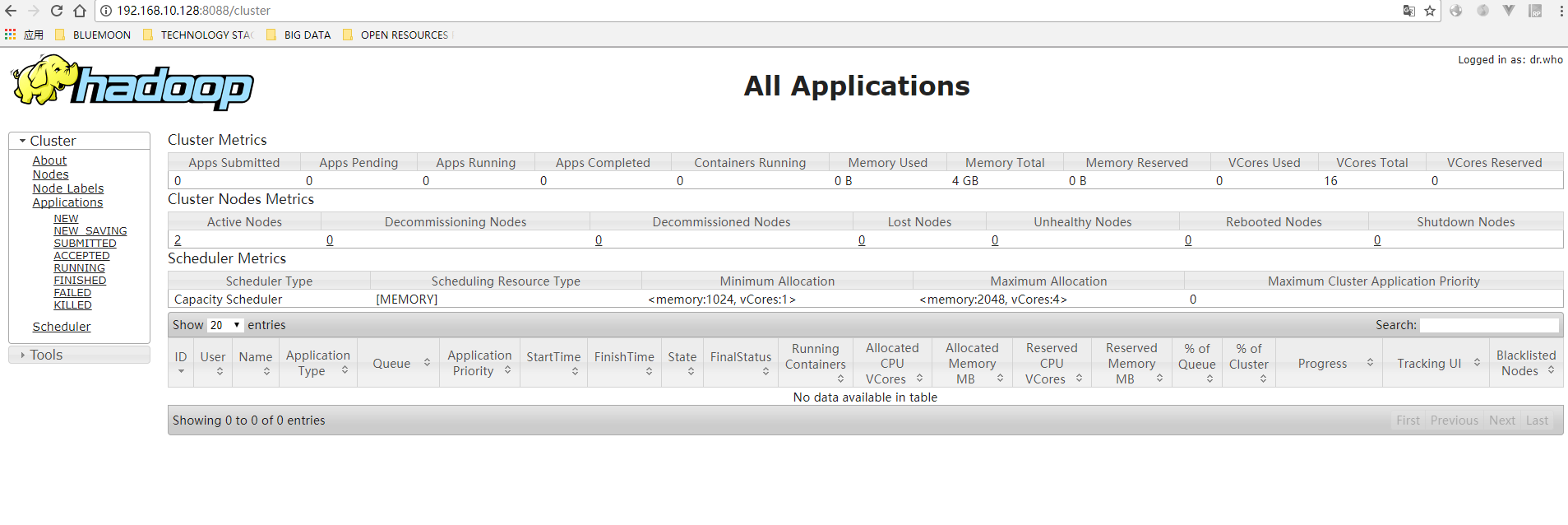 好了。如果以上都成功,那么基本上完成了hadoop集群的搭建;
好了。如果以上都成功,那么基本上完成了hadoop集群的搭建;

centos7 下搭建hadoop2.9 分布式集群的更多相关文章
- 在CentOS7下搭建Hadoop2.9.0集群
系统环境:CentOS 7 JDK版本:jdk-8u191-linux-x64 MYSQL版本:5.7.26 Hadoop版本:2.9.0 Hive版本:2.3.4 Host Name Ip User ...
- CentOS7.5搭建spark2.3.1集群
一 下载安装包 1 官方下载 官方下载地址:http://spark.apache.org/downloads.html 2 安装前提 Java8 安装成功 zookeeper 安 ...
- HBase(二)CentOS7.5搭建HBase1.2.6HA集群
一.安装前提 1.HBase 依赖于 HDFS 做底层的数据存储 2.HBase 依赖于 MapReduce 做数据计算 3.HBase 依赖于 ZooKeeper 做服务协调 4.HBase源码是j ...
- 『实践』VirtualBox 5.1.18+Centos 6.8+hadoop 2.7.3搭建hadoop完全分布式集群及基于HDFS的网盘实现
『实践』VirtualBox 5.1.18+Centos 6.8+hadoop 2.7.3搭建hadoop完全分布式集群及基于HDFS的网盘实现 1.基本设定和软件版本 主机名 ip 对应角色 mas ...
- Storm(二)CentOS7.5搭建Storm1.2.2集群
一.Storm的下载 官网下载地址:http://storm.apache.org/downloads.html 这里下载最新的版本storm1.2.2,进入之后选择一个镜像下载 二.Storm伪分布 ...
- Hadoop2.X分布式集群部署
本博文集群搭建没有实现Hadoop HA,详细文档在后续给出,本次只是先给出大概逻辑思路. (一)hadoop2.x版本下载及安装 Hadoop 版本选择目前主要基于三个厂商(国外)如下所示: 基于A ...
- Redis集群搭建,伪分布式集群,即一台服务器6个redis节点
Redis集群搭建,伪分布式集群,即一台服务器6个redis节点 一.Redis Cluster(Redis集群)简介 集群搭建需要的环境 二.搭建集群 2.1Redis的安装 2.2搭建6台redi ...
- 【web】 亿级Web系统搭建——单机到分布式集群
当一个Web系统从日访问量10万逐步增长到1000万,甚至超过1亿的过程中,Web系统承受的压力会越来越大,在这个过程中,我们会遇到很多的问题.为了解决这些性能压力带来问题,我们需要在Web系统架 ...
- 基于HBase0.98.13搭建HBase HA分布式集群
在hadoop2.6.0分布式集群上搭建hbase ha分布式集群.搭建hadoop2.6.0分布式集群,请参考“基于hadoop2.6.0搭建5个节点的分布式集群”.下面我们开始啦 1.规划 1.主 ...
随机推荐
- 总结Oracle8i 的UNDO表空间损坏(ORA-01092及ORA-00600【4193】)情况下的数据库不完全恢复的经历
服务器断电重启导致备份生产环境的恢复目录库无法进行启动,提示Ora-01092例程终止.强行断开连接 查看跟踪日志: Wed Jan 10 08:41:37 2018 Errors in file d ...
- JavaScript时间处理插件
摘要:代码返回的有两种时间格式 一种是/// 另外一种是---分割的 两个接收参数的说明 timestr 是接收的时间 mark是格式 默认返回的格式是/// 加上- 返回的格式是- ...
- Java学习笔记24(Integer类)
这里介绍基本数据类型包装类,Integer是int的包装类, 其他的基本数据类型的包装类的方法和Integer的方法几乎一致,会一种即可全会 基本数据类型包装类的特点:用于在基本数据类型和字符串之间进 ...
- JS CKEditor使用setData后绑定click事件
CKEditor使用setData()时会自动丢失初始时绑定的时间,在百度时发现有很多方法都不对. 近期在做项目的时候,由于客户需要,将原来的文本格式的textarea标签更改成富文本编辑器--CKE ...
- (3两个例子)从零开始的嵌入式图像图像处理(PI+QT+OpenCV)实战演练
从零开始的嵌入式图像图像处理(PI+QT+OpenCV)实战演练 1综述http://www.cnblogs.com/jsxyhelu/p/7907241.html2环境架设http://www.cn ...
- linux下安装ffmpeg
1. 首先安装系统编译环境 yum install -y automake autoconf libtool gcc gcc-c++ #CentOS 2. 编译所需源码包 #yasm:汇编器,新版 ...
- 利用jquery encoder解决XSS脚本注入所产生的问题
问题现象:前端接收到后台一个数据(其中包含html)标签,自动转译成html页面元素,且自动执行了脚本,造成了前端页面的阻塞 接受的后台数据为大量重复的如下代码 ");</script ...
- 转- 在ubuntu下安装Nginx
一. 安装包安装 1.1 安装Nginx $sudo apt-get install nginx Ubuntu安装之后的文件结构大致为: 所有的配置文件都在/etc/nginx下,并且每个虚拟主机已经 ...
- awvs的用法
awvs中的new scan新加一个漏洞扫描任务,web scanner是扫描漏洞的,我们可以看见高危到low的漏洞 awvs中的site Crawler是爬虫,他可以帮我们爬虫网站目录 awvs中的 ...
- 我们编写 React 组件的最佳实践
刚接触 React 的时候,在一个又一个的教程上面看到很多种编写组件的方法,尽管那时候 React 框架已经相当成熟,但是并没有一个固定的规则去规范我们去写代码. 在过去的一年里,我们在不断的完善我们 ...