sklearn 中的 Pipeline 机制
from sklearn.pipeline import Pipeline
- 1
管道机制在机器学习算法中得以应用的根源在于,参数集在新数据集(比如测试集)上的重复使用。
管道机制实现了对全部步骤的流式化封装和管理(streaming workflows with pipelines)。
注意:管道机制更像是编程技巧的创新,而非算法的创新。
接下来我们以一个具体的例子来演示sklearn库中强大的Pipeline用法:
1. 加载数据集
from pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import LabelEncoder
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/'
'breast-cancer-wisconsin/wdbc.data', header=None)
# Breast Cancer Wisconsin dataset
X, y = df.values[:, 2:], df.values[:, 1]
# y为字符型标签
# 使用LabelEncoder类将其转换为0开始的数值型
encoder = LabelEncoder()
y = encoder.fit_transform(y)
>>> encoder.transform(['M', 'B'])
array([1, 0])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.2, random_state=0)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
2. 构思算法的流程
可放在Pipeline中的步骤可能有:
- 特征标准化是需要的,可作为第一个环节
- 既然是分类器,classifier也是少不了的,自然是最后一个环节
- 中间可加上比如数据降维(PCA)
- 。。。
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
pipe_lr = Pipeline([('sc', StandardScaler()),
('pca', PCA(n_components=2)),
('clf', LogisticRegression(random_state=1))
])
pipe_lr.fit(X_train, y_train)
print('Test accuracy: %.3f' % pipe_lr.score(X_test, y_test))
# Test accuracy: 0.947
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Pipeline对象接受二元tuple构成的list,每一个二元 tuple 中的第一个元素为 arbitrary identifier string,我们用以获取(access)Pipeline object 中的 individual elements,二元 tuple 中的第二个元素是 scikit-learn与之相适配的transformer 或者 estimator。
Pipeline([('sc', StandardScaler()), ('pca', PCA(n_components=2)), ('clf', LogisticRegression(random_state=1))])
- 1
3. Pipeline执行流程的分析
Pipeline 的中间过程由scikit-learn相适配的转换器(transformer)构成,最后一步是一个estimator。比如上述的代码,StandardScaler和PCA transformer 构成intermediate steps,LogisticRegression 作为最终的estimator。
当我们执行 pipe_lr.fit(X_train, y_train)时,首先由StandardScaler在训练集上执行 fit和transform方法,transformed后的数据又被传递给Pipeline对象的下一步,也即PCA()。和StandardScaler一样,PCA也是执行fit和transform方法,最终将转换后的数据传递给 LosigsticRegression。整个流程如下图所示:
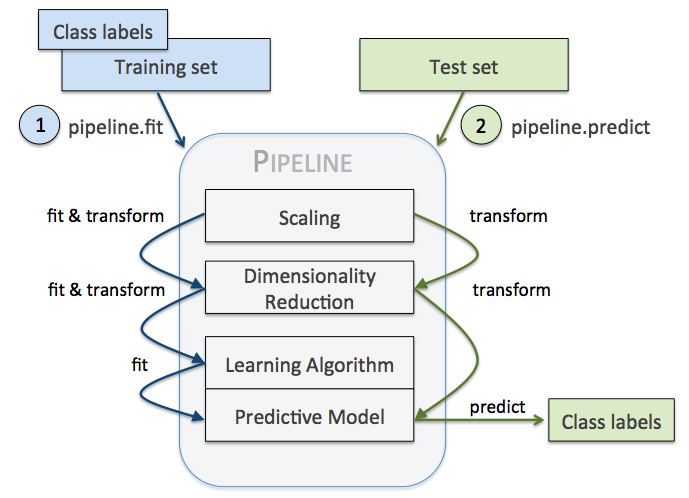
4. pipeline 与深度神经网络的multi-layers
只不过步骤(step)的概念换成了层(layer)的概念,甚至the last step 和 输出层的含义都是一样的。
只是抛出一个问题,是不是有那么一丢丢的相似性?
sklearn 中的 Pipeline 机制的更多相关文章
- sklearn 中的 Pipeline 机制 和FeatureUnion
一.pipeline的用法 pipeline可以用于把多个estimators级联成一个estimator,这么 做的原因是考虑了数据处理过程中一系列前后相继的固定流程,比如feature selec ...
- sklearn中的pipeline实际应用
前面提到,应用sklearn中的pipeline机制的高效性:本文重点讨论pipeline与网格搜索在机器学习实践中的结合运用: 结合管道和网格搜索以调整预处理步骤以及模型参数 一般地,sklearn ...
- sklearn中的Pipeline
在将sklearn中的模型持久化时,使用sklearn.pipeline.Pipeline(steps, memory=None)将各个步骤串联起来可以很方便地保存模型. 例如,首先对数据进行了PCA ...
- sklearn中的pipeline的创建与访问
前期博文提到管道(pipeline)在机器学习实践中的重要性以及必要性,本文则递进一步,探讨实际操作中管道的创建与访问. 已经了解到,管道本质上是一定数量的估计器连接而成的数据处理流,所以成功创建管道 ...
- 【笔记】多项式回归的思想以及在sklearn中使用多项式回归和pipeline
多项式回归以及在sklearn中使用多项式回归和pipeline 多项式回归 线性回归法有一个很大的局限性,就是假设数据背后是存在线性关系的,但是实际上,具有线性关系的数据集是相对来说比较少的,更多时 ...
- 【转】Netty那点事(三)Channel中的Pipeline
[原文]https://github.com/code4craft/netty-learning/blob/master/posts/ch3-pipeline.md Channel是理解和使用Nett ...
- sklearn中的交叉验证(Cross-Validation)
这个repo 用来记录一些python技巧.书籍.学习链接等,欢迎stargithub地址sklearn是利用python进行机器学习中一个非常全面和好用的第三方库,用过的都说好.今天主要记录一下sk ...
- sklearn中的投票法
投票法(voting)是集成学习里面针对分类问题的一种结合策略.基本思想是选择所有机器学习算法当中输出最多的那个类. 分类的机器学习算法输出有两种类型:一种是直接输出类标签,另外一种是输出类概率,使用 ...
- 决策树在sklearn中的实现
1 概述 1.1 决策树是如何工作的 1.2 构建决策树 1.2.1 ID3算法构建决策树 1.2.2 简单实例 1.2.3 ID3的局限性 1.3 C4.5算法 & CART算法 1.3.1 ...
随机推荐
- 1433. [ZJOI2009]假期的宿舍【二分图】
Description 学校放假了······有些同学回家了,而有些同学则有以前的好朋友来探访,那么住宿就是一个问题.比如A 和B都是学校的学生,A要回家,而C来看B,C与A不认识.我们假设每个人只能 ...
- 4719: [Noip2016]天天爱跑步
Time Limit: 40 Sec Memory Limit: 512 MB Submit: 1986 Solved: 752 [Submit][Status][Discuss] Descripti ...
- Eclipse的PHP插件PHPEclipse安装和使用
PHP有很多相当不错的开发工具,如Zend Studio.NetBeans.phpdesigner等,但对于习惯Java编程的程序猿们来说,最常用的还要属Eclipse.那么Eclipse能用于PHP ...
- linux 的常用命令---------第一阶段
ls -a 列出所有的文件,包括以 . 开头的隐藏文件 ls -d 列出目录本身,并不包含目录中的文件 ls -h 人类易读 ls -h 长输出 man 帮助使用手册 ...
- Win32 HTTP Download
头文件HTTPClient.h: #pragma once #ifndef HTTPClient_H_ #define HTTPClient_H_ #include <string> us ...
- ddt Ui 案例2
准备用例文件:testcase1.py testcase2.py import ddt import unittest from HTMLTestRunner import HTMLTestRunne ...
- JavaScript小例子
1. alert.html <html> <head> <title></title> <script type="text/javas ...
- HDU 1025 LIS二分优化
题目链接: acm.hdu.edu.cn/showproblem.php?pid=1025 Constructing Roads In JGShining's Kingdom Time Limit: ...
- gattAttribute_t 含义 中文解释
1. gattAttribute_t 是一个结构体数据类型,里面存放了各种类型的数据. 现在 看看 TI 是怎么描述的,如下: /** * @brief GATT Attribute form ...
- mysql/mariadb学习记录——查询2
Alias——使用一个列名别名AS 关键字: mysql> select sno as studentId,sname as studentName from student; +------- ...