hadoop环境搭建-完全分布式
用于测试,我用4台虚拟机搭建成了hadoop结构
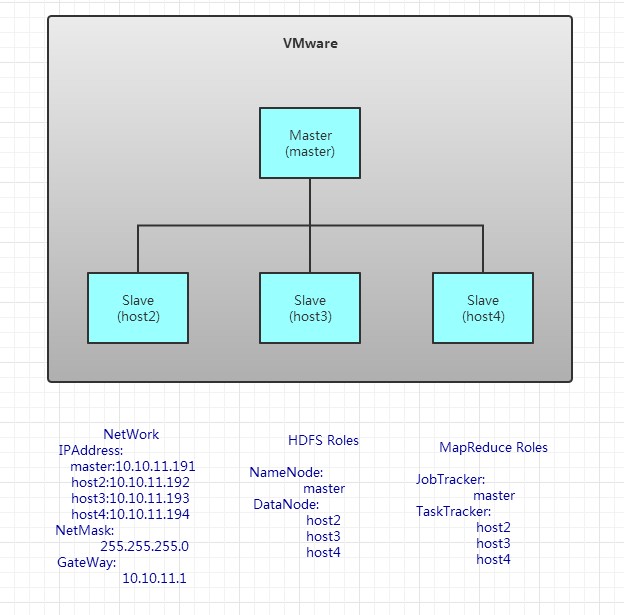
我用了两个台式机。一个xp系统,一个win7系统。每台电脑装两个虚拟机,要不然内存就满了。
1、安装虚拟机环境
Vmware,收费产品,占内存较大。
或
Oracle的VirtualBox,开源产品,占内存较小,但安装ubuntu过程中,重启会出错。
我选Vmware。
2、安装操作系统
Centos,红帽开源版,接近于生产环境。
Ubuntu,操作简单,方便,界面友好。
我选Ubuntu12.10.X 32位
3、安装一些常用的软件
在每台linux虚拟机上,安装:vim,ssh
sudo apt-get install vim
sudo apt-get install ssh
在客户端,也就是win7上,安装SecureCRT,Winscp或putty,这几个程序,都是依靠ssh服务来操作的,所以前提必须安装ssh服务。
service ssh status 查看ssh状态。如果关闭使用service ssh start开启服务。
SecureCRT,可以通过ssh远程访问linux虚拟机。
winSCP或putty,可以从win7向linux上传文件。
4、修改主机名和网络配置
主机名分别为:master,host2,host3,host4。
sudo vim /etc/hostname
网络配置,包括ip地址,子网掩码,DNS服务器。如上图所示。
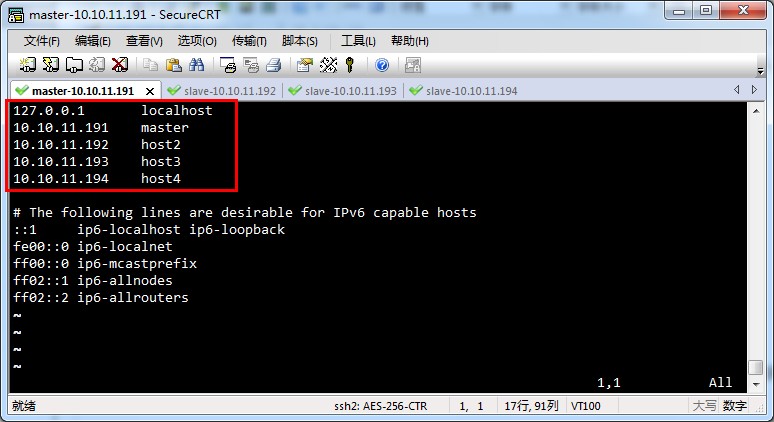
5、修改/etc/hosts文件。
修改每台电脑的hosts文件。
hosts文件和windows上的功能是一样的。存储主机名和ip地址的映射。
在每台linux上,sudo vim /etc/hosts 编写hosts文件。将主机名和ip地址的映射填写进去。编辑完后,结果如下:
6、配置ssh,实现无密码登陆
无密码登陆,效果也就是在master上,通过 ssh host2 或 ssh host3 或 ssh host4 就可以登陆到对方计算机上。而且不用输入密码。
四台虚拟机上,使用 ssh-keygen -t rsa 一路按回车就行了。
刚才都作甚了呢?主要是设置ssh的密钥和密钥的存放路径。 路径为~/.ssh下。
打开~/.ssh 下面有三个文件
authorized_keys,已认证的keys
id_rsa,私钥
id_rsa.pub,公钥 三个文件。
下面就是关键的地方了,(我们要做ssh认证。进行下面操作前,可以先搜关于认证和加密区别以及各自的过程。)
①在master上将公钥放到authorized_keys里。命令:sudo cat id_rsa.pub >> authorized_keys
②将master上的authorized_keys放到其他linux的~/.ssh目录下。
命令:sudo scp authorized_keys hadoop@10.10.11.192:~/.ssh
sudo scp authorized_keys 远程主机用户名@远程主机名或ip:存放路径。
③修改authorized_keys权限,命令:chmod 644 authorized_keys
④测试是否成功
ssh host2 输入用户名密码,然后退出,再次ssh host2不用密码,直接进入系统。这就表示成功了。
7、上传jdk,并配置环境变量。
通过winSCP将文件上传到linux中。将文件放到/usr/lib/java中,四个linux都要操作。
解压缩:tar -zxvf jdk1.7.0_21.tar
设置环境变量 sudo vim ~/.bashrc
在最下面添加:
export JAVA_HOME = /usr/lib/java/jdk1.7.0_21
export PATH = $JAVA_HOME/bin:$PATH
修改完后,用source ~/.bashrc让配置文件生效。
8、上传hadoop,配置hadoop
通过winSCP,上传hadoop,到/usr/local/下,解压缩tar -zxvf hadoop1.2.1.tar
再重命名一下,sudo mv hadoop1.2.1 hadoop
这样目录就变成/usr/local/hadoop
①修改环境变量,将hadoop加进去(最后四个linux都操作一次)
sudo vim ~/.bashrc
export HADOOP_HOME = /usr/local/hadoop
export PATH = $JAVA_HOme/bin:$HADOOP_HOME/bin:$PATH
修改完后,用source ~/.bashrc让配置文件生效。
②修改/usr/local/hadoop/conf下配置文件
hadoop-env.sh,
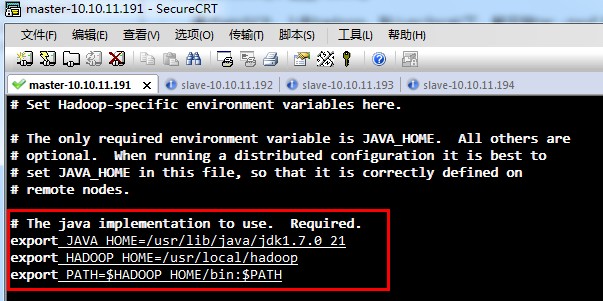
(上面这张图片,有一些问题,只export JAVA_HOME进去就可以了,不用export HADOOP_HOME和PATH了 )
core-site.xml,
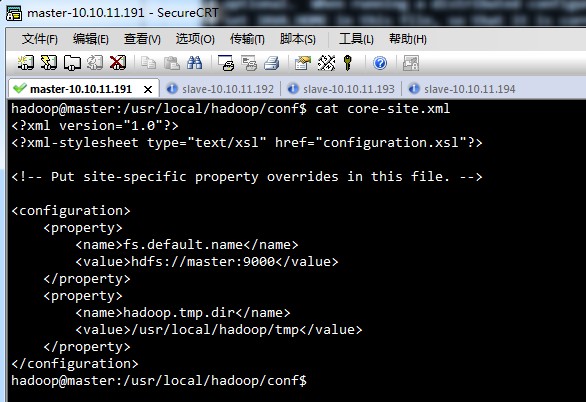
hdfs-site.xml,
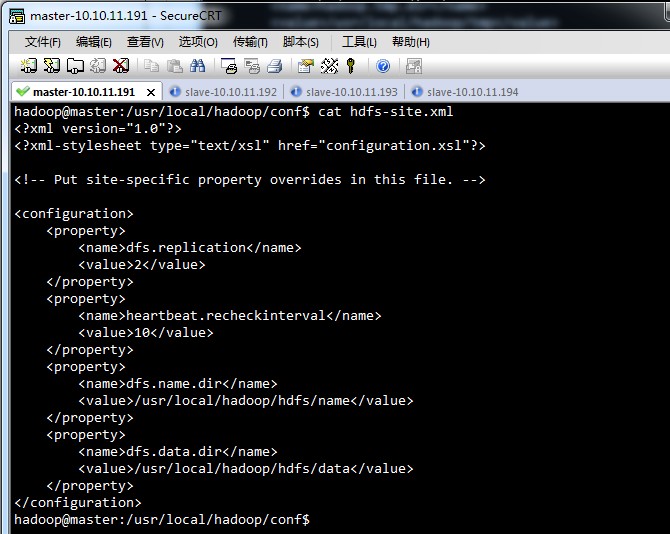
mapred-site.xml,

master,
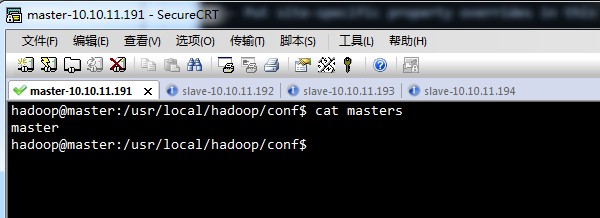
slave,

上面的hadoop-env.sh,core-site.xml,mapred-site.xml,hdfs-site.xml,master,slave几个文件,在四台linux中都是一样的。
配置完一台电脑后,可以将hadoop包,直接拷贝到其他电脑上。
③最后要记得,将hadoop的用户加进去,命令为
sudo chown -R hadoop:hadoop hadoop
sudo chown -R 用户名@用户组 目录名
④让hadoop配置生效
source hadoop-env.sh
⑤格式化namenode,只格式一次
hadoop namenode -format
⑥启动hadoop
切到/usr/local/hadoop/bin目录下,执行 start-all.sh启动所有程序
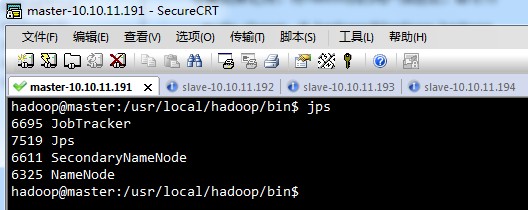
⑦查看进程,是否启动
jps
master,
host2,
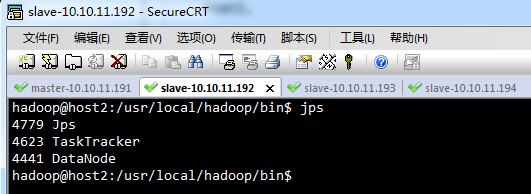
host3,host4,的显示结果,与host2相同。
hadoop环境搭建-完全分布式的更多相关文章
- hadoop环境搭建之关于NAT模式静态IP的设置 ---VMware12+CentOs7
很久没有更新了,主要是没有时间,今天挤出时间验证了一下,果然还是有些问题的,不过已经解决了,就发上来吧. PS:小豆腐看仔细了哦~ 关于hadoop环境搭建,从单机模式,到伪分布式,再到完全分布式,我 ...
- Storm环境搭建(分布式集群)
作为流计算的开篇,笔者首先给出storm的安装和部署,storm的第二篇,笔者将详细的介绍storm的工作原理.下边直接上干货,跟笔者的步伐一块儿安装storm. 原文链接:Storm环境搭建(分布式 ...
- 大数据学习之Hadoop环境搭建
一.Hadoop的优势 1)高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理. 2)高扩展性:在集群间分配任务数据,可方便的 ...
- Hadoop环境搭建、启动和管理界面查看
一.hadoop环境搭建: 1. hadoop 6个核心配置文件的作用:core-site.xml:核心配置文件,主要定义了我们文件访问的格式 hdfs://hadoop-env.sh:主要配置我们的 ...
- 转 史上最详细的Hadoop环境搭建
GitChat 作者:鸣宇淳 原文:史上最详细的Hadoop环境搭建 关注公众号:GitChat 技术杂谈,一本正经的讲技术 [不要错过文末活动哦] 前言 Hadoop在大数据技术体系中的地位至关重要 ...
- Hadoop环境搭建(centos)
Hadoop环境搭建(centos) 本平台密码83953588abc 配置Java环境 下载JDK(本实验从/cgsrc 文件中复制到指定目录) mkdir /usr/local/java cp / ...
- 【转】RHadoop实践系列之一:Hadoop环境搭建
RHadoop实践系列之一:Hadoop环境搭建 RHadoop实践系列文章,包含了R语言与Hadoop结合进行海量数据分析.Hadoop主要用来存储海量数据,R语言完成MapReduce 算法,用来 ...
- eclipse工具下hadoop环境搭建
eclipse工具下hadoop环境搭建: window10操作系统中搭建eclipse64开发系统,配置hadoop的eclipse插件,让eclipse可以查看Hdfs中的文件内容. ...
- Ubuntu中Hadoop环境搭建
Ubuntu中Hadoop环境搭建 JDK安装 方法一:通过命令行直接安装(不建议) 有两种java可以安装oracle-java8-installer以及openjdk (1)安装oracle-ja ...
随机推荐
- android设置横屏和竖屏的方法
方法一:在AndroidManifest.xml中配置 假设不想让软件在横竖屏之间切换,最简单的办法就是在项目的AndroidManifest.xml中找到你所指定的activity中加上androi ...
- Discuz常见大问题-如何DIY一个独立页面
首先参考Discuz如何自定义单个页面的文章,确保你已经能做一个"关于我们"这种纯HTML静态页面(只有文字和静态图片描述).其次参考下面的文件修改原来的htm文件 注意我用红色标 ...
- PHP高级教程-文件
PHP 文件处理 fopen() 函数用于在 PHP 中打开文件. 打开文件 fopen() 函数用于在 PHP 中打开文件. 此函数的第一个参数含有要打开的文件的名称,第二个参数规定了使用哪种模式来 ...
- 每日一句英语:怎样回答美国人的How is it going问候语?
和中国人"吃了吗"是一个性质,本质上仅仅是个话题的起始点,而不是真的想知道你吃了没有. 美国人打招呼有几种方式: 不太熟的人:How are you? 一 般说 pretty go ...
- MySQL auto_increment_increment 和 auto_increment_offset
参考这一篇文章:(不过我对这一篇文章有异议) http://blog.csdn.net/leshami/article/details/39779509 1:搭建测试环境 create table t ...
- 〖Windows〗zigbee实验之cygwin编译tinyos.jar编译出错的解决方法
1. 使用的cygwin安装包下载地址:cygwin-files.zip 2. 使用的一些rpm安装包的下载地址:cygwin_cc2430_rpms.zip 3. cygwin的默认安装目录是:C: ...
- CMake 基本用法--写CMakeList.txt
http://techbase.kde.org/Development/Tutorials/CMake_(zh_CN) http://www.cmake.org/Wiki/CMake 这一章将从软件开 ...
- PLY格式介绍
PLY是一种电脑档案格式,全名为多边形档案(Polygon File Format)或 斯坦福三角形档案(Stanford Triangle Format). 史丹佛大学的 The Digital ...
- Jquery.getJSON的缓存问题的处理方法
$.getJSON()存在缓存问题,如果其调用的url之前曾经调用过的话,回调函数就会直接在缓存里取得想要得值,而不是进入到后台 在项目中遇到一个问题,在火狐下,$.getJSON();请求数据一 ...
- iOS UIKit Dynamics入门 UIKit动力学,实现重力、连接、碰撞、悬挂等动画效果
本文为转载文章 版权归原文所有 什么是UIKit动力学(UIKit Dynamics) 其实就是UIKit的一套动画和交互体系.我们现在进行UI动画基本都是使用CoreAnimation或者UIVie ...