ZooKeeper学习之路 (九)利用ZooKeeper搭建Hadoop的HA集群
Hadoop HA 原理概述
为什么会有 hadoop HA 机制呢?
HA:High Available,高可用
在Hadoop 2.0之前,在HDFS 集群中NameNode 存在单点故障 (SPOF:A Single Point of Failure)。 对于只有一个 NameNode 的集群,如果 NameNode 机器出现故障(比如宕机或是软件、硬件 升级),那么整个集群将无法使用,直到 NameNode 重新启动
那如何解决呢?
HDFS 的 HA 功能通过配置 Active/Standby 两个 NameNodes 实现在集群中对 NameNode 的 热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方 式将 NameNode 很快的切换到另外一台机器。
在一个典型的 HDFS(HA) 集群中,使用两台单独的机器配置为 NameNodes 。在任何时间点, 确保 NameNodes 中只有一个处于 Active 状态,其他的处在 Standby 状态。其中 ActiveNameNode 负责集群中的所有客户端操作,StandbyNameNode 仅仅充当备机,保证一 旦 ActiveNameNode 出现问题能够快速切换。
为了能够实时同步 Active 和 Standby 两个 NameNode 的元数据信息(实际上 editlog),需提 供一个共享存储系统,可以是 NFS、QJM(Quorum Journal Manager)或者 Zookeeper,Active Namenode 将数据写入共享存储系统,而 Standby 监听该系统,一旦发现有新数据写入,则 读取这些数据,并加载到自己内存中,以保证自己内存状态与 Active NameNode 保持基本一 致,如此这般,在紧急情况下 standby 便可快速切为 active namenode。为了实现快速切换, Standby 节点获取集群的最新文件块信息也是很有必要的。为了实现这一目标,DataNode 需 要配置 NameNodes 的位置,并同时给他们发送文件块信息以及心跳检测。

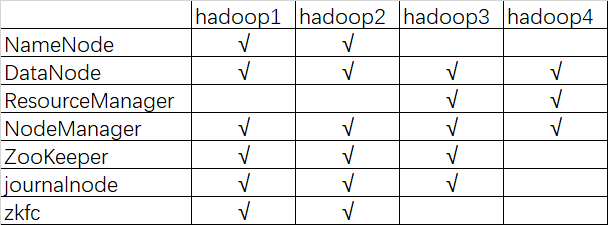
集群规划
描述:hadoop HA 集群的搭建依赖于 zookeeper,所以选取三台当做 zookeeper 集群 ,总共准备了四台主机,分别是 hadoop1,hadoop2,hadoop3,hadoop4 其中 hadoop1 和 hadoop2 做 namenode 的主备切换,hadoop3 和 hadoop4 做 resourcemanager 的主备切换
四台机器
集群服务器准备
1、 修改主机名
2、 修改 IP 地址
3、 添加主机名和 IP 映射
4、 添加普通用户 hadoop 用户并配置 sudoer 权限
5、 设置系统启动级别
6、 关闭防火墙/关闭 Selinux
7、 安装 JDK 两种准备方式:
1、 每个节点都单独设置,这样比较麻烦。线上环境可以编写脚本实现
2、 虚拟机环境可是在做完以上 7 步之后,就进行克隆
3、 然后接着再给你的集群配置 SSH 免密登陆和搭建时间同步服务
8、 配置 SSH 免密登录
9、 同步服务器时间
具体操作可以参考普通分布式搭建过程http://www.cnblogs.com/qingyunzong/p/8496127.html
集群安装
1、安装 Zookeeper 集群
具体安装步骤参考之前的文档http://www.cnblogs.com/qingyunzong/p/8619184.html
2、安装 hadoop 集群
(1)获取安装包
从官网或是镜像站下载
http://mirrors.hust.edu.cn/apache/
(2)上传解压缩
[hadoop@hadoop1 ~]$ ls
apps hadoop-2.7.-centos-6.7.tar.gz movie2.jar users.dat zookeeper.out
data log output2 zookeeper-3.4..tar.gz
[hadoop@hadoop1 ~]$ tar -zxvf hadoop-2.7.5-centos-6.7.tar.gz -C apps/
(3)修改配置文件
配置文件目录:/home/hadoop/apps/hadoop-2.7.5/etc/hadoop
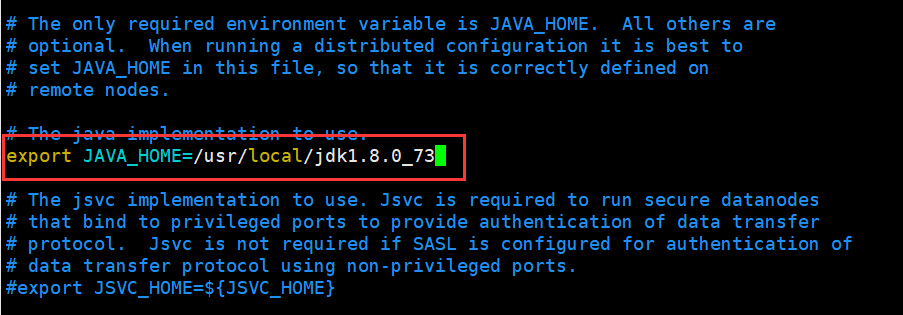
修改 hadoop-env.sh文件
[hadoop@hadoop1 ~]$ cd apps/hadoop-2.7.5/etc/hadoop/
[hadoop@hadoop1 hadoop]$ echo $JAVA_HOME
/usr/local/jdk1..0_73
[hadoop@hadoop1 hadoop]$ vi hadoop-env.sh
修改core-site.xml
[hadoop@hadoop1 hadoop]$ vi core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为myha01 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://myha01/</value>
</property> <!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/hadoopdata/</value>
</property> <!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181,hadoop4:2181</value>
</property> <!-- hadoop链接zookeeper的超时时长设置 -->
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>1000</value>
<description>ms</description>
</property>
</configuration>
修改hdfs-site.xml
[hadoop@hadoop1 hadoop]$ vi hdfs-site.xml
<configuration>
<!-- 指定副本数 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 配置namenode和datanode的工作目录-数据存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/hadoopdata/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/hadoopdata/dfs/data</value>
</property>
<!-- 启用webhdfs -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--指定hdfs的nameservice为myha01,需要和core-site.xml中的保持一致
dfs.ha.namenodes.[nameservice id]为在nameservice中的每一个NameNode设置唯一标示符。
配置一个逗号分隔的NameNode ID列表。这将是被DataNode识别为所有的NameNode。
例如,如果使用"myha01"作为nameservice ID,并且使用"nn1"和"nn2"作为NameNodes标示符
-->
<property>
<name>dfs.nameservices</name>
<value>myha01</value>
</property>
<!-- myha01下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.myha01</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.myha01.nn1</name>
<value>hadoop1:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.myha01.nn1</name>
<value>hadoop1:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.myha01.nn2</name>
<value>hadoop2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.myha01.nn2</name>
<value>hadoop2:50070</value>
</property>
<!-- 指定NameNode的edits元数据的共享存储位置。也就是JournalNode列表
该url的配置格式:qjournal://host1:port1;host2:port2;host3:port3/journalId
journalId推荐使用nameservice,默认端口号是:8485 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/myha01</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/data/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.myha01</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.ms</name>
<value>60000</value>
</property>
</configuration>
修改mapred-site.xml
[hadoop@hadoop1 hadoop]$ cp mapred-site.xml.template mapred-site.xml
[hadoop@hadoop1 hadoop]$ vi mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> <!-- 指定mapreduce jobhistory地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property> <!-- 任务历史服务器的web地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
</configuration>
修改yarn-site.xml
[hadoop@hadoop1 hadoop]$ vi yarn-site.xml
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property> <!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property> <!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property> <!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop3</value>
</property> <property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop4</value>
</property> <!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property> <property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property> <property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property> <!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property> <!-- 制定resourcemanager的状态信息存储在zookeeper集群上 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
修改slaves
[hadoop@hadoop1 hadoop]$ vi slaves
hadoop1
hadoop2
hadoop3
hadoop4
(4)将hadoop安装包分发到其他集群节点
重点强调: 每台服务器中的hadoop安装包的目录必须一致, 安装包的配置信息还必须保持一致
重点强调: 每台服务器中的hadoop安装包的目录必须一致, 安装包的配置信息还必须保持一致
重点强调: 每台服务器中的hadoop安装包的目录必须一致, 安装包的配置信息还必须保持一致
[hadoop@hadoop1 apps]$ scp -r hadoop-2.7.5/ hadoop2:$PWD
[hadoop@hadoop1 apps]$ scp -r hadoop-2.7.5/ hadoop3:$PWD
[hadoop@hadoop1 apps]$ scp -r hadoop-2.7.5/ hadoop4:$PWD
(5)配置Hadoop环境变量
千万注意:
1、如果你使用root用户进行安装。 vi /etc/profile 即可 系统变量
2、如果你使用普通用户进行安装。 vi ~/.bashrc 用户变量
本人是用的hadoop用户安装的
[hadoop@hadoop1 ~]$ vi .bashrc
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.7.
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
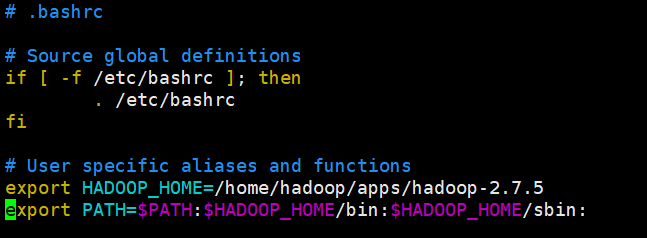
使环境变量生效
[hadoop@hadoop1 bin]$ source ~/.bashrc
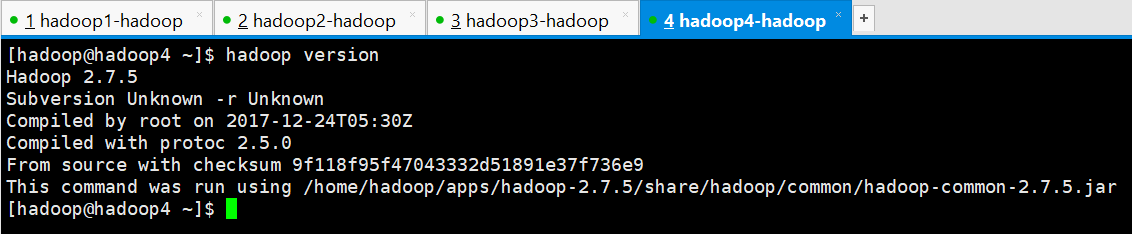
(6)查看hadoop版本
[hadoop@hadoop4 ~]$ hadoop version
Hadoop 2.7.
Subversion Unknown -r Unknown
Compiled by root on --24T05:30Z
Compiled with protoc 2.5.
From source with checksum 9f118f95f47043332d51891e37f736e9
This command was run using /home/hadoop/apps/hadoop-2.7./share/hadoop/common/hadoop-common-2.7..jar
[hadoop@hadoop4 ~]$
Hadoop HA集群的初始化
重点强调:一定要按照以下步骤逐步进行操作
重点强调:一定要按照以下步骤逐步进行操作
重点强调:一定要按照以下步骤逐步进行操作
1、启动ZooKeeper
启动4台服务器上的zookeeper服务
hadoop1
[hadoop@hadoop1 conf]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4./bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop1 conf]$ jps
Jps
2647 QuorumPeerMain
[hadoop@hadoop1 conf]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4./bin/../conf/zoo.cfg
Mode: follower
[hadoop@hadoop1 conf]$
hadoop2
[hadoop@hadoop2 conf]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4./bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop2 conf]$ jps
2592 QuorumPeerMain
Jps
[hadoop@hadoop2 conf]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4./bin/../conf/zoo.cfg
Mode: follower
[hadoop@hadoop2 conf]$
hadoop3
[hadoop@hadoop3 conf]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4./bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop3 conf]$ jps
16612 QuorumPeerMain
Jps
[hadoop@hadoop3 conf]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4./bin/../conf/zoo.cfg
Mode: leader
[hadoop@hadoop3 conf]$
hadoop4
[hadoop@hadoop4 conf]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4./bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop4 conf]$ jps
Jps
3567 QuorumPeerMain
[hadoop@hadoop4 conf]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4./bin/../conf/zoo.cfg
Mode: observer
[hadoop@hadoop4 conf]$
2、在你配置的各个journalnode节点启动该进程
按照之前的规划,我的是在hadoop1、hadoop2、hadoop3上进行启动,启动命令如下
hadoop1
[hadoop@hadoop1 conf]$ hadoop-daemon.sh start journalnode
starting journalnode, logging to /home/hadoop/apps/hadoop-2.7./logs/hadoop-hadoop-journalnode-hadoop1.out
[hadoop@hadoop1 conf]$ jps
JournalNode
Jps
QuorumPeerMain
[hadoop@hadoop1 conf]$
hadoop2
[hadoop@hadoop2 conf]$ hadoop-daemon.sh start journalnode
starting journalnode, logging to /home/hadoop/apps/hadoop-2.7./logs/hadoop-hadoop-journalnode-hadoop2.out
[hadoop@hadoop2 conf]$ jps
QuorumPeerMain
JournalNode
Jps
[hadoop@hadoop2 conf]$
hadoop3
[hadoop@hadoop3 conf]$ hadoop-daemon.sh start journalnode
starting journalnode, logging to /home/hadoop/apps/hadoop-2.7./logs/hadoop-hadoop-journalnode-hadoop3.out
[hadoop@hadoop3 conf]$ jps
QuorumPeerMain
JournalNode
Jps
[hadoop@hadoop3 conf]$
3、格式化namenode
先选取一个namenode(hadoop1)节点进行格式化
[hadoop@hadoop1 ~]$ hadoop namenode -format
[hadoop@hadoop1 ~]$ hadoop namenode -format
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it. // :: INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hadoop1/192.168.123.102
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.7.5
STARTUP_MSG: classpath = /home/hadoop/apps/hadoop-2.7.5/etc/hadoop:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/paranamer-2.3.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/httpclient-4.2.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jets3t-0.9.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-net-3.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/apacheds-i18n-2.0.0-M15.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jetty-sslengine-6.1.26.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jetty-6.1.26.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-math3-3.1.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jsr305-3.0.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jsch-0.1.54.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-cli-1.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jsp-api-2.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/hadoop-auth-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/servlet-api-2.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/mockito-all-1.8.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/zookeeper-3.4.6.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jackson-core-asl-1.9.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-io-2.4.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-logging-1.1.3.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jaxb-api-2.2.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jersey-server-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/log4j-1.2.17.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/guava-11.0.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jersey-json-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/xz-1.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-lang-2.6.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/gson-2.2.4.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/httpcore-4.2.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-compress-1.4.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-httpclient-3.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jettison-1.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/slf4j-api-1.7.10.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/api-asn1-api-1.0.0-M20.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/api-util-1.0.0-M20.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/xmlenc-0.52.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/hadoop-annotations-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-beanutils-core-1.8.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-codec-1.4.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/asm-3.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/curator-framework-2.7.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/curator-client-2.7.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-digester-1.8.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/activation-1.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jackson-xc-1.9.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-beanutils-1.7.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jetty-util-6.1.26.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/stax-api-1.0-2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/avro-1.7.4.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jersey-core-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/junit-4.11.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/netty-3.6.2.Final.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-collections-3.2.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/hamcrest-core-1.3.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/curator-recipes-2.7.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-configuration-1.6.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/snappy-java-1.0.4.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/hadoop-common-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/hadoop-nfs-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/hadoop-common-2.7.5-tests.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/jackson-mapper-asl-1.9.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/xercesImpl-2.9.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/jetty-6.1.26.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/jsr305-3.0.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/servlet-api-2.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/netty-all-4.0.23.Final.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/jackson-core-asl-1.9.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/commons-io-2.4.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/jersey-server-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/guava-11.0.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/leveldbjni-all-1.8.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/xml-apis-1.3.04.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/xmlenc-0.52.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/commons-codec-1.4.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/asm-3.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/htrace-core-3.1.0-incubating.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/jetty-util-6.1.26.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/jersey-core-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/netty-3.6.2.Final.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/hadoop-hdfs-nfs-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/hadoop-hdfs-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/hadoop-hdfs-2.7.5-tests.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jackson-mapper-asl-1.9.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jetty-6.1.26.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jsr305-3.0.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jaxb-impl-2.2.3-1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/guice-servlet-3.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/commons-cli-1.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/servlet-api-2.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/zookeeper-3.4.6.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jackson-core-asl-1.9.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/commons-io-2.4.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/zookeeper-3.4.6-tests.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/commons-logging-1.1.3.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jaxb-api-2.2.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jersey-server-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/log4j-1.2.17.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/aopalliance-1.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/guava-11.0.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jersey-json-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/javax.inject-1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/xz-1.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/commons-lang-2.6.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/leveldbjni-all-1.8.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/commons-compress-1.4.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jersey-client-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jersey-guice-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jettison-1.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/commons-codec-1.4.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/protobuf-java-2.5.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/guice-3.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/asm-3.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/activation-1.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jackson-xc-1.9.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jetty-util-6.1.26.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/stax-api-1.0-2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jersey-core-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/netty-3.6.2.Final.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jackson-jaxrs-1.9.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/commons-collections-3.2.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-client-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-server-tests-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-common-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-api-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-server-sharedcachemanager-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-server-common-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-registry-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/paranamer-2.3.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/jackson-mapper-asl-1.9.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/guice-servlet-3.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/jackson-core-asl-1.9.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/commons-io-2.4.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/jersey-server-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/log4j-1.2.17.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/aopalliance-1.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/javax.inject-1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/xz-1.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/leveldbjni-all-1.8.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/commons-compress-1.4.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/jersey-guice-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/hadoop-annotations-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/protobuf-java-2.5.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/guice-3.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/asm-3.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/avro-1.7.4.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/jersey-core-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/junit-4.11.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/netty-3.6.2.Final.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/hamcrest-core-1.3.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/snappy-java-1.0.4.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.5-tests.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/contrib/capacity-scheduler/*.jar:/home/hadoop/apps/hadoop-2.7.5/contrib/capacity-scheduler/*.jar
STARTUP_MSG: build = Unknown -r Unknown; compiled by 'root' on 2017-12-24T05:30Z
STARTUP_MSG: java = 1.8.0_73
************************************************************/
// :: INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
// :: INFO namenode.NameNode: createNameNode [-format]
// :: WARN common.Util: Path /home/hadoop/data/hadoopdata/dfs/name should be specified as a URI in configuration files. Please update hdfs configuration.
// :: WARN common.Util: Path /home/hadoop/data/hadoopdata/dfs/name should be specified as a URI in configuration files. Please update hdfs configuration.
Formatting using clusterid: CID-5fa14c27-b311-4a35--f32749a3c7c5
// :: INFO namenode.FSNamesystem: No KeyProvider found.
// :: INFO namenode.FSNamesystem: fsLock is fair: true
// :: INFO namenode.FSNamesystem: Detailed lock hold time metrics enabled: false
// :: INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit=
// :: INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true
// :: INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to :::00.000
// :: INFO blockmanagement.BlockManager: The block deletion will start around 三月 ::
// :: INFO util.GSet: Computing capacity for map BlocksMap
// :: INFO util.GSet: VM type = -bit
// :: INFO util.GSet: 2.0% max memory 966.7 MB = 19.3 MB
// :: INFO util.GSet: capacity = ^ = entries
// :: INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false
// :: INFO blockmanagement.BlockManager: defaultReplication =
// :: INFO blockmanagement.BlockManager: maxReplication =
// :: INFO blockmanagement.BlockManager: minReplication =
// :: INFO blockmanagement.BlockManager: maxReplicationStreams =
// :: INFO blockmanagement.BlockManager: replicationRecheckInterval =
// :: INFO blockmanagement.BlockManager: encryptDataTransfer = false
// :: INFO blockmanagement.BlockManager: maxNumBlocksToLog =
// :: INFO namenode.FSNamesystem: fsOwner = hadoop (auth:SIMPLE)
// :: INFO namenode.FSNamesystem: supergroup = supergroup
// :: INFO namenode.FSNamesystem: isPermissionEnabled = true
// :: INFO namenode.FSNamesystem: Determined nameservice ID: myha01
// :: INFO namenode.FSNamesystem: HA Enabled: true
// :: INFO namenode.FSNamesystem: Append Enabled: true
// :: INFO util.GSet: Computing capacity for map INodeMap
// :: INFO util.GSet: VM type = -bit
// :: INFO util.GSet: 1.0% max memory 966.7 MB = 9.7 MB
// :: INFO util.GSet: capacity = ^ = entries
// :: INFO namenode.FSDirectory: ACLs enabled? false
// :: INFO namenode.FSDirectory: XAttrs enabled? true
// :: INFO namenode.FSDirectory: Maximum size of an xattr:
// :: INFO namenode.NameNode: Caching file names occuring more than times
// :: INFO util.GSet: Computing capacity for map cachedBlocks
// :: INFO util.GSet: VM type = -bit
// :: INFO util.GSet: 0.25% max memory 966.7 MB = 2.4 MB
// :: INFO util.GSet: capacity = ^ = entries
// :: INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
// :: INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes =
// :: INFO namenode.FSNamesystem: dfs.namenode.safemode.extension =
// :: INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets =
// :: INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users =
// :: INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = ,,
// :: INFO namenode.FSNamesystem: Retry cache on namenode is enabled
// :: INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is millis
// :: INFO util.GSet: Computing capacity for map NameNodeRetryCache
// :: INFO util.GSet: VM type = -bit
// :: INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB
// :: INFO util.GSet: capacity = ^ = entries
// :: INFO namenode.FSImage: Allocated new BlockPoolId: BP--192.168.123.102-
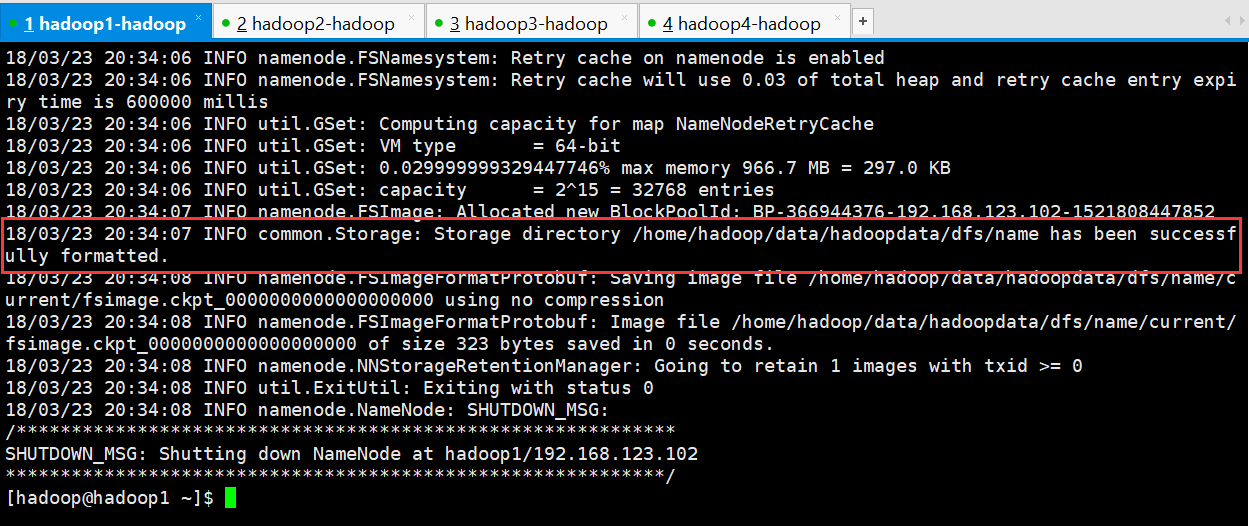
// :: INFO common.Storage: Storage directory /home/hadoop/data/hadoopdata/dfs/name has been successfully formatted.
// :: INFO namenode.FSImageFormatProtobuf: Saving image file /home/hadoop/data/hadoopdata/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
// :: INFO namenode.FSImageFormatProtobuf: Image file /home/hadoop/data/hadoopdata/dfs/name/current/fsimage.ckpt_0000000000000000000 of size bytes saved in seconds.
// :: INFO namenode.NNStorageRetentionManager: Going to retain images with txid >=
// :: INFO util.ExitUtil: Exiting with status
// :: INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop1/192.168.123.102
************************************************************/
[hadoop@hadoop1 ~]$
4、要把在hadoop1节点上生成的元数据 给复制到 另一个namenode(hadoop2)节点上
[hadoop@hadoop1 ~]$ cd data/
[hadoop@hadoop1 data]$ ls
hadoopdata journaldata zkdata
[hadoop@hadoop1 data]$ scp -r hadoopdata/ hadoop2:$PWD
VERSION 100% 206 0.2KB/s 00:00
fsimage_0000000000000000000.md5 100% 62 0.1KB/s 00:00
fsimage_0000000000000000000 100% 323 0.3KB/s 00:00
seen_txid 100% 2 0.0KB/s 00:00
[hadoop@hadoop1 data]$

5、格式化zkfc
重点强调:只能在nameonde节点进行
重点强调:只能在nameonde节点进行
重点强调:只能在nameonde节点进行
[hadoop@hadoop1 data]$ hdfs zkfc -formatZK
[hadoop@hadoop1 data]$ hdfs zkfc -formatZK
// :: INFO tools.DFSZKFailoverController: Failover controller configured for NameNode NameNode at hadoop1/192.168.123.102:
// :: INFO zookeeper.ZooKeeper: Client environment:zookeeper.version=3.4.-, built on // : GMT
// :: INFO zookeeper.ZooKeeper: Client environment:host.name=hadoop1
// :: INFO zookeeper.ZooKeeper: Client environment:java.version=1.8.0_73
// :: INFO zookeeper.ZooKeeper: Client environment:java.vendor=Oracle Corporation
// :: INFO zookeeper.ZooKeeper: Client environment:java.home=/usr/local/jdk1..0_73/jre
// :: INFO zookeeper.ZooKeeper: Client environment:java.class.path=/home/hadoop/apps/hadoop-2.7./etc/hadoop:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/paranamer-2.3.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/httpclient-4.2..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/jackson-mapper-asl-1.9..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/jets3t-0.9..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/commons-net-3.1.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/apacheds-i18n-2.0.-M15.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/jetty-sslengine-6.1..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/jetty-6.1..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/commons-math3-3.1..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/jsr305-3.0..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/jaxb-impl-2.2.-.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/jsch-0.1..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/commons-cli-1.2.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/jsp-api-2.1.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/hadoop-auth-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/servlet-api-2.5.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/mockito-all-1.8..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/zookeeper-3.4..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/jackson-core-asl-1.9..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/commons-io-2.4.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/commons-logging-1.1..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/jaxb-api-2.2..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/jersey-server-1.9.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/log4j-1.2..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/slf4j-log4j12-1.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/guava-11.0..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/jersey-json-1.9.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/xz-1.0.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/commons-lang-2.6.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/gson-2.2..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/httpcore-4.2..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/commons-compress-1.4..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/commons-httpclient-3.1.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/jettison-1.1.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/slf4j-api-1.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/api-asn1-api-1.0.-M20.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/api-util-1.0.-M20.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/xmlenc-0.52.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/hadoop-annotations-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/commons-beanutils-core-1.8..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/commons-codec-1.4.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/protobuf-java-2.5..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/asm-3.2.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/curator-framework-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/apacheds-kerberos-codec-2.0.-M15.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/htrace-core-3.1.-incubating.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/curator-client-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/commons-digester-1.8.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/activation-1.1.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/jackson-xc-1.9..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/commons-beanutils-1.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/jetty-util-6.1..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/stax-api-1.0-.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/avro-1.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/jersey-core-1.9.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/junit-4.11.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/netty-3.6..Final.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/jackson-jaxrs-1.9..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/commons-collections-3.2..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/hamcrest-core-1.3.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/curator-recipes-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/commons-configuration-1.6.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/lib/snappy-java-1.0.4.1.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/hadoop-common-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/hadoop-nfs-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/common/hadoop-common-2.7.-tests.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/jackson-mapper-asl-1.9..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/xercesImpl-2.9..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/jetty-6.1..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/jsr305-3.0..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/commons-cli-1.2.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/servlet-api-2.5.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/netty-all-4.0..Final.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/jackson-core-asl-1.9..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/commons-io-2.4.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/commons-logging-1.1..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/jersey-server-1.9.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/log4j-1.2..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/guava-11.0..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/commons-daemon-1.0..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/commons-lang-2.6.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/leveldbjni-all-1.8.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/xml-apis-1.3..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/xmlenc-0.52.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/commons-codec-1.4.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/protobuf-java-2.5..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/asm-3.2.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/htrace-core-3.1.-incubating.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/jetty-util-6.1..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/jersey-core-1.9.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/lib/netty-3.6..Final.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/hadoop-hdfs-nfs-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/hadoop-hdfs-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/hdfs/hadoop-hdfs-2.7.-tests.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/jackson-mapper-asl-1.9..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/jetty-6.1..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/jsr305-3.0..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/jaxb-impl-2.2.-.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/guice-servlet-3.0.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/commons-cli-1.2.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/servlet-api-2.5.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/zookeeper-3.4..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/jackson-core-asl-1.9..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/commons-io-2.4.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/zookeeper-3.4.-tests.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/commons-logging-1.1..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/jaxb-api-2.2..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/jersey-server-1.9.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/log4j-1.2..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/aopalliance-1.0.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/guava-11.0..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/jersey-json-1.9.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/javax.inject-.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/xz-1.0.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/commons-lang-2.6.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/leveldbjni-all-1.8.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/commons-compress-1.4..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/jersey-client-1.9.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/jersey-guice-1.9.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/jettison-1.1.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/commons-codec-1.4.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/protobuf-java-2.5..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/guice-3.0.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/asm-3.2.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/activation-1.1.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/jackson-xc-1.9..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/jetty-util-6.1..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/stax-api-1.0-.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/jersey-core-1.9.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/netty-3.6..Final.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/jackson-jaxrs-1.9..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/lib/commons-collections-3.2..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/hadoop-yarn-client-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/hadoop-yarn-server-tests-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/hadoop-yarn-common-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/hadoop-yarn-api-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/hadoop-yarn-server-sharedcachemanager-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/hadoop-yarn-server-common-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/hadoop-yarn-registry-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/lib/paranamer-2.3.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/lib/jackson-mapper-asl-1.9..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/lib/guice-servlet-3.0.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/lib/jackson-core-asl-1.9..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/lib/commons-io-2.4.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/lib/jersey-server-1.9.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/lib/log4j-1.2..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/lib/aopalliance-1.0.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/lib/javax.inject-.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/lib/xz-1.0.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/lib/leveldbjni-all-1.8.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/lib/commons-compress-1.4..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/lib/jersey-guice-1.9.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/lib/hadoop-annotations-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/lib/protobuf-java-2.5..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/lib/guice-3.0.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/lib/asm-3.2.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/lib/avro-1.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/lib/jersey-core-1.9.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/lib/junit-4.11.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/lib/netty-3.6..Final.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/lib/hamcrest-core-1.3.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/lib/snappy-java-1.0.4.1.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.-tests.jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7..jar:/home/hadoop/apps/hadoop-2.7./share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.7..jar:/home/hadoop/apps/hadoop-2.7./contrib/capacity-scheduler/*.jar
18/03/23 20:40:39 INFO zookeeper.ZooKeeper: Client environment:java.library.path=/home/hadoop/apps/hadoop-2.7.5/lib/native
18/03/23 20:40:39 INFO zookeeper.ZooKeeper: Client environment:java.io.tmpdir=/tmp
18/03/23 20:40:39 INFO zookeeper.ZooKeeper: Client environment:java.compiler=<NA>
18/03/23 20:40:39 INFO zookeeper.ZooKeeper: Client environment:os.name=Linux
18/03/23 20:40:39 INFO zookeeper.ZooKeeper: Client environment:os.arch=amd64
18/03/23 20:40:39 INFO zookeeper.ZooKeeper: Client environment:os.version=2.6.32-573.el6.x86_64
18/03/23 20:40:39 INFO zookeeper.ZooKeeper: Client environment:user.name=hadoop
18/03/23 20:40:39 INFO zookeeper.ZooKeeper: Client environment:user.home=/home/hadoop
18/03/23 20:40:39 INFO zookeeper.ZooKeeper: Client environment:user.dir=/home/hadoop/data
18/03/23 20:40:39 INFO zookeeper.ZooKeeper: Initiating client connection, connectString=hadoop1:2181,hadoop2:2181,hadoop3:2181,hadoop4:2181 sessionTimeout=1000 watcher=org.apache.hadoop.ha.ActiveStandbyElector$WatcherWithClientRef@9597028
18/03/23 20:40:39 INFO zookeeper.ClientCnxn: Opening socket connection to server hadoop2/192.168.123.103:2181. Will not attempt to authenticate using SASL (unknown error)
18/03/23 20:40:39 INFO zookeeper.ClientCnxn: Socket connection established to hadoop2/192.168.123.103:2181, initiating session
18/03/23 20:40:39 INFO zookeeper.ClientCnxn: Session establishment complete on server hadoop2/192.168.123.103:2181, sessionid = 0x26252cfa5e70000, negotiated timeout = 4000
18/03/23 20:40:39 INFO ha.ActiveStandbyElector: Session connected.
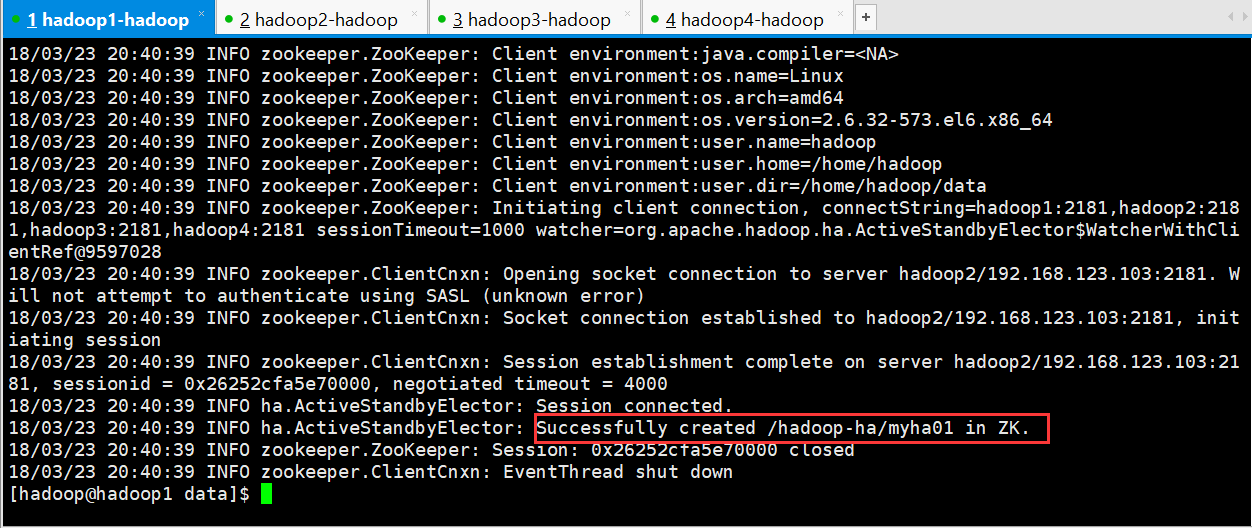
18/03/23 20:40:39 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/myha01 in ZK.
18/03/23 20:40:39 INFO zookeeper.ZooKeeper: Session: 0x26252cfa5e70000 closed
18/03/23 20:40:39 INFO zookeeper.ClientCnxn: EventThread shut down
[hadoop@hadoop1 data]$
启动集群
1、启动HDFS
可以从启动输出日志里面看到启动了哪些进程
[hadoop@hadoop1 ~]$ start-dfs.sh
Starting namenodes on [hadoop1 hadoop2]
hadoop2: starting namenode, logging to /home/hadoop/apps/hadoop-2.7./logs/hadoop-hadoop-namenode-hadoop2.out
hadoop1: starting namenode, logging to /home/hadoop/apps/hadoop-2.7./logs/hadoop-hadoop-namenode-hadoop1.out
hadoop3: starting datanode, logging to /home/hadoop/apps/hadoop-2.7./logs/hadoop-hadoop-datanode-hadoop3.out
hadoop4: starting datanode, logging to /home/hadoop/apps/hadoop-2.7./logs/hadoop-hadoop-datanode-hadoop4.out
hadoop2: starting datanode, logging to /home/hadoop/apps/hadoop-2.7./logs/hadoop-hadoop-datanode-hadoop2.out
hadoop1: starting datanode, logging to /home/hadoop/apps/hadoop-2.7./logs/hadoop-hadoop-datanode-hadoop1.out
Starting journal nodes [hadoop1 hadoop2 hadoop3]
hadoop3: journalnode running as process . Stop it first.
hadoop2: journalnode running as process . Stop it first.
hadoop1: journalnode running as process . Stop it first.
Starting ZK Failover Controllers on NN hosts [hadoop1 hadoop2]
hadoop2: starting zkfc, logging to /home/hadoop/apps/hadoop-2.7./logs/hadoop-hadoop-zkfc-hadoop2.out
hadoop1: starting zkfc, logging to /home/hadoop/apps/hadoop-2.7./logs/hadoop-hadoop-zkfc-hadoop1.out
[hadoop@hadoop1 ~]$
查看各节点进程是否正常
hadoop1
hadoop2

hadoop3
hadoop4

2、启动YARN
在主备 resourcemanager 中随便选择一台进行启动
[hadoop@hadoop4 ~]$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/apps/hadoop-2.7./logs/yarn-hadoop-resourcemanager-hadoop4.out
hadoop3: starting nodemanager, logging to /home/hadoop/apps/hadoop-2.7./logs/yarn-hadoop-nodemanager-hadoop3.out
hadoop2: starting nodemanager, logging to /home/hadoop/apps/hadoop-2.7./logs/yarn-hadoop-nodemanager-hadoop2.out
hadoop4: starting nodemanager, logging to /home/hadoop/apps/hadoop-2.7./logs/yarn-hadoop-nodemanager-hadoop4.out
hadoop1: starting nodemanager, logging to /home/hadoop/apps/hadoop-2.7./logs/yarn-hadoop-nodemanager-hadoop1.out
[hadoop@hadoop4 ~]$
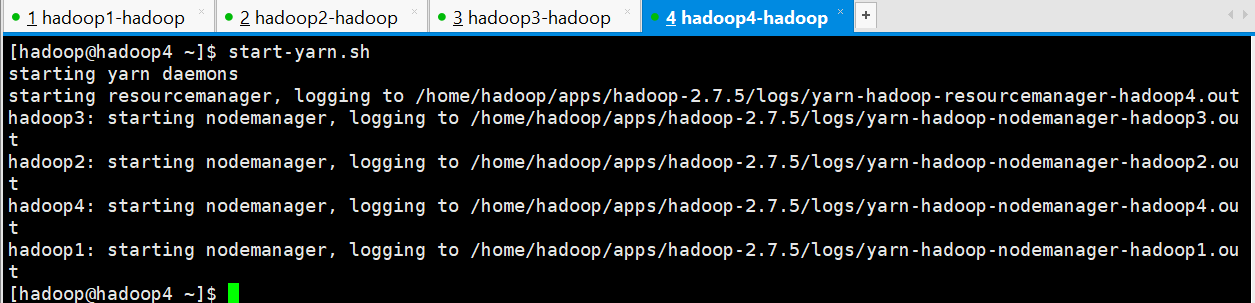
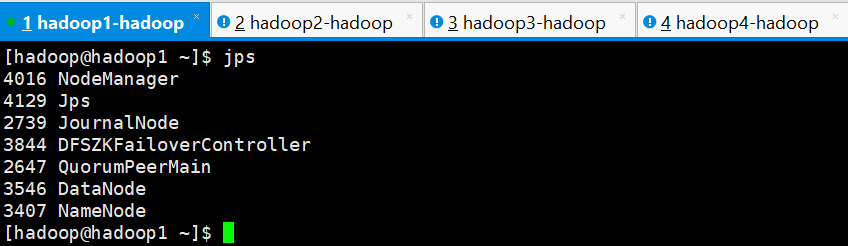
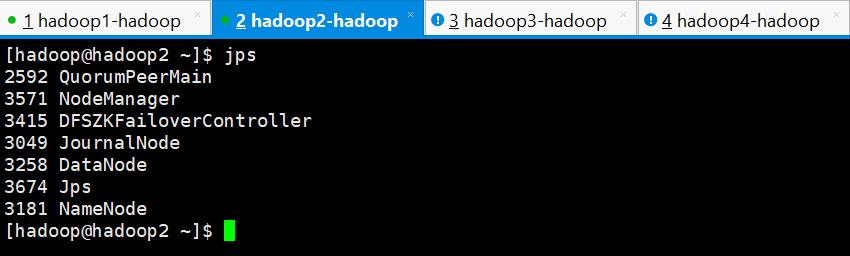
正常启动之后,检查各节点的进程
hadoop1
hadoop2
hadoop3

hadoop4

若备用节点的 resourcemanager 没有启动起来,则手动启动起来,在hadoop3上进行手动启动
[hadoop@hadoop3 ~]$ yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /home/hadoop/apps/hadoop-2.7./logs/yarn-hadoop-resourcemanager-hadoop3.out
[hadoop@hadoop3 ~]$ jps
ResourceManager
QuorumPeerMain
JournalNode
Jps
NodeManager
DataNode
[hadoop@hadoop3 ~]$
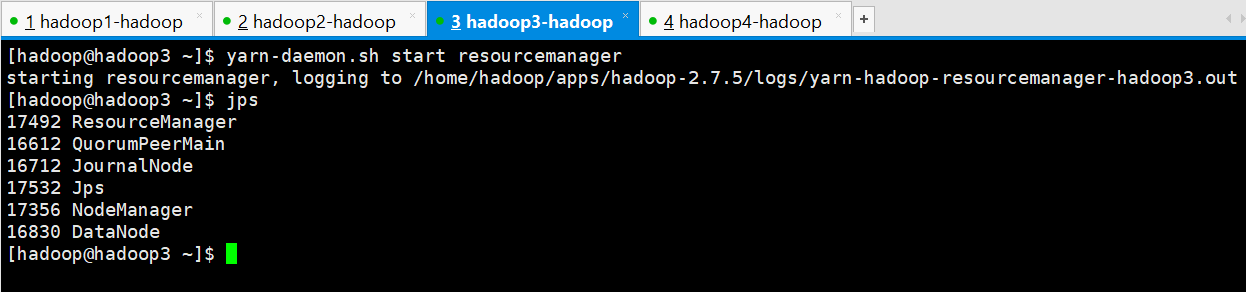
3、启动 mapreduce 任务历史服务器
[hadoop@hadoop1 ~]$ mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /home/hadoop/apps/hadoop-2.7./logs/mapred-hadoop-historyserver-hadoop1.out
[hadoop@hadoop1 ~]$ jps
NodeManager
JournalNode
Jps
DFSZKFailoverController
QuorumPeerMain
DataNode
JobHistoryServer
NameNode
[hadoop@hadoop1 ~]$
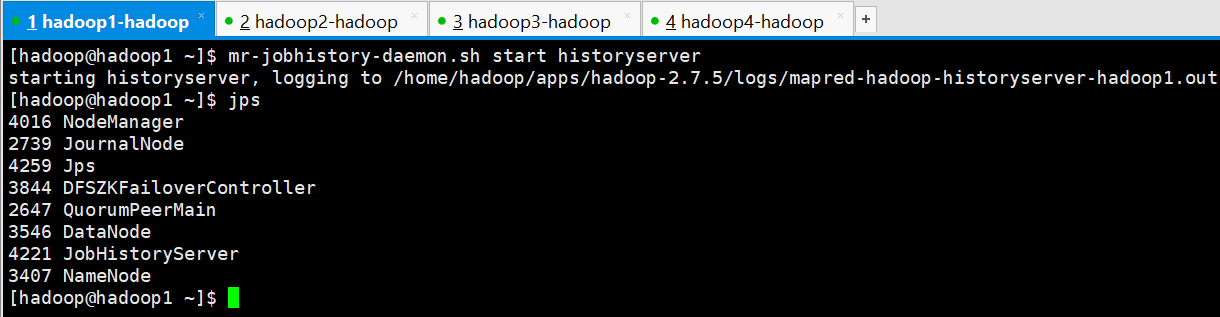
4、查看各主节点的状态
HDFS
[hadoop@hadoop1 ~]$ hdfs haadmin -getServiceState nn1
standby
[hadoop@hadoop1 ~]$ hdfs haadmin -getServiceState nn2
active
[hadoop@hadoop1 ~]$

YARN
[hadoop@hadoop4 ~]$ yarn rmadmin -getServiceState rm1
standby
[hadoop@hadoop4 ~]$ yarn rmadmin -getServiceState rm2
active
[hadoop@hadoop4 ~]$
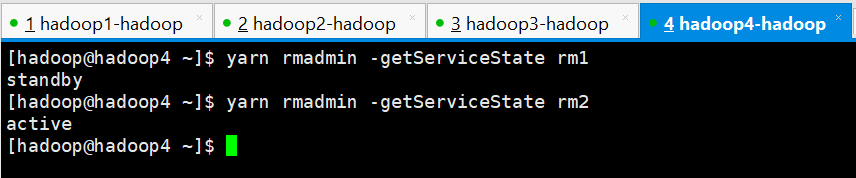
5、WEB界面进行查看
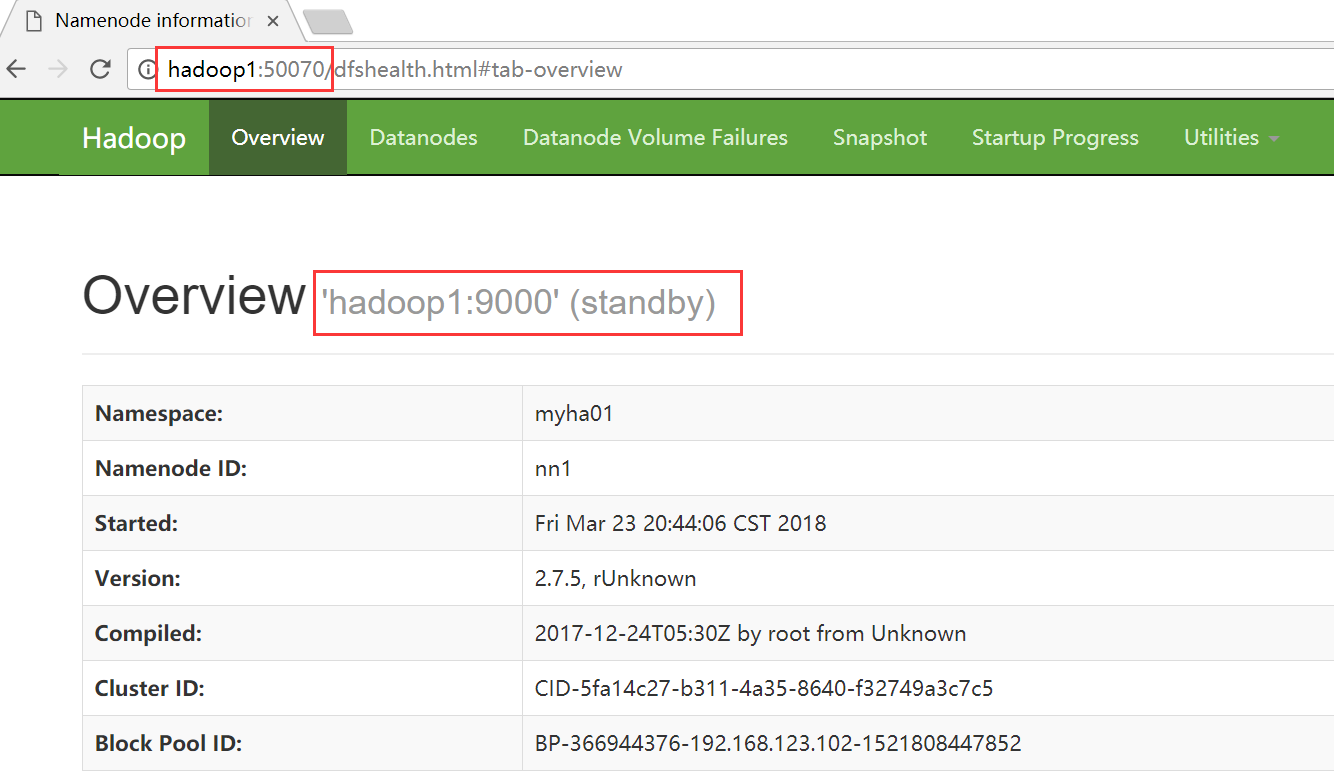
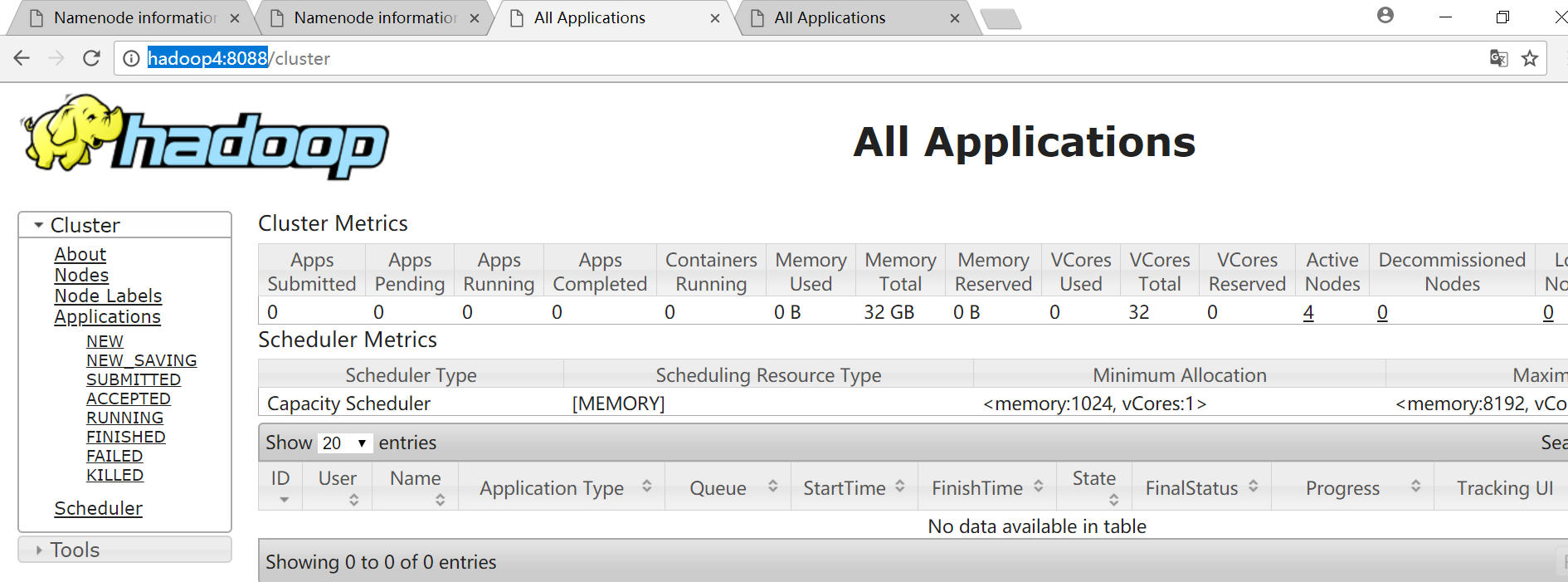
HDFS
hadoop1
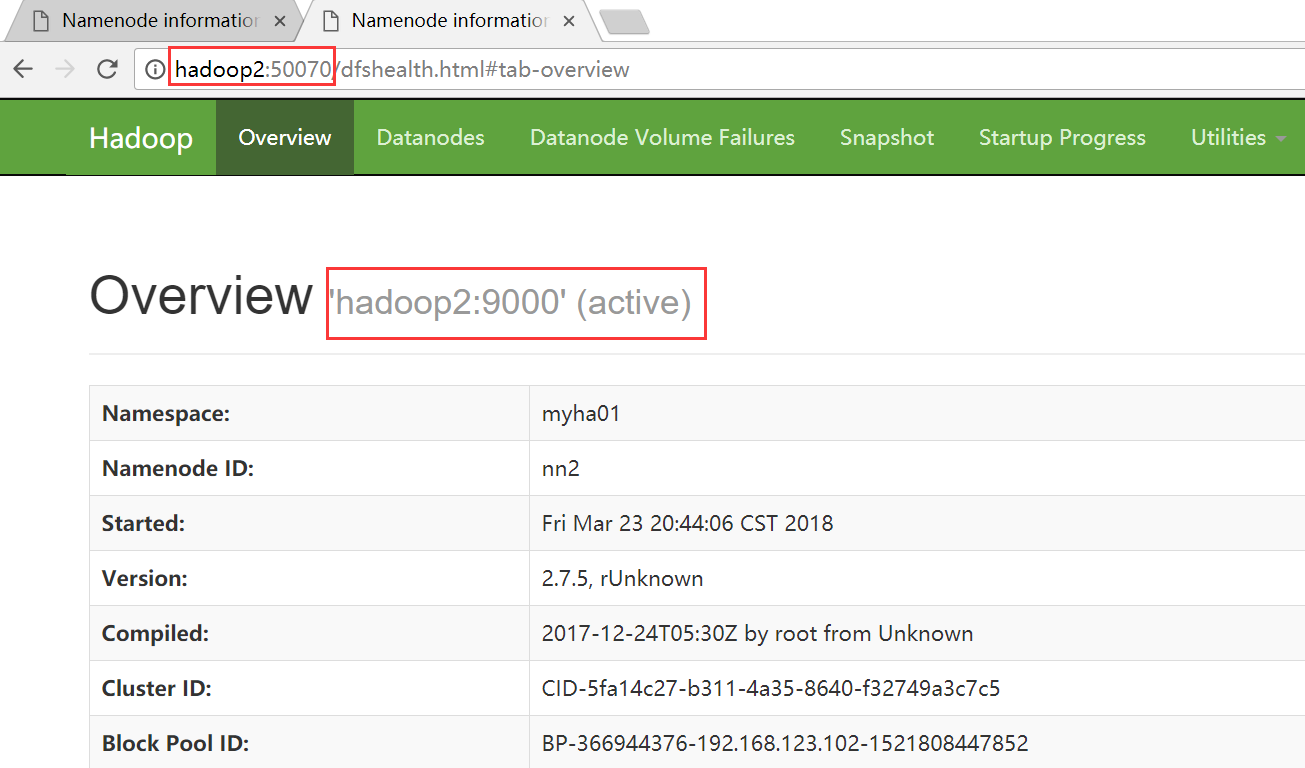
hadoop2
YARN
standby节点会自动跳到avtive节点
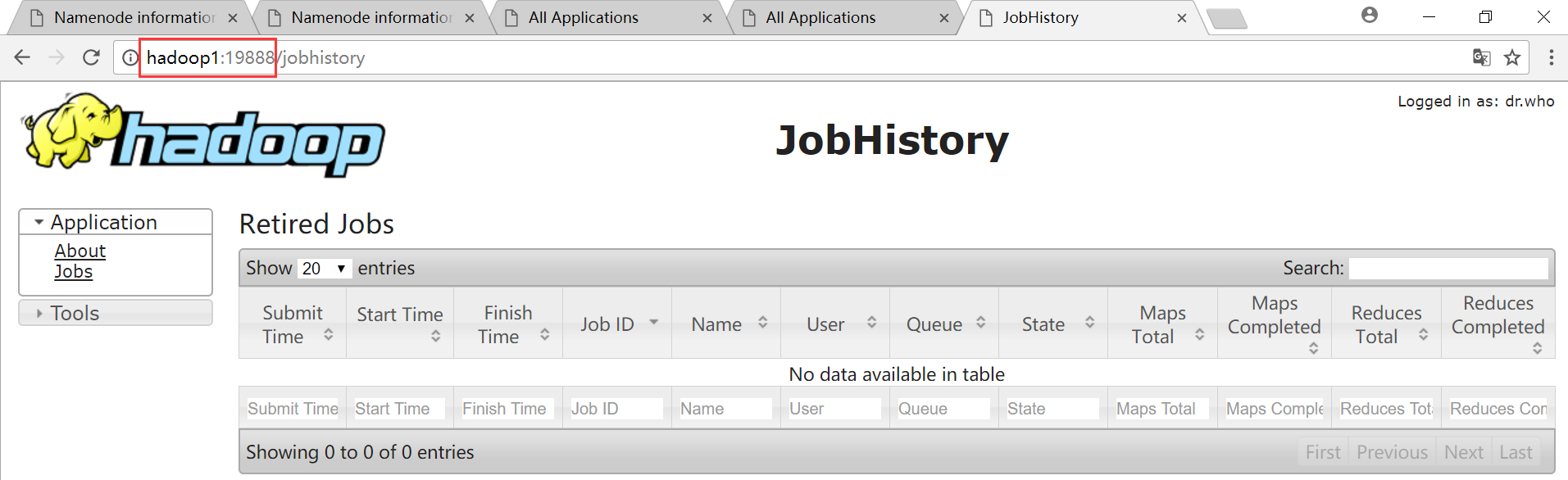
MapReduce历史服务器web界面
集群性能测试
1、干掉 active namenode, 看看集群有什么变化
目前hadoop2上的namenode节点是active状态,干掉他的进程看看hadoop1上的standby状态的namenode能否自动切换成active状态
[hadoop@hadoop2 ~]$ jps
QuorumPeerMain
DFSZKFailoverController
NodeManager
DataNode
Jps
NameNode
JournalNode
[hadoop@hadoop2 ~]$ kill -
hadoop2

hadoop1
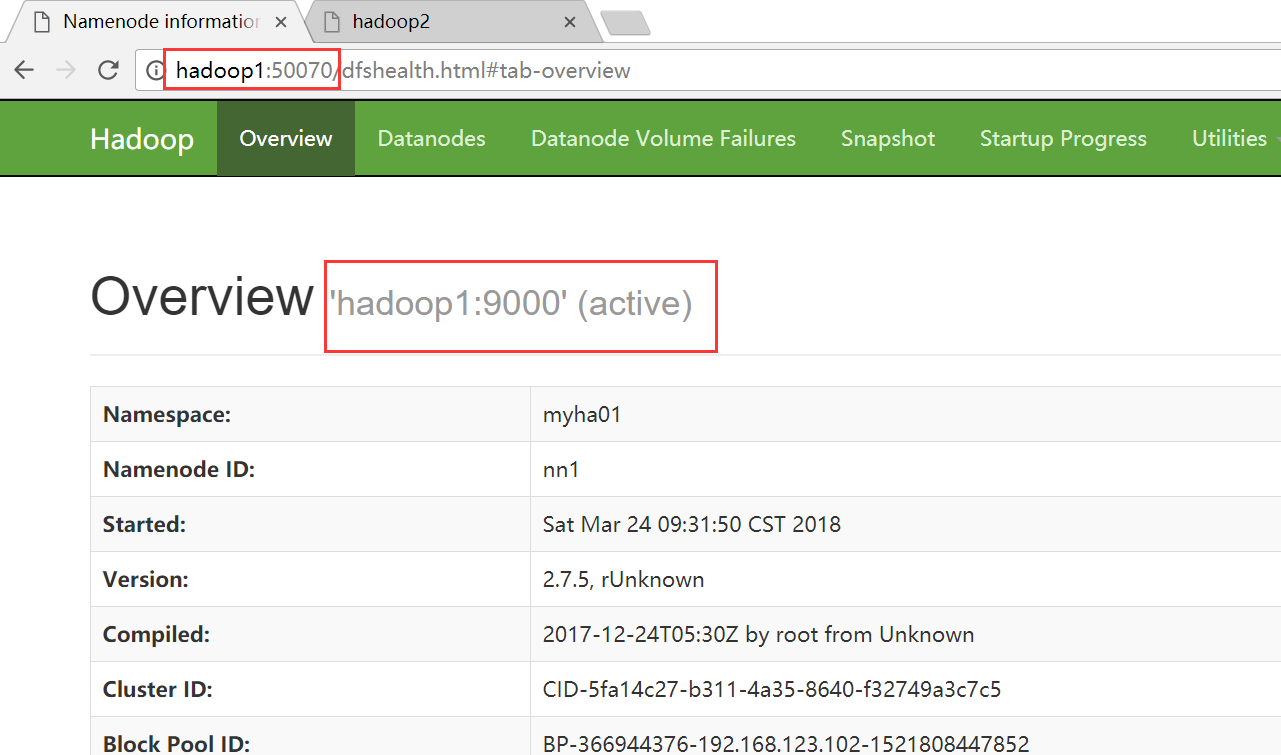
自动切换成功
2、在上传文件的时候干掉 active namenode, 看看有什么变化
首先将hadoop2上的namenode节点手动启动起来
[hadoop@hadoop2 ~]$ hadoop-daemon.sh start namenode
starting namenode, logging to /home/hadoop/apps/hadoop-2.7./logs/hadoop-hadoop-namenode-hadoop2.out
[hadoop@hadoop2 ~]$ jps
QuorumPeerMain
DFSZKFailoverController
NodeManager
DataNode
NameNode
JournalNode
Jps
[hadoop@hadoop2 ~]$
找一个比较大的文件,进行文件上传操作,5秒钟的时候干掉active状态的namenode,看看文件是否能上传成功
hadoop2进行上传
[hadoop@hadoop2 ~]$ ll
总用量
drwxrwxr-x hadoop hadoop 3月 : apps
drwxrwxr-x hadoop hadoop 3月 : data
-rw-rw-r-- hadoop hadoop 3月 : hadoop-2.7.-centos-6.7.tar.gz
drwxrwxr-x hadoop hadoop 3月 : log
-rw-rw-r-- hadoop hadoop 3月 : zookeeper.out
[hadoop@hadoop2 ~]$ hadoop fs -put hadoop-2.7.5-centos-6.7.tar.gz /hadoop/
hadoop1准备随时干掉namenode
[hadoop@hadoop1 ~]$ jps
DataNode
DFSZKFailoverController
QuorumPeerMain
JournalNode
Jps
NodeManager
JobHistoryServer
4015 NameNode
[hadoop@hadoop1 ~]$ kill -9 4015
hadoop2上的信息,在干掉hadoop1上namenode进程的时候,hadoop2报错
[hadoop@hadoop2 ~]$ hadoop fs -put hadoop-2.7.-centos-6.7.tar.gz /hadoop/
// :: INFO retry.RetryInvocationHandler: Exception while invoking addBlock of class ClientNamenodeProtocolTranslatorPB over hadoop1/192.168.123.102:. Trying to fail over immediately.
java.io.EOFException: End of File Exception between local host is: "hadoop2/192.168.123.103"; destination host is: "hadoop1":; : java.io.EOFException; For more details see: http://wiki.apache.org/hadoop/EOFException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:)
at java.lang.reflect.Constructor.newInstance(Constructor.java:)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:)
at org.apache.hadoop.ipc.Client.call(Client.java:)
at org.apache.hadoop.ipc.Client.call(Client.java:)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:)
at com.sun.proxy.$Proxy10.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:)
at com.sun.proxy.$Proxy11.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.locateFollowingBlock(DFSOutputStream.java:)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:)
Caused by: java.io.EOFException
at java.io.DataInputStream.readInt(DataInputStream.java:)
at org.apache.hadoop.ipc.Client$Connection.receiveRpcResponse(Client.java:)
at org.apache.hadoop.ipc.Client$Connection.run(Client.java:)
// :: INFO retry.RetryInvocationHandler: Exception while invoking addBlock of class ClientNamenodeProtocolTranslatorPB over hadoop2/192.168.123.103: after fail over attempts. Trying to fail over after sleeping for 1454ms.
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.StandbyException): Operation category READ is not supported in state standby
at org.apache.hadoop.hdfs.server.namenode.ha.StandbyState.checkOperation(StandbyState.java:)
at org.apache.hadoop.hdfs.server.namenode.NameNode$NameNodeHAContext.checkOperation(NameNode.java:)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkOperation(FSNamesystem.java:)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getNewBlockTargets(FSNamesystem.java:)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:)
at org.apache.hadoop.ipc.Server$Handler$.run(Server.java:)
at org.apache.hadoop.ipc.Server$Handler$.run(Server.java:)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:) at org.apache.hadoop.ipc.Client.call(Client.java:)
at org.apache.hadoop.ipc.Client.call(Client.java:)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:)
at com.sun.proxy.$Proxy10.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:)
at com.sun.proxy.$Proxy11.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.locateFollowingBlock(DFSOutputStream.java:)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:)
// :: INFO retry.RetryInvocationHandler: Exception while invoking addBlock of class ClientNamenodeProtocolTranslatorPB over hadoop1/192.168.123.102: after fail over attempts. Trying to fail over after sleeping for 1109ms.
java.net.ConnectException: Call From hadoop2/192.168.123.103 to hadoop1: failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:)
at java.lang.reflect.Constructor.newInstance(Constructor.java:)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:)
at org.apache.hadoop.ipc.Client.call(Client.java:)
at org.apache.hadoop.ipc.Client.call(Client.java:)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:)
at com.sun.proxy.$Proxy10.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:)
at com.sun.proxy.$Proxy11.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.locateFollowingBlock(DFSOutputStream.java:)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:)
Caused by: java.net.ConnectException: 拒绝连接
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:)
at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:)
at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:)
at org.apache.hadoop.ipc.Client$Connection.access$(Client.java:)
at org.apache.hadoop.ipc.Client.getConnection(Client.java:)
at org.apache.hadoop.ipc.Client.call(Client.java:)
... more
[hadoop@hadoop2 ~]$
在HDFS系统或web界面查看是否上传成功
命令查看
[hadoop@hadoop1 ~]$ hadoop fs -ls /hadoop/
Found items
-rw-r--r-- hadoop supergroup -- : /hadoop/hadoop-2.7.-centos-6.7.tar.gz
[hadoop@hadoop1 ~]$
web界面下载
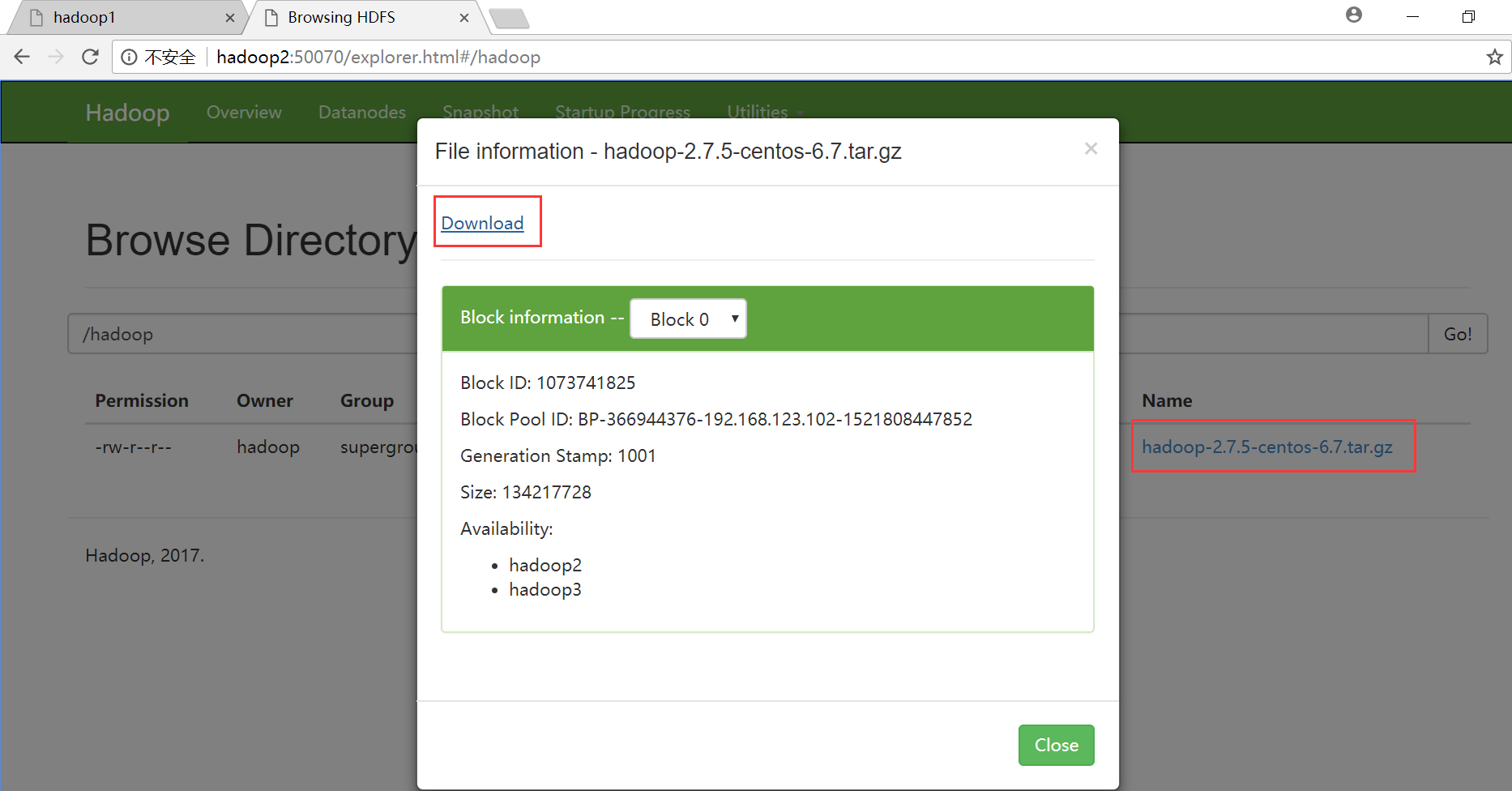

发现HDFS系统的文件大小和我们要上传的文件大小一致,均为199007110,说明在上传过程中干掉active状态的namenode,我们仍可以上传成功,HA起作用了
3、干掉 active resourcemanager, 看看集群有什么变化
目前hadoop4上的resourcemanager是活动的,干掉他的进程观察情况
[hadoop@hadoop4 ~]$ jps
ResourceManager
QuorumPeerMain
Jps
DataNode
NodeManager
[hadoop@hadoop4 ~]$ kill -9 3248
发现hadoop4的web界面打不开了
打开hadoop3上YARN的web界面查看,发现hadoop3上的resourcemanager变为active状态
4、在执行任务的时候干掉 active resourcemanager,看看集群有什么变化
上传一个比较大的文件到HDFS系统上
[hadoop@hadoop1 output2]$ hadoop fs -mkdir -p /words/input/
[hadoop@hadoop1 output2]$ ll
总用量
-rw-r--r--. hadoop hadoop 3月 : part-r-
-rw-r--r--. hadoop hadoop 3月 : _SUCCESS
[hadoop@hadoop1 output2]$ hadoop fs -put part-r-00000 /words/input/words.txt
[hadoop@hadoop1 output2]$
执行wordcount进行单词统计,在map执行过程中干掉active状态的resourcemanager,观察情况变化
首先启动hadoop4上的resourcemanager进程
[hadoop@hadoop4 ~]$ yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /home/hadoop/apps/hadoop-2.7./logs/yarn-hadoop-resourcemanager-hadoop4.out
[hadoop@hadoop4 ~]$ jps
QuorumPeerMain
ResourceManager
Jps
DataNode
NodeManager
[hadoop@hadoop4 ~]$
在hadoop1上执行单词统计
[hadoop@hadoop1 ~]$ cd apps/hadoop-2.7.5/share/hadoop/mapreduce/
[hadoop@hadoop1 mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.7.5.jar wordcount /words/input/ /words/output/
在hadoop3上随时准备干掉resourcemanager进程
[hadoop@hadoop3 ~]$ jps
JournalNode
NodeManager
Jps
QuorumPeerMain
DataNode
3757 ResourceManager
[hadoop@hadoop3 ~]$ kill -9 3757
在map阶段进行到43%时干掉resourcemanager进程
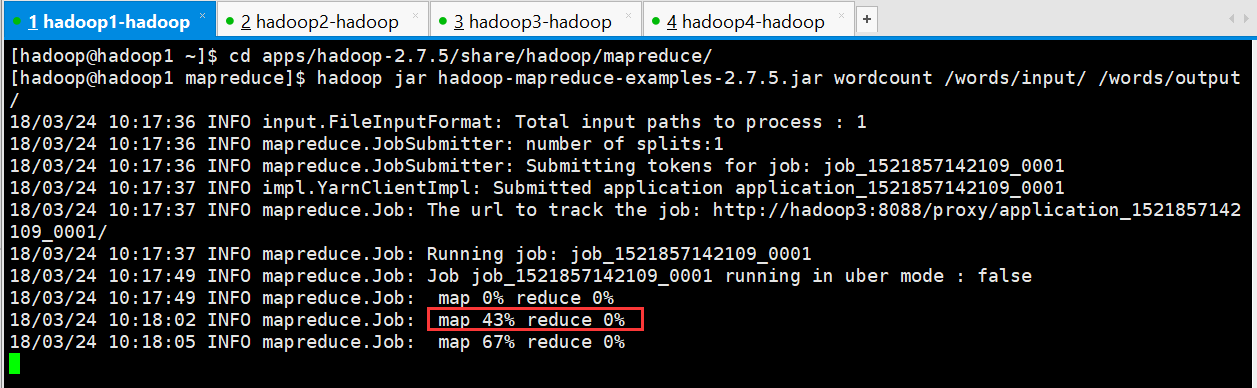
[hadoop@hadoop1 mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.7..jar wordcount /words/input/ /words/output/
// :: INFO input.FileInputFormat: Total input paths to process :
// :: INFO mapreduce.JobSubmitter: number of splits:
// :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1521857142109_0001
// :: INFO impl.YarnClientImpl: Submitted application application_1521857142109_0001
// :: INFO mapreduce.Job: The url to track the job: http://hadoop3:8088/proxy/application_1521857142109_0001/
// :: INFO mapreduce.Job: Running job: job_1521857142109_0001
// :: INFO mapreduce.Job: Job job_1521857142109_0001 running in uber mode : false
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_1521857142109_0001 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of write operations=
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of write operations=
Job Counters
Launched map tasks=
Launched reduce tasks=
Data-local map tasks=
Total time spent by all maps in occupied slots (ms)=
Total time spent by all reduces in occupied slots (ms)=
Total time spent by all map tasks (ms)=
Total time spent by all reduce tasks (ms)=
Total vcore-milliseconds taken by all map tasks=
Total vcore-milliseconds taken by all reduce tasks=
Total megabyte-milliseconds taken by all map tasks=
Total megabyte-milliseconds taken by all reduce tasks=
Map-Reduce Framework
Map input records=
Map output records=
Map output bytes=
Map output materialized bytes=
Input split bytes=
Combine input records=
Combine output records=
Reduce input groups=
Reduce shuffle bytes=
Reduce input records=
Reduce output records=
Spilled Records=
Shuffled Maps =
Failed Shuffles=
Merged Map outputs=
GC time elapsed (ms)=
CPU time spent (ms)=
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
Shuffle Errors
BAD_ID=
CONNECTION=
IO_ERROR=
WRONG_LENGTH=
WRONG_MAP=
WRONG_REDUCE=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
[hadoop@hadoop1 mapreduce]$
发现计算过程没有任何报错,web界面也显示任务执行成功

ZooKeeper学习之路 (九)利用ZooKeeper搭建Hadoop的HA集群的更多相关文章
- 搭建hadoop的HA集群模式(hadoop2.7.3+hive+spark)
参考:http://blog.51cto.com/12824426/2177663?source=drh 一.集群的规划 Zookeeper集群:192.168.176.131 (bigdata112 ...
- 用三台虚拟机搭建Hadoop全分布集群
用三台虚拟机搭建Hadoop全分布集群 所有的软件都装在/home/software下 虚拟机系统:centos6.5 jdk版本:1.8.0_181 zookeeper版本:3.4.7 hadoop ...
- 『实践』VirtualBox 5.1.18+Centos 6.8+hadoop 2.7.3搭建hadoop完全分布式集群及基于HDFS的网盘实现
『实践』VirtualBox 5.1.18+Centos 6.8+hadoop 2.7.3搭建hadoop完全分布式集群及基于HDFS的网盘实现 1.基本设定和软件版本 主机名 ip 对应角色 mas ...
- Hadoop(三)手把手教你搭建Hadoop全分布式集群
前言 上一篇介绍了伪分布式集群的搭建,其实在我们的生产环境中我们肯定不是使用只有一台服务器的伪分布式集群当中的.接下来我将给大家分享一下全分布式集群的搭建! 其实搭建最基本的全分布式集群和伪分布式集群 ...
- Hadoop(三)搭建Hadoop全分布式集群
原文地址:http://www.cnblogs.com/zhangyinhua/p/7652686.html 阅读目录(Content) 一.搭建Hadoop全分布式集群前提 1.1.网络 1.2.安 ...
- hadoop namenode HA集群搭建
hadoop集群搭建(namenode是单点的) http://www.cnblogs.com/kisf/p/7456290.html HA集群需要zk, zk搭建:http://www.cnblo ...
- Hadoop 学习之路(八)—— 基于ZooKeeper搭建Hadoop高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 二.集群规划 三.前置条件 四.集群配置 五.启动集群 六.查看集群 七.集群的二次启动 一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS ...
- Hadoop 系列(八)—— 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
随机推荐
- SSM配置JDBC错误: cquisition Attempt Failed!!!
异常: 警告: com.mchange.v2.resourcepool.BasicResourcePool$AcquireTask@20ffa401 -- Acquisition Attempt Fa ...
- python__new__与__init__的区别
__new__ __init__区别 1 class A(object): 2 def __init__(self,*args, **kwargs): 3 print "init A&quo ...
- html中内联元素和块元素的区别、用法以及联系
昨天用asp.net的BulletedList做一个导航栏,最终该控件形成的html代码是ul列表和a超链接,具体代码如下: <ul id="BulletedList1" s ...
- android调试debug快捷键
1. [Ctrl+Shift+B]:在当前行设置断点或取消设置的断点. 2. [F11]:调试最后一次执行的程序. 3. [Ctrl+F11]:运行最后一次执行的程序. 4. ...
- input pattern中常用的正则表达式
常用的正则表达式 pattern的用法,只是列出来一些常用的正则: 信用卡 [0-9]{13,16} 银联卡 ^62[0-5]\d{13,16}$ Visa: ^4[0-9]{12}(?:[0-9]{ ...
- CSS 画一个心
效果图: 实现原理: 可以把这个心分为两部分,两个长方形,分别设置 border-radius,transform: rotate() . 设置属性之后 再次添加一个,设置相反的 rotate 设置其 ...
- Android屏幕适配工具
这里需要用到一个jar包,下载拿到这个jar包后直接双击就可以生成市场大部分主流屏幕尺寸了.然后只要把生成好的xml尺寸文件拷贝到相应的value文件中即可.很方便,以后再也不用担心适配繁琐的问题了. ...
- 强网杯2018 pwn复现
前言 本文对强网杯 中除了 2 个内核题以外的 6 个 pwn 题的利用方式进行记录.题目真心不错 程序和 exp: https://gitee.com/hac425/blog_data/blob/m ...
- vue.js高仿饿了么(前期整理)
1.熟悉项目开发流程 需求分析——>脚手架工具——>数据mock——>架构设计——>代码编写——>自测——>编译打包. 2.熟悉代码规范 从架构设计.组件抽象.模块 ...
- Oracle ALL DBA表
select * from all_tab_comments -- 查询所有用户的表,视图等 select * from user_tab_comments -- 查询本用户的表,视图等 select ...