用三台虚拟机搭建Hadoop全分布集群
用三台虚拟机搭建Hadoop全分布集群
所有的软件都装在/home/software下
虚拟机系统:centos6.5
jdk版本:1.8.0_181
zookeeper版本:3.4.7
hadoop版本:2.7.1
1.安装jdk
准备好免安装压缩包放在/home/software下
cd /home/software
tar -xvf jdk-8u181-linux-x64.tar.gz
配置环境变量
vim /etc/profile
末尾添加
export JAVA_HOME=/home/software/jdk1.8.0_181
export CLASSPATH=$:CLASSPATH:$JAVA_HOME/lib/
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile
检查是否配置成功,查看jdk版本
java –version

2.关闭防火墙
service iptables stop
chkconfig iptables off
3.配置主机名
vim /etc/sysconfig/network
HOSTNAME=qyws
三个节点主机名分别设置为qyws,qyws2,qyws3
source /etc/sysconfig/network
4.改hosts文件
vim /etc/hosts
192.168.38.133 qyws
192.168.38.134 qyws2
192.168.38.135 qyws3
5.重启
reboot
6.配置免密登陆
ssh-keygen
ssh-copy-id root@qyws
ssh-copy-id root@qyws2
ssh-copy-id root@qyws3
7.解压zookeeper压缩包
tar –xf zookeeper-3.4..tar.gz
8.搭建zookeeper集群
cd /home/software/zookeeper-3.4./conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
14 行
dataDir=/home/software/zookeeper-3.4.7/tmp
末尾追加
server.1=192.168.38.133:2888:3888
server.2=192.168.38.134:2888:3888
server.3=192.168.38.135:2888:3888
9.将配置好的zookeeper拷贝到另两个节点
scp -r zookeeper-3.4. root@qyws2:/home/software/
scp -r zookeeper-3.4. root@qyws3:/home/software/
10.进入zookeeper目录下创建tmp目录,新建myid文件
cd /home/software/zookeeper-3.4.
mkdir tmp
cd tmp
vim myid
三个节点myid分别设置为1,2,3
11.解压hadoop压缩包
tar -xvf hadoop-2.7.1_64bit.tar.gz
12.编辑hadoop-env.sh
cd /home/software/hadoop-2.7./etc/hadoop
vim hadoop-env.sh
25行
export JAVA_HOME=/home/software/jdk1.8.0_181
33行
export HADOOP_CONF_DIR=/home/software/hadoop-2.7.1/etc/hadoop
source hadoop-env.sh
13.编辑core-site.xml
<!--指定hdfs的nameservice,为整个集群起一个别名-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!--指定Hadoop数据临时存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/software/hadoop-2.7.1/tmp</value>
</property>
<!--指定zookeeper的存放地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>qyws:2181,qyws2:2181,qyws3:2181</value>
</property>
14.编辑hdfs-site.xml
<!--执行hdfs的nameservice为ns,注意要和core-site.xml中的名称保持一致-->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!--ns集群下有两个namenode,分别为nn1, nn2-->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!--nn1的RPC通信-->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>qyws:9000</value>
</property>
<!--nn1的http通信-->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>qyws:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>qyws2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>qyws2:50070</value>
</property>
<!--指定namenode的元数据在JournalNode上存放的位置,这样,namenode2可以从journalnode集群里的指定位置上获取信息,达到热备效果-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://qyws:8485;qyws2:8485;qyws3:8485/ns</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/software/hadoop-2.7.1/tmp/journal</value>
</property>
<!-- 开启NameNode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--配置namenode存放元数据的目录,可以不配置,如果不配置则默认放到hadoop.tmp.dir下-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/software/hadoop-2.7.1/tmp/hdfs/name</value>
</property>
<!--配置datanode存放元数据的目录,可以不配置,如果不配置则默认放到hadoop.tmp.dir下-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/software/hadoop-2.7.1/tmp/hdfs/data</value>
</property>
<!--配置复本数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--设置用户的操作权限,false表示关闭权限验证,任何用户都可以操作-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
15.编辑mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
16.编辑yarn-site.xml
<!--配置yarn的高可用-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--指定两个resourcemaneger的名称-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!--配置rm1的主机-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>qyws</value>
</property>
<!--配置rm2的主机-->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>qyws3</value>
</property>
<!--开启yarn恢复机制-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--执行rm恢复机制实现类-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!--配置zookeeper的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>qyws:2181,qyws2:2181,qyws3:2181</value>
</property>
<!--执行yarn集群的别名-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>ns-yarn</value>
</property>
<!-- 指定nodemanager启动时加载server的方式为shuffle server -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定resourcemanager地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>qyws3</value>
</property>
17.编辑slaves
vim /home/software/hadoop-2.7./etc/hadoop/slaves
qyws
qyws2
qyws3
18.把配置好的hadoop拷贝到其他节点
scp -r hadoop-2.7. root@qyws2:/home/software/
scp -r hadoop-2.7. root@qyws3:/home/software/
19.配置环境变量
vim /etc/profile
末尾添加
export HADOOP_HOME=/home/software/hadoop-2.7.
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
20.三个节点启动zookeeper
cd /home/software/zookeeper-3.4./bin
sh zkServer.sh start
查看zookeeper状态
sh zkServer.sh status



21.格式化zookeeper(在第一个节点操作即可):
hdfs zkfc -formatZK
22.在每个节点启动JournalNode:
hadoop-daemon.sh start journalnode
23.在第一个节点上格式化NameNode:
hadoop namenode -format
24.在第一个节点上启动NameNode:
hadoop-daemon.sh start namenode
25.在第二个节点上格式化NameNode:
hdfs namenode -bootstrapStandby
26.在第二个节点上启动NameNode:
hadoop-daemon.sh start namenode
27.在三个节点上启动DataNode:
hadoop-daemon.sh start datanode
28.在第一个节点和第二个节点上启动zkfc(FailoverController):
hadoop-daemon.sh start zkfc
29.在第一个节点上启动Yarn:
start-yarn.sh
30.在第三个节点上启动ResourceManager:
yarn-daemon.sh start resourcemanager
31.查看运行的服务

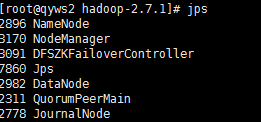
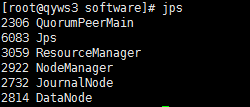
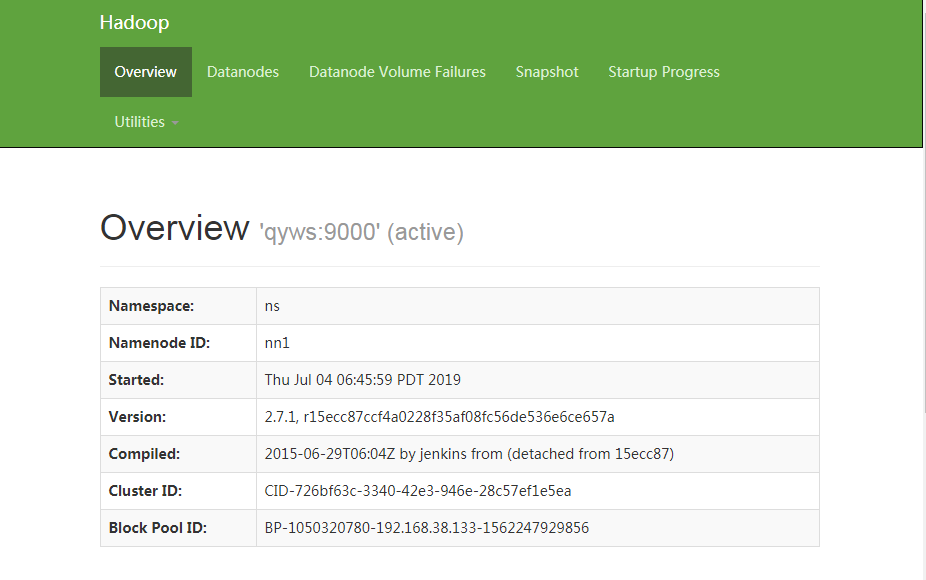
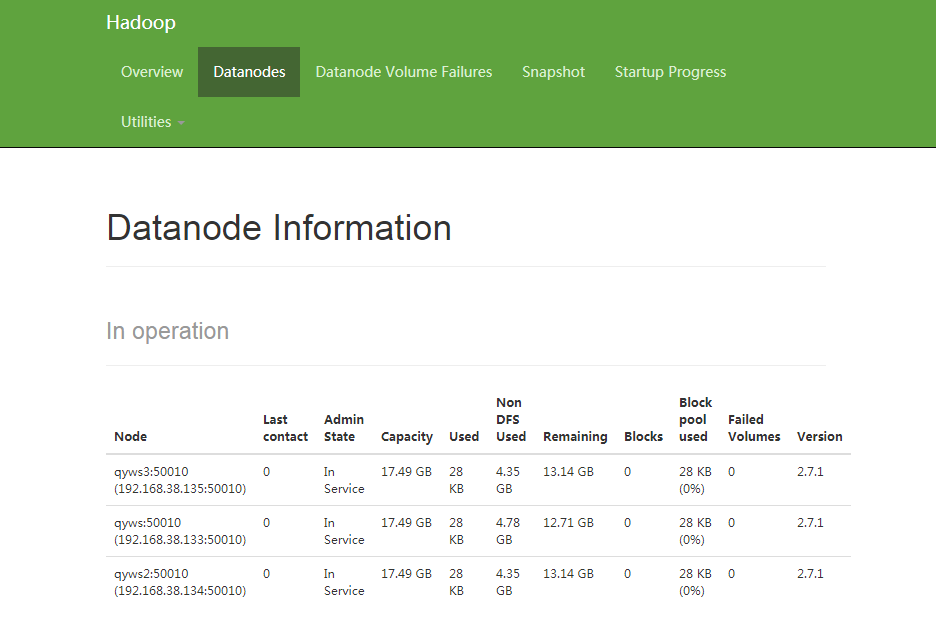
32.查看第一个节点namenode
浏览器输入http://192.168.38.133:50070
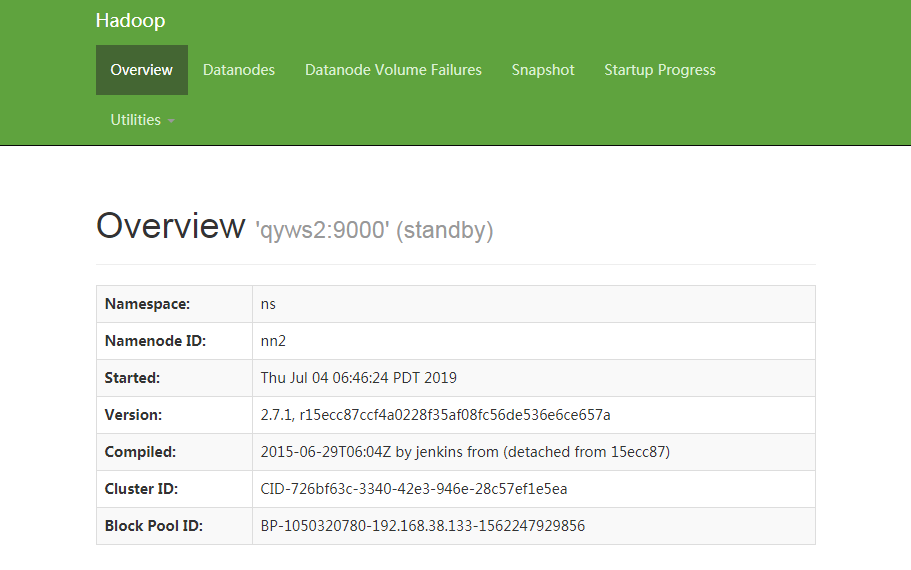
查看第二个节点namenode(主备)
浏览器输入http://192.168.38.134:50070
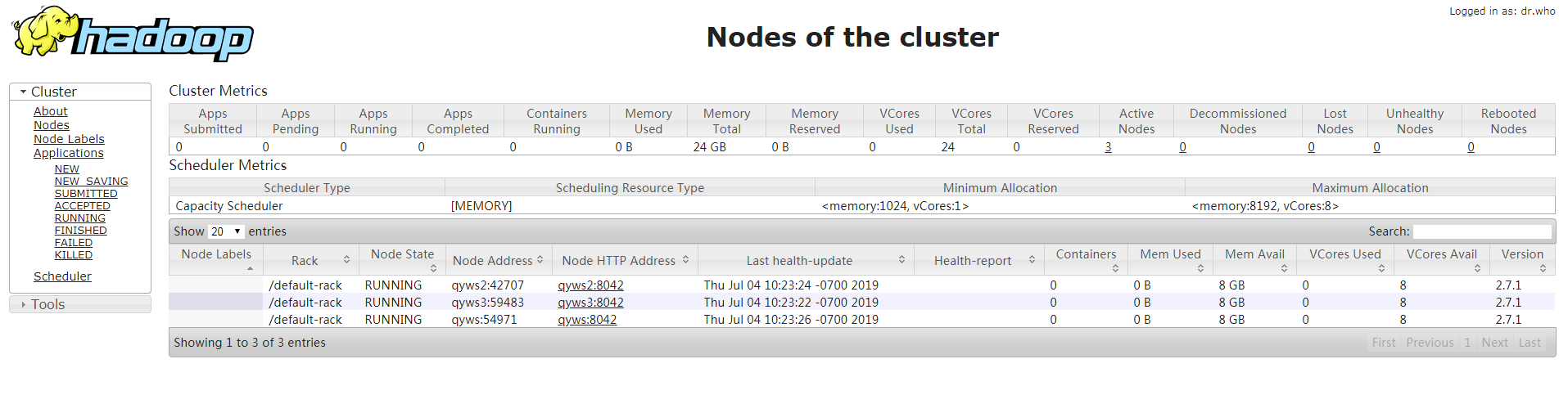
33.访问管理页面http://192.168.38.133:8088
用三台虚拟机搭建Hadoop全分布集群的更多相关文章
- Hadoop(三)手把手教你搭建Hadoop全分布式集群
前言 上一篇介绍了伪分布式集群的搭建,其实在我们的生产环境中我们肯定不是使用只有一台服务器的伪分布式集群当中的.接下来我将给大家分享一下全分布式集群的搭建! 其实搭建最基本的全分布式集群和伪分布式集群 ...
- Hadoop(三)搭建Hadoop全分布式集群
原文地址:http://www.cnblogs.com/zhangyinhua/p/7652686.html 阅读目录(Content) 一.搭建Hadoop全分布式集群前提 1.1.网络 1.2.安 ...
- Kafka1 利用虚拟机搭建自己的Kafka集群
前言: 上周末自己学习了一下Kafka,参考网上的文章,学习过程中还是比较顺利的,遇到的一些问题最终也都解决了,现在将学习的过程记录与此,供以后自己查阅,如果能帮助到其他人,自然是更好的. ...
- 『实践』VirtualBox 5.1.18+Centos 6.8+hadoop 2.7.3搭建hadoop完全分布式集群及基于HDFS的网盘实现
『实践』VirtualBox 5.1.18+Centos 6.8+hadoop 2.7.3搭建hadoop完全分布式集群及基于HDFS的网盘实现 1.基本设定和软件版本 主机名 ip 对应角色 mas ...
- ZooKeeper1 利用虚拟机搭建自己的ZooKeeper集群
前言: 前段时间自己参考网上的文章,梳理了一下基于分布式环境部署的业务系统在解决数据一致性问题上的方案,其中有一个方案是使用ZooKeeper,加之在大数据处理中,ZooKeeper确实起 ...
- vmware10上三台虚拟机的Hadoop2.5.1集群搭建
由于官方版本的Hadoop是32位,若在64位Linux上安装,则必须先重新在64位环境下编译Hadoop源代码.本环境采用编译后的hadoop2.5.1 . 安装参考博客: 1 http://www ...
- hadoop学习笔记(六):hadoop全分布式集群的环境搭建
本文原创,如需转载,请注明作者以及原文链接! 一.前期准备: 1.jdk安装 不要用centos7自带的openJDK2.hostname 配置 配置位置:/etc/s ...
- hadoop学习通过虚拟机安装hadoop完全分布式集群
要想深入的学习hadoop数据分析技术,首要的任务是必须要将hadoop集群环境搭建起来,可以将hadoop简化地想象成一个小软件,通过在各个物理节点上安装这个小软件,然后将其运行起来,就是一个had ...
- ZooKeeper学习之路 (九)利用ZooKeeper搭建Hadoop的HA集群
Hadoop HA 原理概述 为什么会有 hadoop HA 机制呢? HA:High Available,高可用 在Hadoop 2.0之前,在HDFS 集群中NameNode 存在单点故障 (SP ...
随机推荐
- learning gcc #pragma once
referenc: https://zh.wikipedia.org/wiki/Pragma_once 在C和C++编程语言中,#pragma once是一个非标准但是被广泛支持的前置处理符号, 会让 ...
- STL漫谈
从现在开始,想写一个关于STL工具的各种tip类的东西,记录下那些细节,以免以后使用STL工具时出错. 1.关于map,如果需要第一个键值需要放进一个结构体,那么结构体是需要写好其自定义的排序规则的, ...
- 【洛谷2057】 [SHOI2007]善意的投票(最小割)
传送门 洛谷 Solution 比较巧妙啊! 考虑这个只有同意和不统一两种,所以直接令\(s\)表示选,\(t\)表示不选,然后在朋友直接建双向边就好了. 代码实现 #include<bits/ ...
- 22.从上往下打印二叉树 Java
题目描述 从上往下打印出二叉树的每个节点,同层节点从左至右打印. 解题思路 就是二叉树的层序遍历.借助一个队列就可以实现.使用两个队列一个存放节点,一个存放值.先将根节点加入到队列中,然后遍历队列中的 ...
- 笔记一(固件、BIOS、UEFI)
1.固件 固件一般是指保存在ROM中的程序和数据,通过固件操作系统按照标准的设备驱动实现特定机器的运行. 简单来讲,固件就是固化在ROM的软件,当然也可以通过特定的工具进行升级. MP3.MP4.手机 ...
- 整合pjax无刷新
一:整合pjax的准备工作: 检查你的网站是否引入1.7.0版本以上的jquery.js,如果没有请全局引入 1.新浪CDN提速:<script type="text/javascri ...
- 深度解析 Qt 中动态链接库
本文介绍的是Qt 中动态链接库,现在有些软件有自动升级功能,有些就是下载新的DLL文件,替换原来的动态链接库,MFC好象也有类似机制,Qt还有一种方式,就是把一个QWidget子类,编译成动态链接库. ...
- token的解码及 判断值不为空的方法
token 的解码要使用插件:jwt-decode 判断值不为空的方法: function isEmpty(value){ return ( value === undefined || value ...
- storm java.io.NotSerializableException
今天编写一个storm的topology,bolt的逻辑跟之前的类似. 为了减少重复代码,我建了个抽象基类,存放bolt的公共逻辑,设计了几个abstract方法,不同的逻辑部分由子类实现. 基类日志 ...
- 使用git send-email发送邮件时报错: Unable to initialize SMTP properly怎么处理?
答: 配置~/.gitconfig中的smtpserver 需往~/.gitconfig中添加如下内容: [sendemail] smtpserver = <stmp_server_name ...