如何用elasticsearch构架亿级数据采集系统(第1集:非生产环境windows安装篇)
(一)做啥的?
基于Elasticsearch,可以为实现,大数据量(亿级)的实时统计查询的方案设计,提供底层数据框架。
本小节jacky会在非生产环境下,在 window 系统下,给大家分享着部分的相关内容。
(二)Elasticsearch的安装
2.1 版本选择:elasticsearch-rtf
第1步:安装java
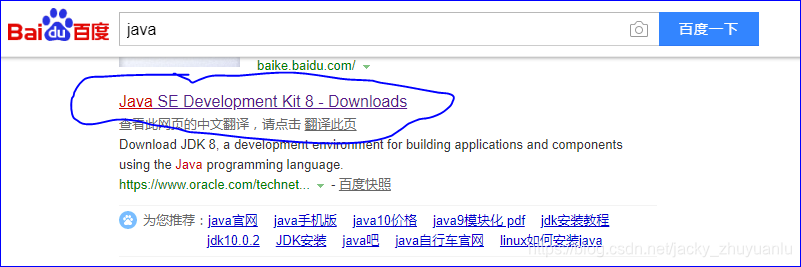
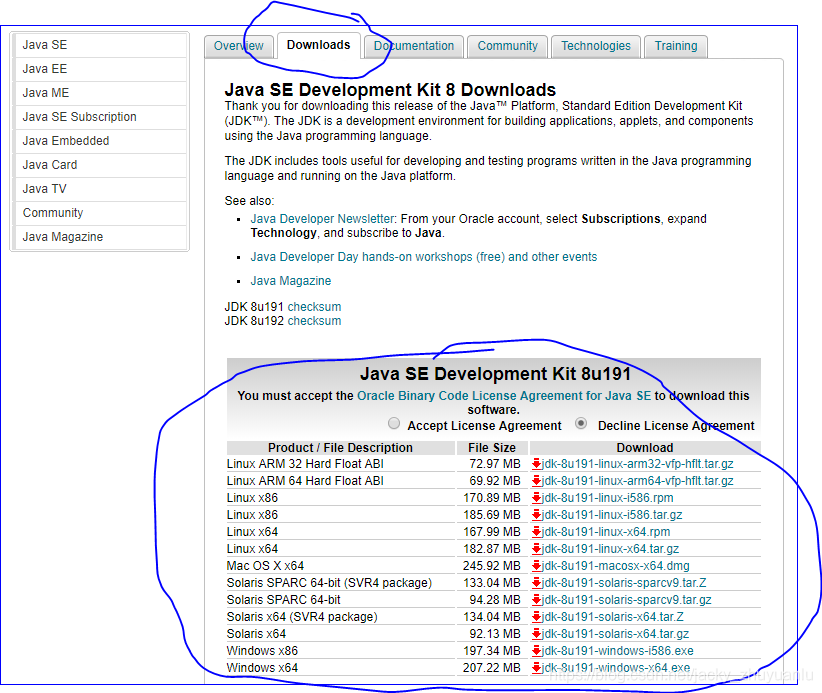
验证java是否安装成功:
- 这里java要兼容elasticsearch,必须安装java8以上的版本
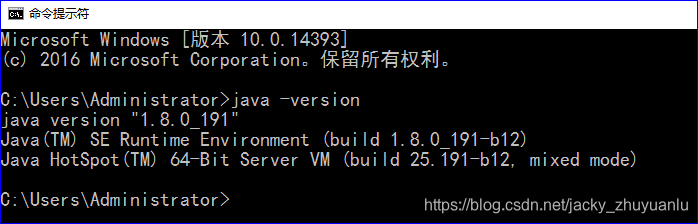
- 这里java要兼容elasticsearch,必须安装java8以上的版本
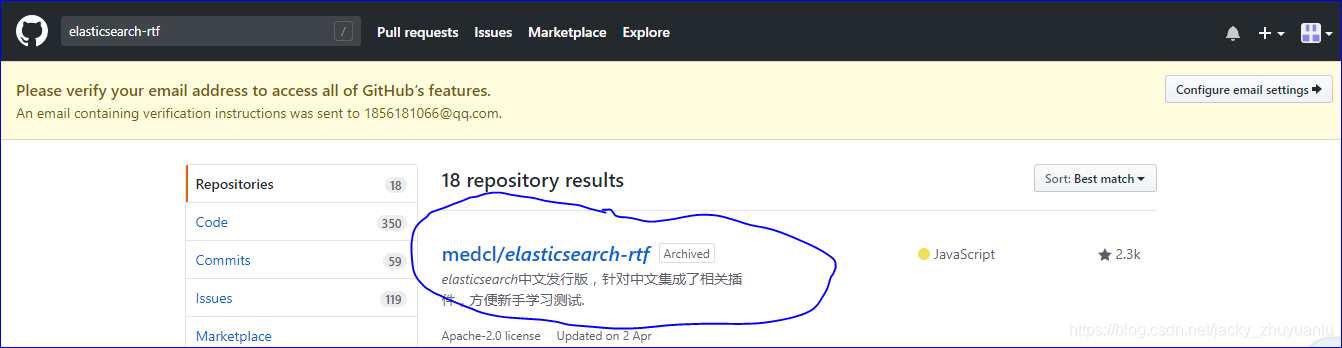
第2步:下载elasticsearch-rtf
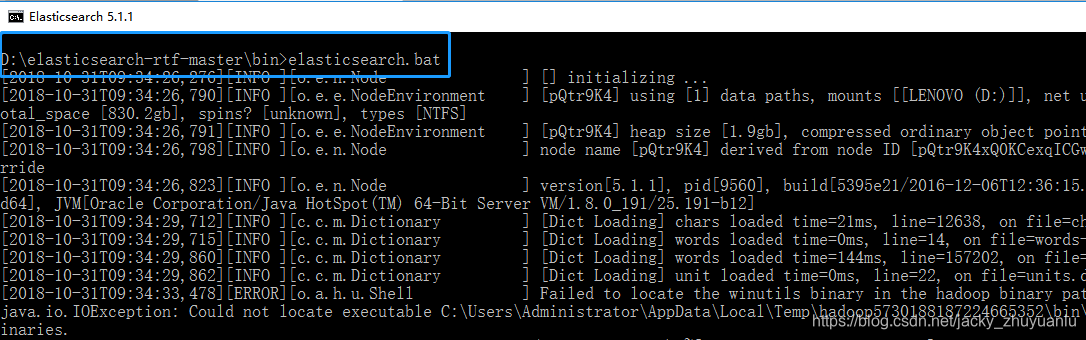
第3步:在bin目录下用命令行安装elasticsearch
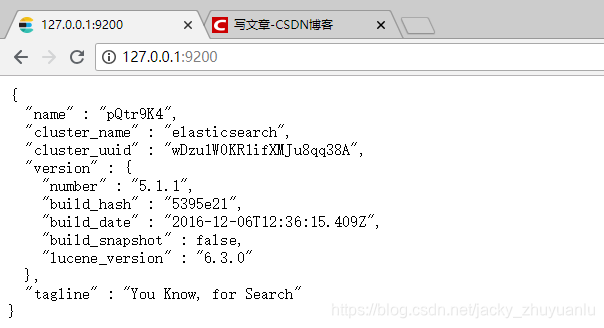
第4步:查看9200访问接口,如果看到以下界面,说明我们的elasticsearch就安装成功了
(三)head 插件的安装
第1步,在github中下载head插件
第二步:下载npm
- 下载安装npm的前置环境-nodejs
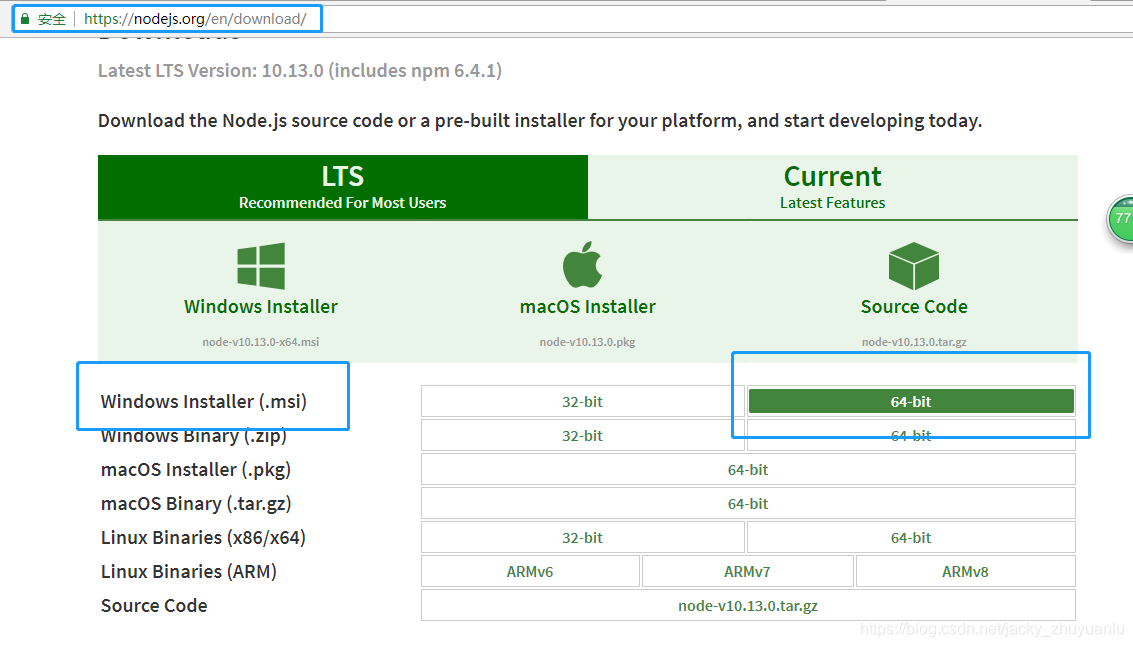
- 下载安装npm的前置环境-nodejs
验证npm是否下载成功
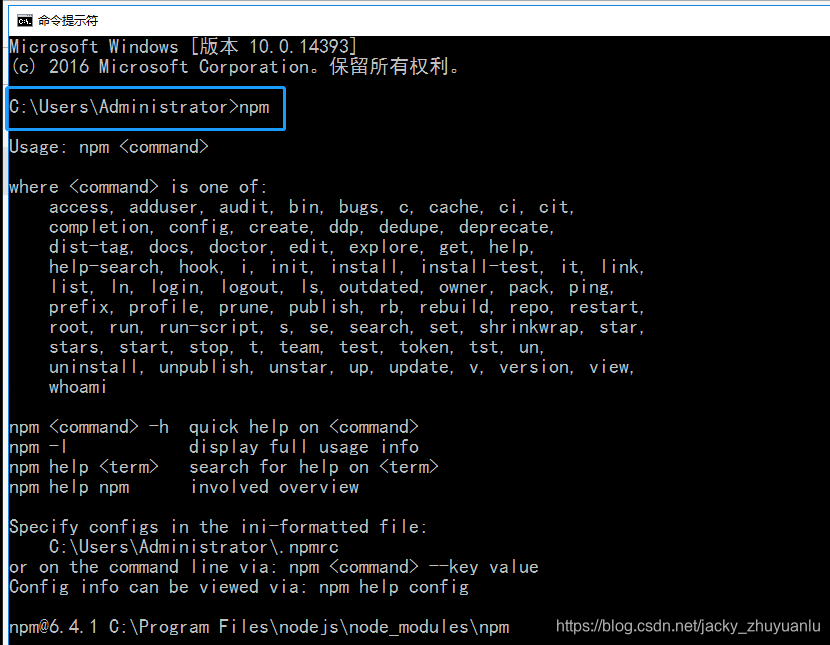
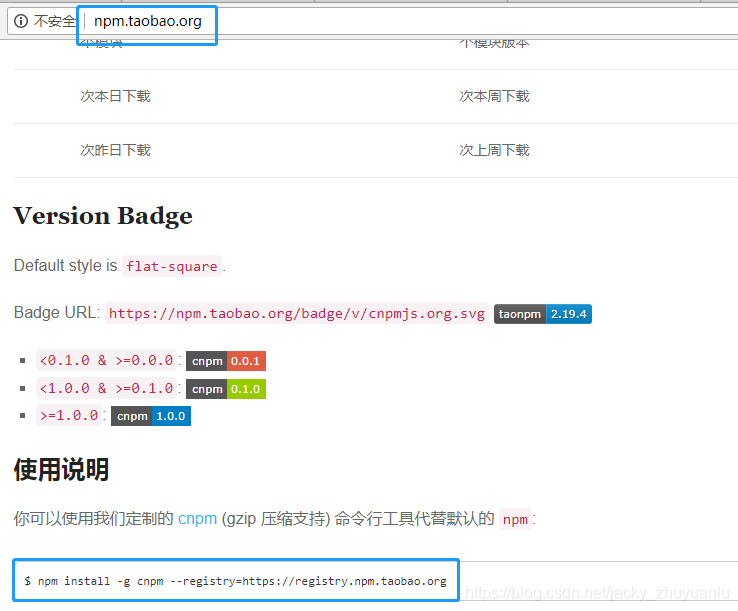
第三步:安装cnpm
npm就相当于python中的pip,中央仓库在国外,下载速度极慢,所以选择淘宝镜像的cnpm代替npm;
第4步:安装head插件
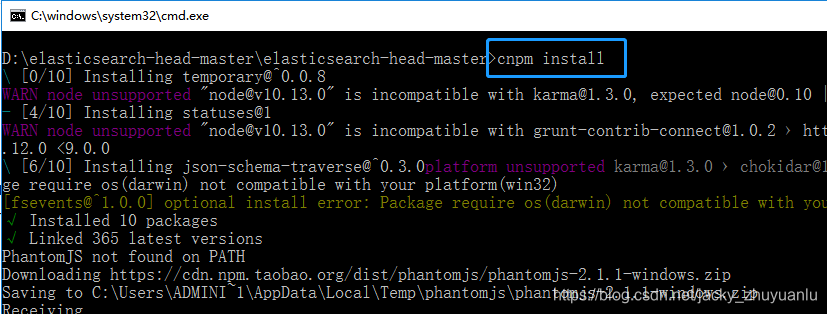
第5步 : 运行head插件
- head 文件下:cnpm run start

- head 文件下:cnpm run start
elasticsearch安全策略规定:elasitcsearch默认不允许使用第三方的服务,为了可以满足head这个代理服务可以访问elasticsearch,我们要对elasticsearch进行一些配置上的改动;
第6步 : 重新配置elasticsearch
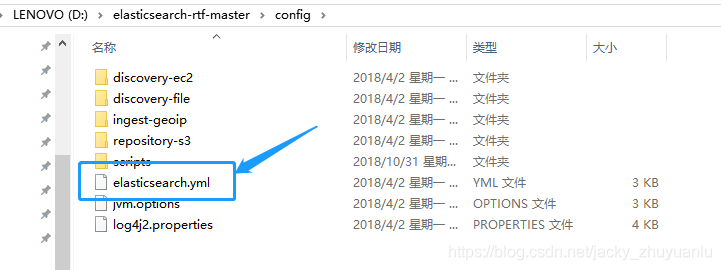
我们看到显示未连接,我们需要配置elasticsearch-rtf(搜索引擎)连接,在elasticsearch-rtf/config/elasticsearch.yml 这个文件里配置,在文件的最后面写入:
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-methods: OPTIONS, HEAD, GET, POST, PUT, DELETE
- 第7步:重启elasticsearch-rtf(搜索引擎)后就可以连接了
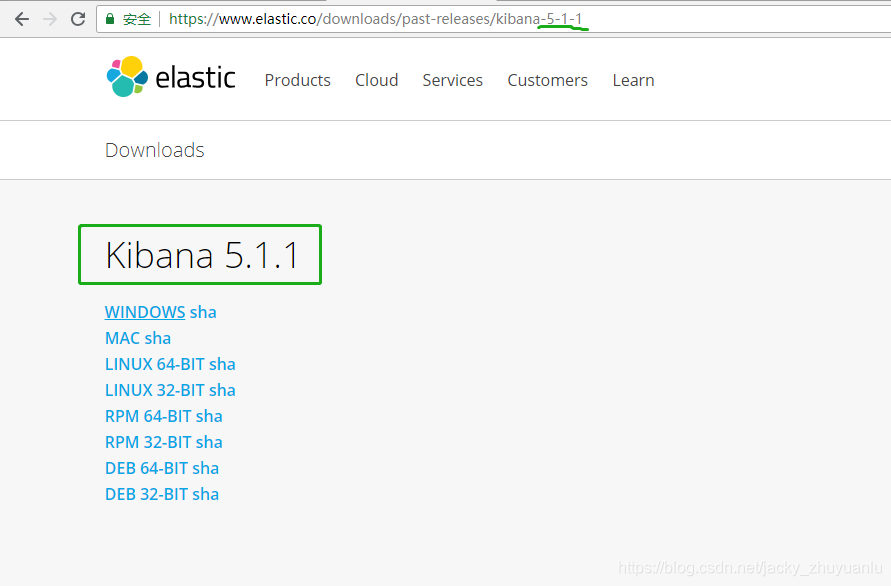
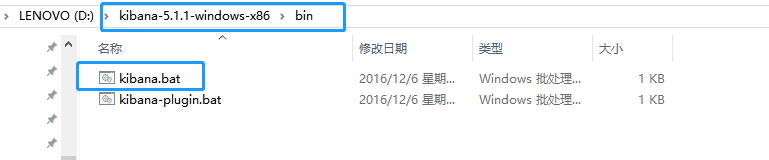
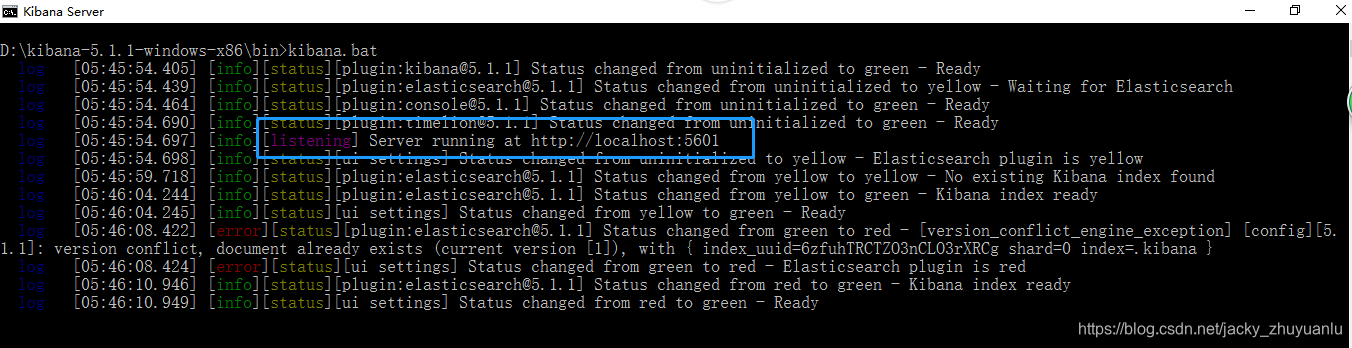
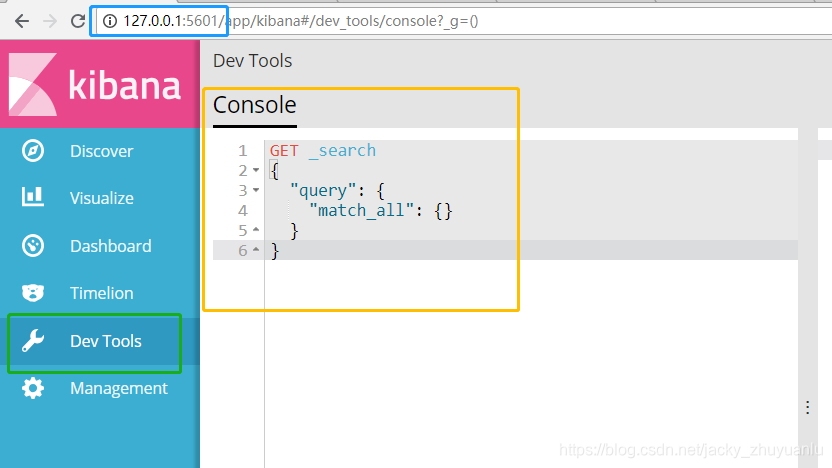
(四)Kibana 插件的安装
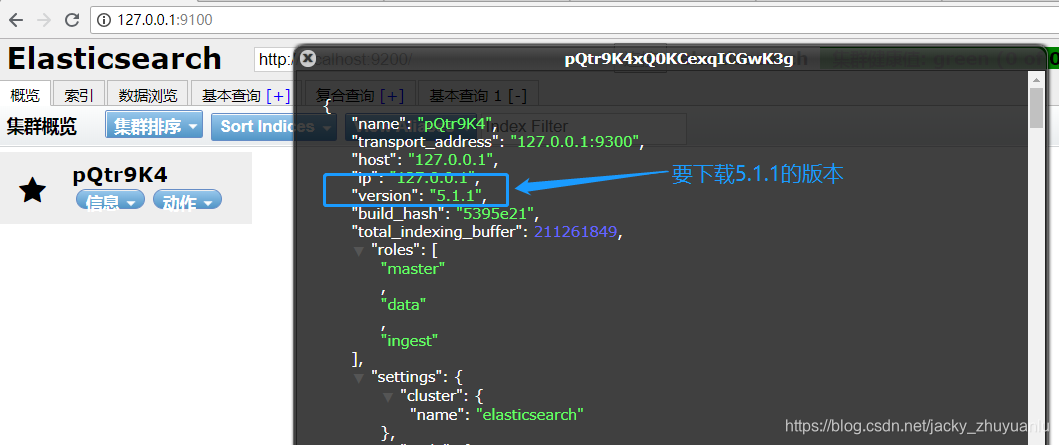
- 注意:Kibana的版本要对应elasticsearch-head里信息里的版本
如何用elasticsearch构架亿级数据采集系统(第1集:非生产环境windows安装篇)的更多相关文章
- MySQL使用pt-online-change-schema工具在线修改1.6亿级数据表结构
摘 要:本文阐述了MySQL DDL 的问题现状.pt-online-schema-change的工作原理,并实际利用pt-online-schema-change工具在线修改生产环境下1.6亿级数 ...
- 通用技术 mysql 亿级数据优化
通用技术 mysql 亿级数据优化 一定要正确设计索引 一定要避免SQL语句全表扫描,所以SQL一定要走索引(如:一切的 > < != 等等之类的写法都会导致全表扫描) 一定要避免 lim ...
- 不停机不停服务,MYSQL可以这样修改亿级数据表结构
摘 要:本文阐述了MySQL DDL 的问题现状.pt-online-schema-change的工作原理,并实际利用pt-online-schema-change工具在线修改生产环境下1.6亿级数 ...
- 基于Mysql数据库亿级数据下的分库分表方案
移动互联网时代,海量的用户数据每天都在产生,基于用户使用数据的用户行为分析等这样的分析,都需要依靠数据都统计和分析,当数据量小时,问题没有暴露出来,数据库方面的优化显得不太重要,一旦数据量越来越大时, ...
- Mongodb亿级数据量的性能测试
进行了一下Mongodb亿级数据量的性能测试,分别测试如下几个项目: (所有插入都是单线程进行,所有读取都是多线程进行) 1) 普通插入性能 (插入的数据每条大约在1KB左右) 2) 批量插入性能 ...
- 巧用redis位图存储亿级数据与访问 - 简书
原文:巧用redis位图存储亿级数据与访问 - 简书 业务背景 现有一个业务需求,需要从一批很大的用户活跃数据(2亿+)中判断用户是否是活跃用户.由于此数据是基于用户的各种行为日志清洗才能得到,数据部 ...
- NEO4J亿级数据导入导出以及数据更新
1.添加配置 apoc.export.file.enabled=true apoc.import.file.enabled=true dbms.directories.import=import db ...
- NEO4J亿级数据全文索引构建优化
NEO4J亿级数据全文索引构建优化 一.数据量规模(亿级) 二.构建索引的方式 三.构建索引发生的异常 四.全文索引代码优化 1.Java.lang.OutOfMemoryError 2.访问数据库时 ...
- Mybatis 使用分页查询亿级数据 性能问题 DB使用ORACLE
一般用到了mybatis框架分页就不用自己写了 直接用RowBounds对象就可以实现,但这个性能确实很低 今天我用到10w级得数据分页查询,到后面几页就迭代了很慢 用于记录 1.10万级数据如下 [ ...
随机推荐
- 敏感词检测、屏蔽设计(iOS & Android)
敏感词检测 服务器端最常使用的算法是DFA算法.如果服务器端使用java实现常规的DFA算法,假若... 源码:https://github.com/qiyer/DFA_Cplusplus
- jupyter安装出现问题:安装后无法打开
jupyter安装出现问题:安装后无法打开 traitlets.traitlets.TraitError: Could not decode 'C:\Users\\xce\xa2\xcc\xf0\xd ...
- Linux下使用shell脚本自动备份和移动数据到大容量存储
自动备份数据库,并将备份前一天的数据移动拷贝到存储上. 需求来源是因为linux系统层的磁盘存储容量过小,数据库自动备份之后日积月累数据越来越多,而且还不想删除旧数据.那解决方法就是在linux系统主 ...
- redhat6.7环境下oracle11gR2 RAC静默安装
(一)基础环境 虚拟机环境 :vmware workstation 12 操作系统 : redhat6.7 - 64bit 数据库版本 :11.2.0.4 (二)安装前的环境准备 (2.1)配置 ...
- php基本数据类型
trim()函数,用于去除字符串首尾空格和特殊字符返回的是去掉的空格和特殊字符后的字符串 string trim(string str [,string charlist]); str 要操作的字符串 ...
- prometheus operator 部署
prometheus operator 部署自定义记录 环境: k8s 1.11集群版本,kubeadm部署 docker 17.3.2版本 Centos 7系统 阿里云服务器 operator 源码 ...
- MYSQL中的乐观锁实现(MVCC)简析
https://segmentfault.com/a/1190000009374567#articleHeader2 什么是MVCC MVCC即Multi-Version Concurrency Co ...
- 在linux上搭建SVN服务器并自动更新至WEB目录
1.仓库放在 /var/svn/ 目录下,并且仓库名为 project 2.创建用户组user,该组下添加两个成员user1.user2,密码直接用用户名,两用户可以checkout代码和提交代码 3 ...
- Vue中mapMutations映射方法的问题
今天又被自己给蠢到,找了半天没发现问题.大家看下代码. mutation-types.js 里我新增了一个类型.INIT_CURRENTORDER export const GET_USERINFO ...
- 【转】MarkDown添加图片的三种方式
原文:https://www.jianshu.com/p/280c6a6f2594 ----------------------------------------------------- 插图最基 ...