【python爬虫】每天统计一遍up主粉丝数!
每天统计一遍up主粉丝数!
第一步,爬取up主的粉丝信息
为了方便,这里我把它写成了一个函数
1.首先导入需要的包
requests是必不可少的!
import requests as req
想要记录下统计的时间,那么就需要用到相应的时间函数
from time import strftime, localtime
2.为了方便,把它写成一个函数
接收两个参数,分别为up主的mid和自定义名字,mid就是up主个人空间网页地址栏最后的那串数字。没有自定义名字的话,会自动显示成mid的,这点不用担心哦~

def fans(mid, name=-1):
mid = str(mid)
name = str(name)
if name == -1:
name = mid
url = "https://api.bilibili.com/x/relation/stat?vmid=" + mid + "&jsonp=jsonp"
resp = req.get(url)# 通过url爬取到我们想要的json数据
info = eval(resp.text)
with open(name + '粉丝数统计.txt', 'a') as f:
f.write(strftime("%Y", localtime()) + "年" + strftime("%m", localtime()) + "月" + strftime("%d",
localtime()) + "日" + name + "粉丝数:" + str(
info['data']['follower']) + '\n')# 获取data中的follower就是粉丝数啦
print(strftime("%Y", localtime()) + "年" + strftime("%m", localtime()) + "月" + strftime("%d",
localtime()) + "日" + name + "粉丝数:" + str(
info['data']['follower']) + '\n')
3.那么就调用一下这个函数吧!
if __name__ == "__main__":
fans(36874384, '谜叔录播机')
fans(673816, "谜之声")
4.运行一下,成功啦!
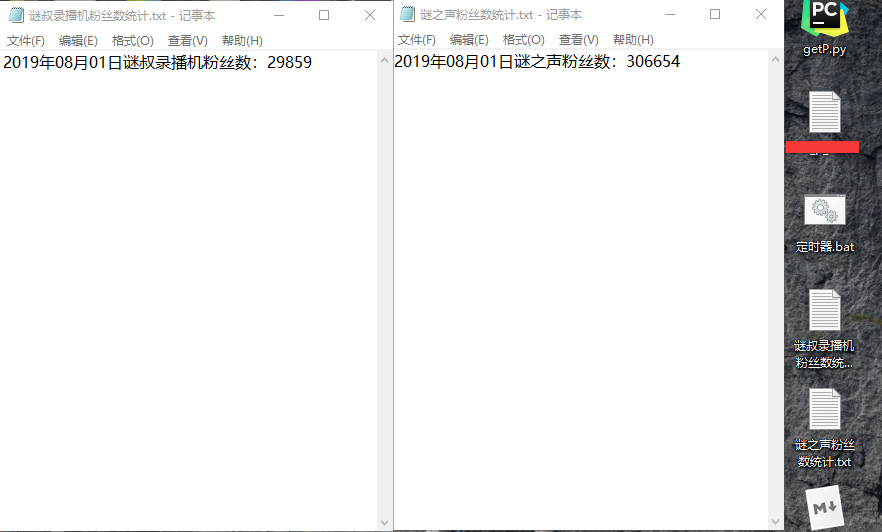
第二,说好的每天统计一遍呢,我要一天点一次吗?
1.当然不!写一个bat文件就好啦!
每当0点的时候就会自动执行一遍python文件哦我给它起名叫'定时器.bat',不用忘记一直挂着它,嘻嘻
if 0 equ %time:~0,2% (
python getP.py
)
timeout 3600
总结
很简单哦,大家都可以去试试,统计一下自己喜欢的up主的粉丝量变化,相信一定是一个增函数吧嘻嘻~
当然也可以不局限于每天监测一次,不过更具体地就需要大家自己去试啦,我只做了一天统计一次的~
【python爬虫】每天统计一遍up主粉丝数!的更多相关文章
- Java + golang 爬取B站up主粉丝数
自从学习了爬虫,就想在B站爬取点什么数据,最近看到一些个up主涨粉很快,于是对up主的粉丝数量产生了好奇,所以就有了标题~ 首先,我天真的以为通过up主个人空间的地址就能爬到 https://spac ...
- 爬取腾讯网的热点新闻文章 并进行词频统计(Python爬虫+词频统计)
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:一棵程序树 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- Python爬虫(三)——对豆瓣图书各模块评论数与评分图形化分析
文化 经管 ....略 结论: 一个模块的评分与评论数相关,评分为 [8.8——9.2] 之间的书籍评论数往往是模块中最多的
- 【Python】【爬虫】如何学习Python爬虫?
如何学习Python爬虫[入门篇]? 路人甲 1 年前 想写这么一篇文章,但是知乎社区爬虫大神很多,光是整理他们的答案就够我这篇文章的内容了.对于我个人来说我更喜欢那种非常实用的教程,这种教程对于想直 ...
- Python爬虫(四)——开封市58同城数据模型训练与检测
前文参考: Python爬虫(一)——开封市58同城租房信息 Python爬虫(二)——对开封市58同城出租房数据进行分析 Python爬虫(三)——对豆瓣图书各模块评论数与评分图形化分析 数据的构建 ...
- Python爬虫(四)——豆瓣数据模型训练与检测
前文参考: Python爬虫(一)——豆瓣下图书信息 Python爬虫(二)——豆瓣图书决策树构建 Python爬虫(三)——对豆瓣图书各模块评论数与评分图形化分析 数据的构建 在这张表中我们可以发现 ...
- python爬虫--看看虎牙女主播中谁颜值最高
目录 爬虫 百度人脸识别接口 效果演示 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做案例的人,却不知道如何去学习更加高深的知 ...
- [python爬虫] Selenium定向爬取海量精美图片及搜索引擎杂谈
我自认为这是自己写过博客中一篇比较优秀的文章,同时也是在深夜凌晨2点满怀着激情和愉悦之心完成的.首先通过这篇文章,你能学到以下几点: 1.可以了解Python简单爬取图片的一些思路和方法 ...
- Python爬虫 获得淘宝商品评论
自从写了第一个sina爬虫,便一发不可收拾.进入淘宝评论爬虫正题: 在做这个的时候,也没有深思到底爬取商品评论有什么用,后来,爬下来了数据.觉得这些数据可以用于帮助分析商品的评论,从而为用户选择商品提 ...
随机推荐
- Docker镜像(六)
一.镜像是什么 镜像是一种轻量级.可执行的独立软件包,用来打包软件运行环境和基于运行环境开发的软件,它包含运行某个软件所需的所有内容,包括代码.运行时.库.环境变量和配置文件. 1. UnionFS( ...
- webapi基于单请求封装多请求的设计【转】
怎么说,单请求封装多请求,这句话确实有点绕了,但还是要看清楚,想明白这到底是怎么一回事,单请求即一次请求(get,post,put,delete),封闭多请求,即在客户端发送的一个请求中可能包含多个子 ...
- perf-tools 简单试用
per-tools 是性能优化大师brendan gregg 就有perf 以及ftrace 编写的性能优化工具集 提供了io .网络.系统调用...大部分方面的性能分析工具. 一张参考图 安装 cl ...
- django报错:django.core.exceptions.ImproperlyConfigured: Error loading MySQLdb module. Did you install mysqlclient?
django 迁移数据库报错 django.core.exceptions.ImproperlyConfigured: Error loading MySQLdb module.Did you ins ...
- <Trie> 212 <Array> 229
212. Word Search II class TrieNode{ char val; TrieNode[] children; String word; public TrieNode(char ...
- 详解 ASP.NET Core MVC 的设计模式
MVC 是什么?它是如何工作的?我们来解剖它 在本节课中我们要讨论的内容: 什么是 MVC? 它是如何工作的? 什么是 MVC MVC 由三个基本部分组成 - 模型(Model),视图(View)和控 ...
- linux数据库中使用MD5加密
MD5加密算法源码下载:https://pan.baidu.com/s/1nwyN0xV 下载完成了之后解压,得到两个文件 环境搭建: 1.把md5.h文件拷贝到/usr/include/目录下 su ...
- java if 条件语句
import java.util.Scanner; public class Sample { public static void main(String[] args) { int num; Sc ...
- spring cloud gateway网关启动报错:No qualifying bean of type 'org.springframework.web.reactive.DispatcherHandler'
网关配置好后启动报错如下: org.springframework.context.ApplicationContextException: Unable to start web server; n ...
- QLayout及其子类 清除添加的widget
起初,我的思路是,先取得Layout的items数量, 然后通过索引来移除每一个items,代码如下: QHBoxLayout * hly = new QHBoxLayout; ; i < ; ...