hadoop综合
对CSV文件进行预处理生成无标题文本文件,将爬虫大作业产生的csv文件上传到HDFS
首先,我们需要在本地中创建一个/usr/local/bigdatacase/dataset文件夹,具体的步骤为:
① cd /usr/local
② sudo mkdir bigdatacase
③ cd bigdatacase/
④ sudo mkdir dataset
⑤ cd dataset/
如下图所示:

其次,我们把lagoupy.csv文件放到下载这个文件夹中,并使用命令把lagoupy.csv文件拷贝到我们刚刚所创建的文件夹中,具体步骤如下:
① sudo cp /home/chen/下载/lagoupy.csv /usr/local/bigdatacase/dataset/ #把lagoupy.csv文件拷到刚刚所创建的文件夹中
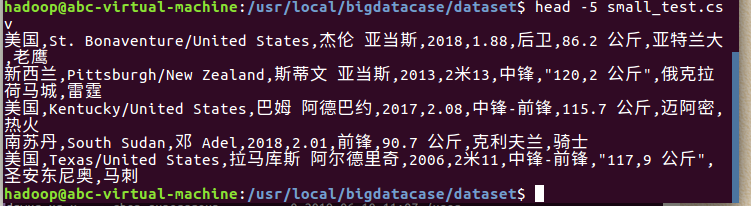
② head -5 small_test.csv #查看这个文件的前五行

对CSV文件进行预处理生成无标题文本文件,步骤如下:
① sudo sed -i '1d' lagoupy.csv #删除第一行记录
② head -5 small_test.csv #查看前五行记录
如下图所示:
接着,启动hadoop,步骤如下:
① start-all.sh #启动hadoop
② jps #查看hadoop是否启动成功
如下图所示:

最后,我们把本地的文件上传至HDFS中,步骤如下:
① hdfs dfs -mkdir -p /bigdatacase/dataset #在hdfs上新建/bigdatacase/dataset
② hdfs dfs -ls /
③ hdfs dfs -put ./lagoupy.csv /bigdatacase/dataset #把本地文件small_test.csv上传至hdfs中
④ hdfs dfs -ls /bigdatacase/dataset #查看
⑤ hdfs dfs -cat /bigdatacase/dataset/small_test.csv | head -5 #查看hdfs中small_test.csv的前五行
如下图所示:

把hdfs中的文本文件最终导入到数据仓库Hive中
首先,启动hive,步骤如下:
① service mysql start #启动mysql数据库
② cd /usr/local/hive
③ ./bin/hive #启动hive
如下图所示:

① create database db; -- 创建数据库dbpy
② use db;
③ create external table labling
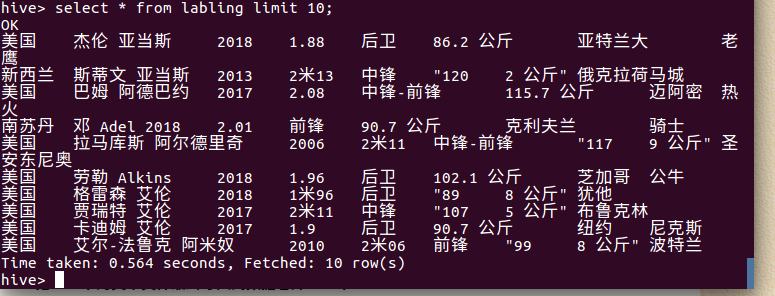
④ select * from labling limit 10; -- 查看lagou_py中前10行的数据
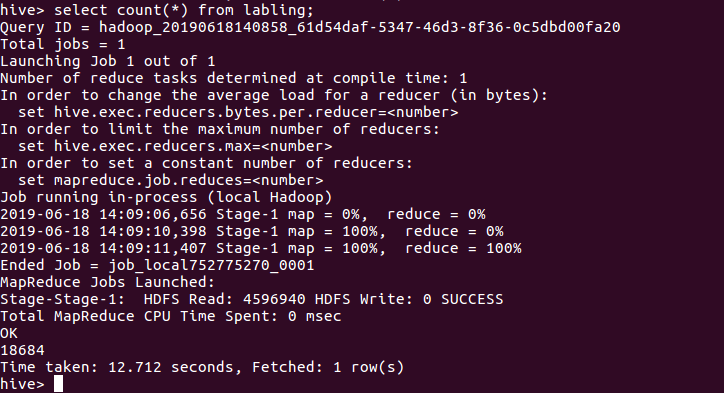
查询条数统计分析
用聚合函数count()计算出表内有多少条行数据 hive> select count(*) from labling;
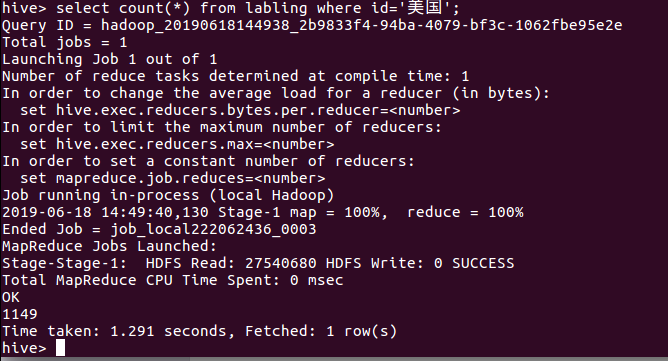
美国国籍的球员数:
美国国籍的球员:
查询老鹰的球员:
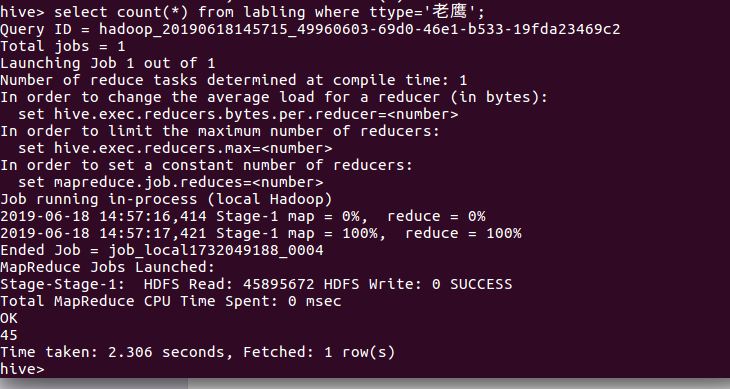
查询老鹰的球员数:
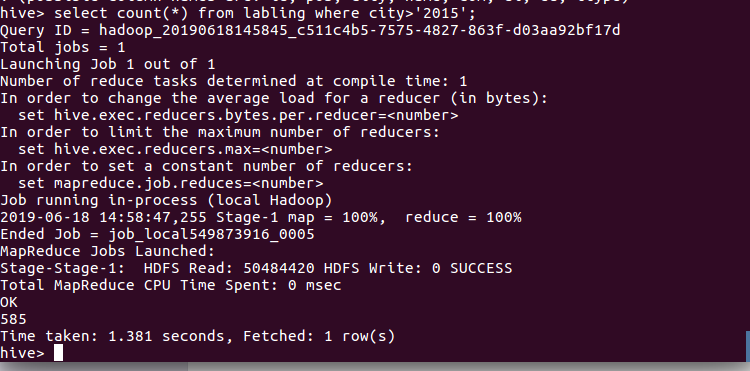
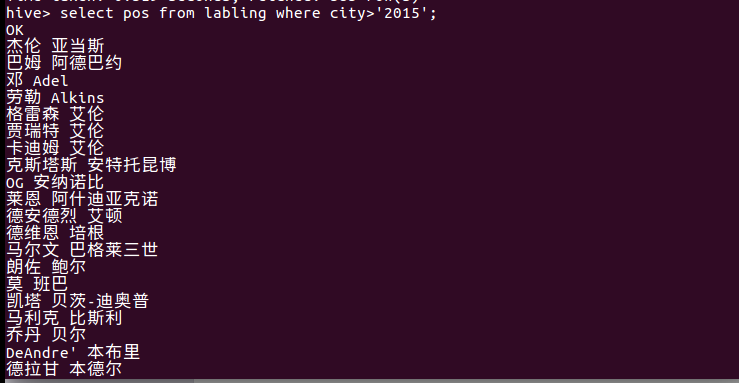
查询球员2015年以后进入NBA的人数:
查询2015年以后进入NBA球员的名字
hadoop综合的更多相关文章
- Hadoop综合大作业
Hadoop综合大作业 要求: 用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计. 用Hive对爬虫大作业产生的csv文件进行数据分析 1. 用Hive对爬虫大作业产 ...
- Hadoop 综合揭秘——HBase的原理与应用
前言 现今互联网科技发展日新月异,大数据.云计算.人工智能等技术已经成为前瞻性产品,海量数据和超高并发让传统的 Web2.0 网站有点力不从心,暴露了很多难以克服的问题.为此,Google.Amazo ...
- Hadoop 综合揭秘——MapReduce 基础编程(介绍 Combine、Partitioner、WritableComparable、WritableComparator 使用方式)
前言 本文主要介绍 MapReduce 的原理及开发,讲解如何利用 Combine.Partitioner.WritableComparator等组件对数据进行排序筛选聚合分组的功能.由于文章是针对开 ...
- 大数据应用期末总评——Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 Hadoop综合大作业 要求: 1.将爬虫大作业产生的csv文件 ...
- 【大数据应用期末总评】Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 一.Hadoop综合大作业 要求: 1.将爬虫大作业产生的csv ...
- 《Hadoop综合大作业》
作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 我主要的爬取内容是关于热门微博文章“996”与日剧<我要 ...
- 菜鸟学IT之Hadoop综合大作业
Hadoop综合大作业 作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 1.将爬虫大作业产生的csv文件上传到HDF ...
- 大数据应用期末总评Hadoop综合大作业
作业要求来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 1.将爬虫大作业产生的csv文件上传到HDFS 此次作业选取的 ...
- Hadoop综合大作业1
本次作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 一.课程评分标准: 分数组成: 考勤 10 平时作业 30 爬 ...
- 【大数据应用技术】作业十二|Hadoop综合大作业
本次作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 前言 本次作业是在<爬虫大作业>的基础上进行的 ...
随机推荐
- 电缆公司如何面对企业改革?MES系统打造智能工厂
项目背景 目前,“互联网+电缆”正在成为电缆行业发展的主流,作为中国领先的大型电缆企业江苏亨通电力电缆有限公司(简称“亨通电缆”)积极响应国家提出的“中国制造2025”号召,实施MES工程项目,启用智 ...
- Linux内核同步机制之completion
内核编程中常见的一种模式是,在当前线程之外初始化某个活动,然后等待该活动的结束.这个活动可能是,创建一个新的内核线程或者新的用户空间进程.对一个已有进程的某个请求,或者某种类型的硬件动作,等等.在这种 ...
- php 文件包含 include、include_once、require、require_once
简言之,include某文件:把某文件的代码粘过来,如果该文件不存在,也继续执行下面的代码,带_once的是看看之前引用过没,引用过就不引用了(_once这行代码的心里活动:“之后引用过没有我不关心, ...
- SPI bus 的收发编程
https://linux-sunxi.org/SPIdev The SPI bus (or Serial Peripheral Interface bus) is a synchronous ser ...
- Linux命令——chattr、lsattr
简介 chattr用于设置文件隐藏属性,lsattr用于查看文件隐藏属性.隐藏属性对系统很有用,尤其是系统安全这一块.但是这两个命令只能在Ext2/Ext3上面有用,其他文件系统可能不支持. chat ...
- Vue和微信小程序区别
一.生命周期 先贴两张图: vue生命周期 小程序生命周期 相比之下,小程序的钩子函数要简单得多. vue的钩子函数在跳转新页面时,钩子函数都会触发,但是小程序的钩子函数,页面不同的跳转方式,触发的钩 ...
- 使用树莓派GPIO控制继电器
一.使用方法总结: VCC接+5v,GND接负,IN1接GPIO口, 二.然后使用Linux命令或者编程控制GPIO口高低电位即可,如:执行下列命令: gpio readall 列出所有针角 gp ...
- Docker创建mysql镜像
原文: https://blog.csdn.net/uk8692/article/details/49386679 https://blog.csdn.net/qq362228416/article/ ...
- [CSS] prefers-reduced-motion
The prefers-reduced-motion CSS media feature is used to detect if the user has requested that the sy ...
- LeetCode 1043. Partition Array for Maximum Sum
原题链接在这里:https://leetcode.com/problems/partition-array-for-maximum-sum/ 题目: Given an integer array A, ...