大数据应用期末总评Hadoop综合大作业
作业要求来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
1.将爬虫大作业产生的csv文件上传到HDFS
此次作业选取的是爬虫《人性的弱点全集》短评数据生成的cm.csv文件;爬取的数据总数为10991条。
cm.csv文件数据如下图所示:
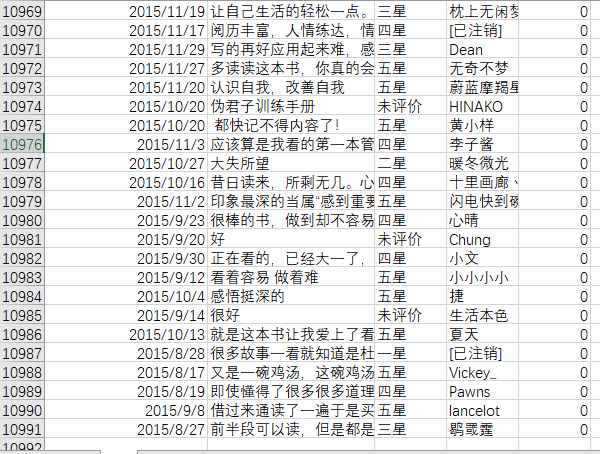
将cm.csv文件上存到HDFS
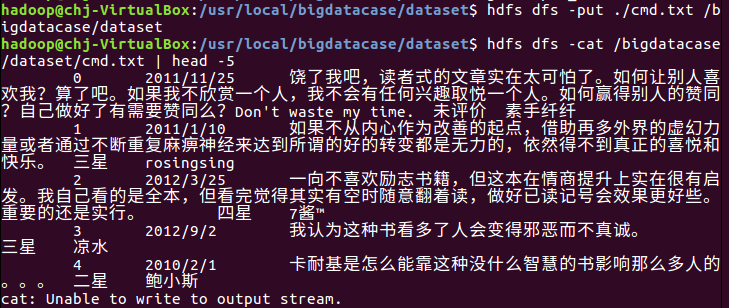
2.对CSV文件进行预处理生成无标题文本文件
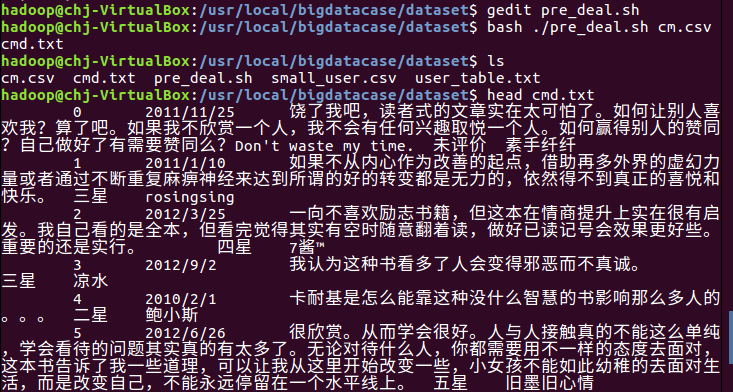
csv文件数据预处理,删除第一行字段名称

编辑pre_deal.sh文件进行数据的取舍处理

让pre_deal.sh文件生效,并显示前面几条数据
3.把hdfs中的文本文件最终导入到数据仓库Hive中
在hive中创建bdlab数据库,显示如下:

因为此次使用的是bdlab的数据库,所以在bdlab中创建相应的表为bigdata_cmd

4.在Hive中查看并分析数据
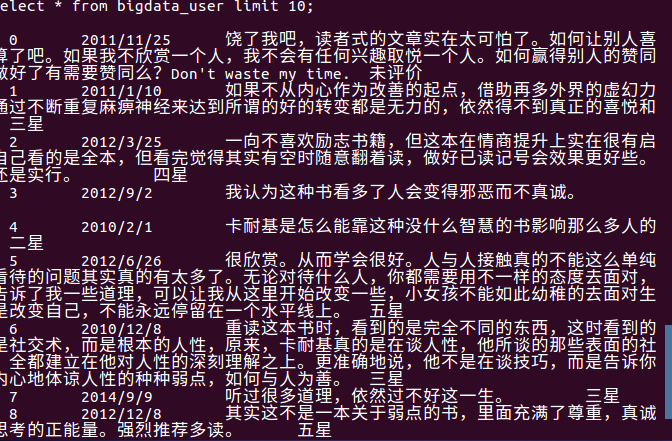
数据分析:图上显示,该爬取的数据属性主要包括评价的日期、评价的内容、用户名称和星级(一些无关分析的属性在进行数据预处理的时候已经去除,剩下的是有关数据分析的属性)。以上显示的数据可以看到一些读者对《人性的弱点全集》这本书的一些好的坏的态度。以下利用Hive进行更进一步的数据分析。
5.用Hive对爬虫大作业产生的进行数据分析,写一篇博客描述你的分析过程和分析结果。(10条以上的查询分析)
(1)查询前20条用户的星级评价
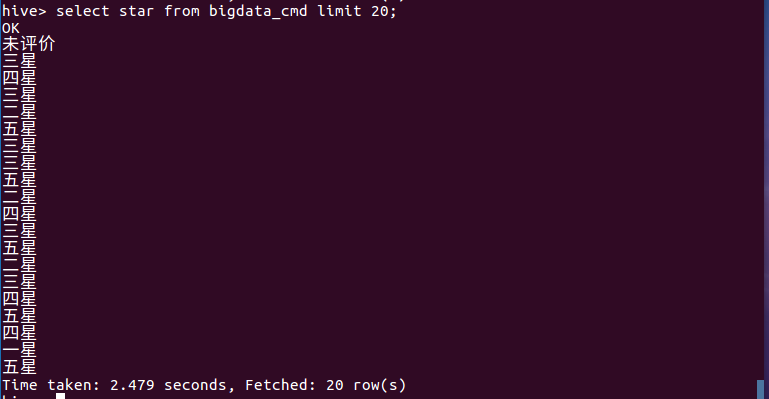
分析:上图所示的查询内容显示,评星三星以上的占较大的一部分;四星、五星的总占比约占一半(五星为满星),这说明读者们对于《人性的弱点全集》这本书的评价还是算中上等水平的,这也从侧面反映出该书是一本不错的书。
(2)查询读者给该书一星评星的短评


分析:上图所示的查询内容显示,读者们给该书评一星的原因是读者们认为这本书一味的励志,一味的给读者灌输一些通俗易懂却光说不练的道理,过于的心灵鸡汤。这是读者们反感它的地方以及给出一星评价的原因。
(3)查询读者给该书三星(即中评,不喜不厌的态度)评星的短评


分析:上图所示的查询内容显示,读者们认为该书的内容是有用的,对于人的成长也是有一定的帮助的,但是对于书本推销式的表达方式读者还是略显反感;整本书读下来也略显枯燥。这些都是读者们评三星的不喜不厌的原因。
(4)查询读者给该书五星评星的短评

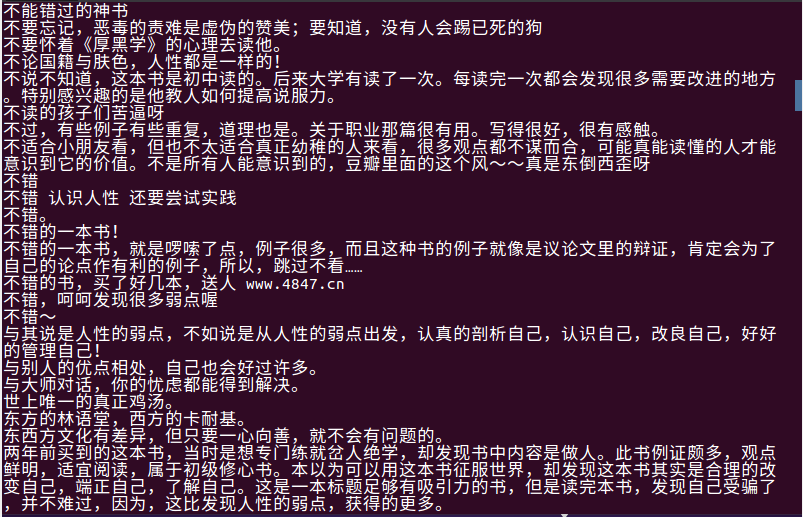

分析:上图所示的查询内容显示,读者们给该书评五星的原因是读者们认为这是一本不错的书,也非常的经典,能给人深省和能读懂一些道理会让读者有一些感触,是值得一看的经典之书。所以读者买账的地方可能就是该书能给读者带来一些感触反省和一些道理。
(5)查询读者高评星与低评星数量(高低评星以三星为界限)
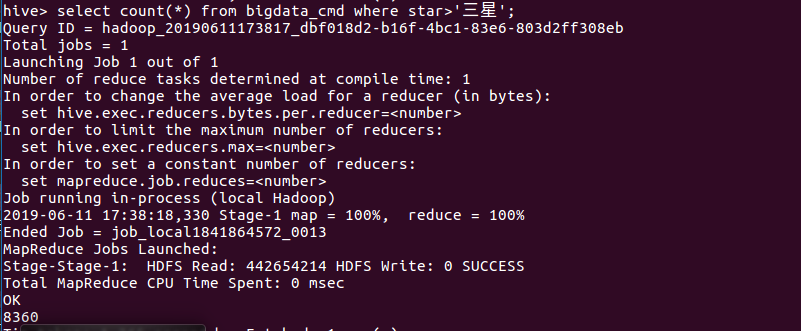
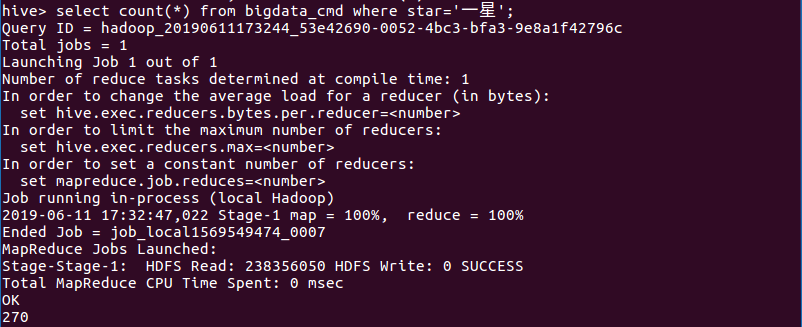

分析:上图所示查询内容显示,高评星(4星、5星)的数量为8360条,低评星(1星、2星)的数量为722条。从数量上比较可以知道读者对于《人性的弱点全集》这本书大体是持好的敏感度的,大多的读者认为这是一本好书,总体的评价也是好的趋向的。
(6)查询评五星的用户名


(7)查询cm.csv文件数据中用户名不重复的数据量

分析:上图所示查询内容显示,用户名不重复评论的数据为4958条,差不多占数据量的一半,说明爬取的数据中因用户名重复的数据还是较多的,也说明的是同一个用户有过多次评论的可能,衍生的一个可能是同一个用户名的用户不同时间多次阅读该书从而发表的不同的评价;如果是这个可能同一个用户评论的内容也还是拥有参考价值的,但是还是要注意过多的数据重复。
(8)查询cm.csv文件数据中评论不重复的数据量

分析:上图所示查询内容显示,评论内容不重复的数据为5627条,占爬取总数据的一半往上。说明有5627条读者评论数据不存在重复,可用性的数据量还是较大的;较大的可用性数据量在做数据分析的时候是能够更准确的把握读者的对该书的态度和总体的评价的,所以此次的可用性数据和此次的数据分析是有一定的意义和参考价值的。
(9)查询读者给该高评价的短评



分析:上图所示查询内容显示,让人受益匪浅、启发、励志、实用和值得深思等是读者给该书高评价的原因,这些都是读者买该书账的地方。一个繁杂的社会、一个谁都不容易的社会氛围需要一些正面的东西来给人们一些前进的力量,读者可能可以在书中找到内心共鸣的地方所以喜欢这本书也所以给该书高的评价。
(10)查询三星评价数量
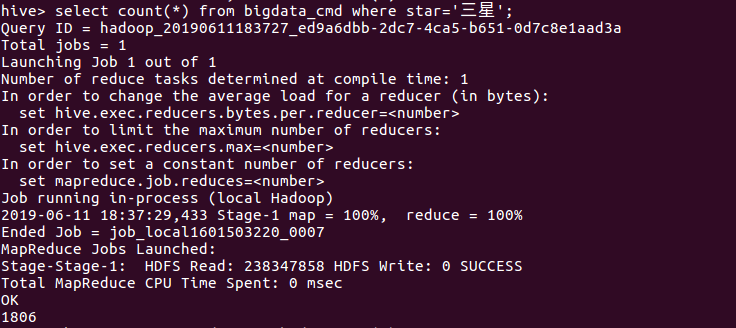
分析:上图所示查询内容显示,三星评价的数据量为1806条,约占总数据量的10%,比例不大;这也说明有将近一成的读者对于《人性的弱点全集》这本书不感冒。
(11)查询五星评价处于表格的序号


以上为此次Hadoop综合大作业的所有内容。从Ubuntu到MySQL到Hadoop到hbase到hive再到整个Hadoop整个环境的配置完成,这一路下来都是为最后的这个综合作业做准备。这期间,遇到过这个系统环境安装配置好到进不去hive,遇到过输入法的输入出错,遇到过格式化丢失Datanode等一系列的问题;这个过程必须是细心谨慎的,要不就是一步错后面就会卡死无法进行下去。学了几次这些内容,这次是比较有条理的一次。
大数据应用期末总评Hadoop综合大作业的更多相关文章
- 大数据应用期末总评——Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 Hadoop综合大作业 要求: 1.将爬虫大作业产生的csv文件 ...
- 【大数据应用期末总评】Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 一.Hadoop综合大作业 要求: 1.将爬虫大作业产生的csv ...
- 大数据应用期末总评(hadoop综合大作业)
作业要求源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 一.将爬虫大作业产生的csv文件上传到HDFS (1)在/usr ...
- Hadoop综合大作业
Hadoop综合大作业 要求: 用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计. 用Hive对爬虫大作业产生的csv文件进行数据分析 1. 用Hive对爬虫大作业产 ...
- 《Hadoop综合大作业》
作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 我主要的爬取内容是关于热门微博文章“996”与日剧<我要 ...
- 菜鸟学IT之Hadoop综合大作业
Hadoop综合大作业 作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 1.将爬虫大作业产生的csv文件上传到HDF ...
- Hadoop综合大作业1
本次作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 一.课程评分标准: 分数组成: 考勤 10 平时作业 30 爬 ...
- 大数据平台搭建(hadoop+spark)
大数据平台搭建(hadoop+spark) 一.基本信息 1. 服务器基本信息 主机名 ip地址 安装服务 spark-master 172.16.200.81 jdk.hadoop.spark.sc ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
随机推荐
- Tomcat启动找不到项目依赖jar的解决方式
一.背景 最近在写一个MQ框架-gmq,先写的服务端,然后写客户端.感觉服务端和客户端分成两个独立的项目不合适,于是改成了maven父子模块的形式.父项目相当于一个壳,里面包含服务端.客户端两个模块. ...
- js 时间常用处理方法
众所周知,JavaScript核心包含Data()构造函数,用来创建表示时间和日期的对象. 今天主要跟大家梳理一下,常用的时间.日期处理方法,方便大家使用和理解 格式化时间 老生常谈,大概会这么写 1 ...
- Trunk 实现跨交换机 VLAN 通信
当网络中有多台交换机时,位于不同交换机上的相同VLAN的主机之间时如何通信的呢?我们使用Trunk实现跨交换机VLAN通信.还有以太网通道的操作哦. 实验拓扑 两台交换机直连,每台下面再连接两台VPC ...
- VLAN实验5:利用三层交换机实现VLAN间路由
实验环境: 实验拓扑图: 实验编址: 实验步骤:1.基本配置按照实验编址表在PC上进行基本的IP地址配置,三层交换机上先不做任何配置. 测试PC1与PC2的连通性 正常 测试PC1与PC3的连通性 ...
- Codeforces C. Jzzhu and Cities(dijkstra最短路)
题目描述: Jzzhu and Cities time limit per test 2 seconds memory limit per test 256 megabytes input stand ...
- 2019年牛客多校第一场 H题XOR 线性基
题目链接 传送门 题意 求\(n\)个数中子集内所有数异或为\(0\)的子集大小之和. 思路 对于子集大小我们不好维护,因此我们可以转换思路变成求每个数的贡献. 首先我们将所有数的线性基的基底\(b\ ...
- Spring Cloud Zuul网关(快速搭建)
zuul 是netflix开源的一个API Gateway 服务器, 本质上是一个web servlet应用. 在云平台上提供动态路由,监控,弹性,安全等边缘服务的框架.相当于是设备和 Netflix ...
- Oracle 中select XX_id_seq.nextval from dual 什么意思呢?
说明 今天看别人的代码 ,遇见了 一条sql select ctg_fault_list_id_seq.nextval from dual 不懂意思,然后就研究了下 dual :是oracle ...
- Python 通过lxml遍历html xpath
#coding:utf-8 ''' Created on 2017年10月9日 @author: li.liu ''' from selenium import webdriver from lxml ...
- dt系统中tag如何使用like与%来进行模糊查询
在destoon中,如果一个品牌的详细显示页,如果要显示与品牌相关的供应的话,可以通过查询标题中带有品牌关键字的这一条件来进行查询,但是经过测试发现不能正确解析, 然后查看文件的源文件,发现 {tag ...