hadoop综合
对CSV文件进行预处理生成无标题文本文件,将爬虫大作业产生的csv文件上传到HDFS
首先,我们需要在本地中创建一个/usr/local/bigdatacase/dataset文件夹,具体的步骤为:
① cd /usr/local
② sudo mkdir bigdatacase
③ cd bigdatacase/
④ sudo mkdir dataset
⑤ cd dataset/
如下图所示:

其次,我们把lagoupy.csv文件放到下载这个文件夹中,并使用命令把lagoupy.csv文件拷贝到我们刚刚所创建的文件夹中,具体步骤如下:
① sudo cp /home/chen/下载/lagoupy.csv /usr/local/bigdatacase/dataset/ #把lagoupy.csv文件拷到刚刚所创建的文件夹中
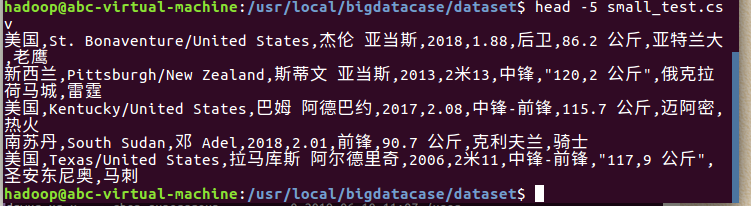
② head -5 small_test.csv #查看这个文件的前五行

对CSV文件进行预处理生成无标题文本文件,步骤如下:
① sudo sed -i '1d' lagoupy.csv #删除第一行记录
② head -5 small_test.csv #查看前五行记录
如下图所示:
接着,启动hadoop,步骤如下:
① start-all.sh #启动hadoop
② jps #查看hadoop是否启动成功
如下图所示:

最后,我们把本地的文件上传至HDFS中,步骤如下:
① hdfs dfs -mkdir -p /bigdatacase/dataset #在hdfs上新建/bigdatacase/dataset
② hdfs dfs -ls /
③ hdfs dfs -put ./lagoupy.csv /bigdatacase/dataset #把本地文件small_test.csv上传至hdfs中
④ hdfs dfs -ls /bigdatacase/dataset #查看
⑤ hdfs dfs -cat /bigdatacase/dataset/small_test.csv | head -5 #查看hdfs中small_test.csv的前五行
如下图所示:

把hdfs中的文本文件最终导入到数据仓库Hive中
首先,启动hive,步骤如下:
① service mysql start #启动mysql数据库
② cd /usr/local/hive
③ ./bin/hive #启动hive
如下图所示:

① create database db; -- 创建数据库dbpy
② use db;
③ create external table labling
④ select * from labling limit 10; -- 查看lagou_py中前10行的数据
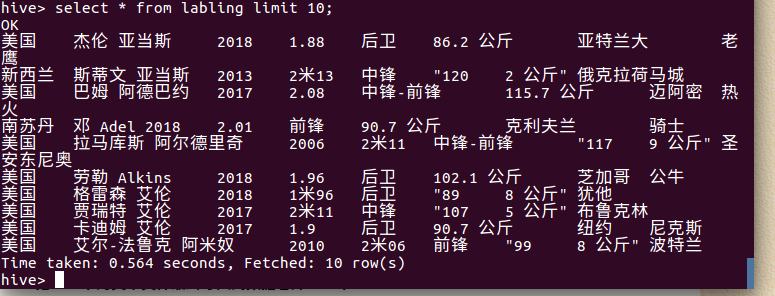
查询条数统计分析
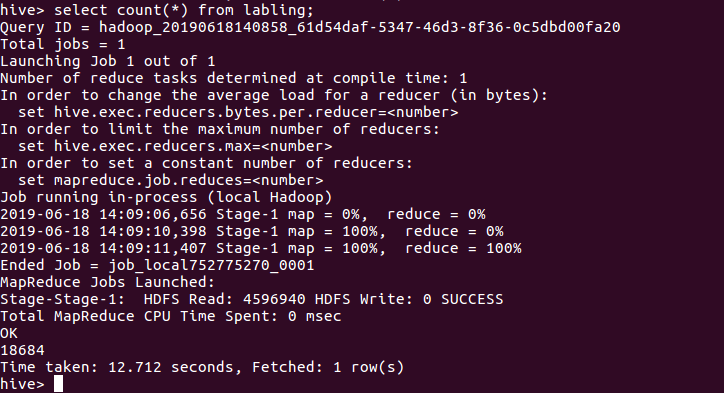
用聚合函数count()计算出表内有多少条行数据 hive> select count(*) from labling;
美国国籍的球员数:
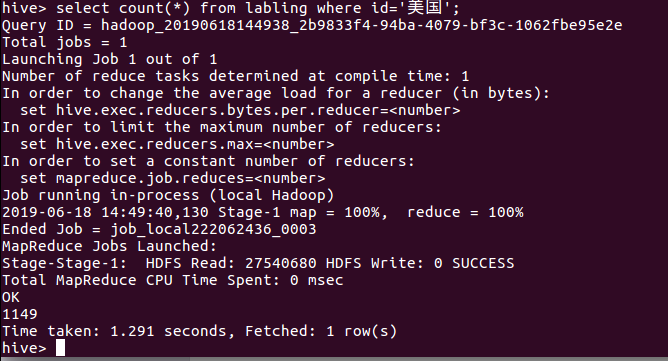
美国国籍的球员:
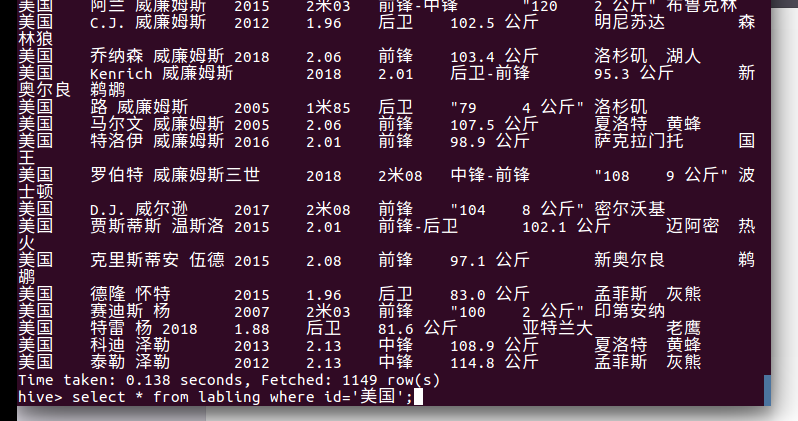
查询老鹰的球员:
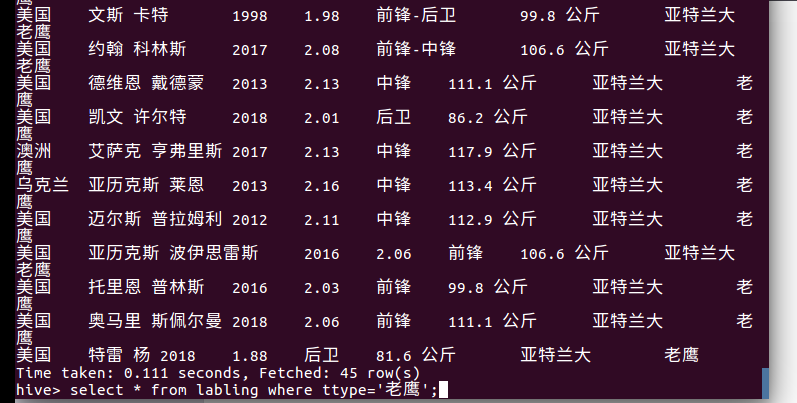
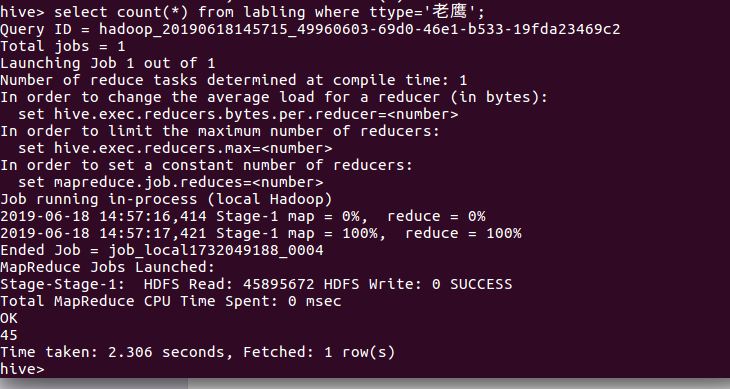
查询老鹰的球员数:
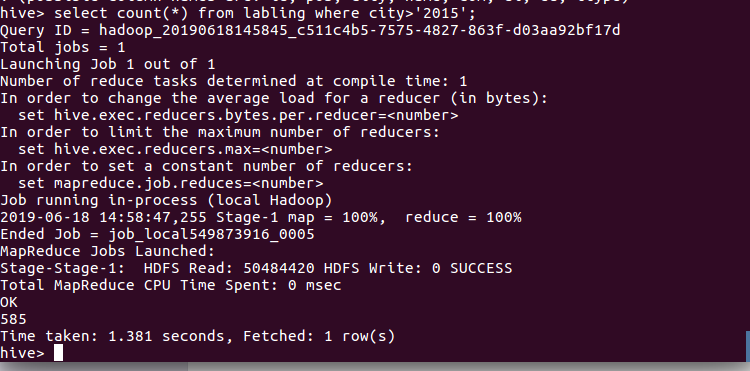
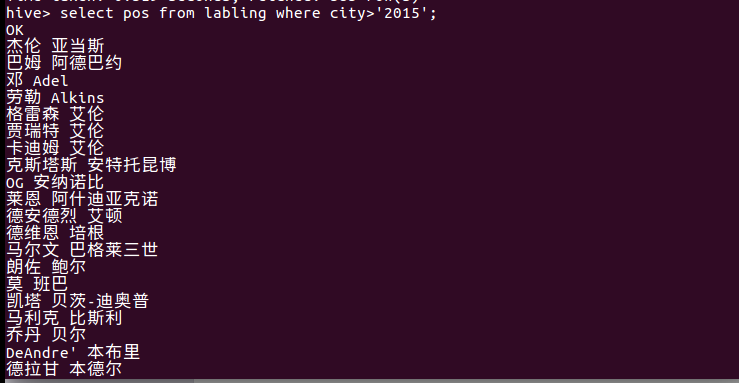
查询球员2015年以后进入NBA的人数:
查询2015年以后进入NBA球员的名字
hadoop综合的更多相关文章
- Hadoop综合大作业
Hadoop综合大作业 要求: 用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计. 用Hive对爬虫大作业产生的csv文件进行数据分析 1. 用Hive对爬虫大作业产 ...
- Hadoop 综合揭秘——HBase的原理与应用
前言 现今互联网科技发展日新月异,大数据.云计算.人工智能等技术已经成为前瞻性产品,海量数据和超高并发让传统的 Web2.0 网站有点力不从心,暴露了很多难以克服的问题.为此,Google.Amazo ...
- Hadoop 综合揭秘——MapReduce 基础编程(介绍 Combine、Partitioner、WritableComparable、WritableComparator 使用方式)
前言 本文主要介绍 MapReduce 的原理及开发,讲解如何利用 Combine.Partitioner.WritableComparator等组件对数据进行排序筛选聚合分组的功能.由于文章是针对开 ...
- 大数据应用期末总评——Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 Hadoop综合大作业 要求: 1.将爬虫大作业产生的csv文件 ...
- 【大数据应用期末总评】Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 一.Hadoop综合大作业 要求: 1.将爬虫大作业产生的csv ...
- 《Hadoop综合大作业》
作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 我主要的爬取内容是关于热门微博文章“996”与日剧<我要 ...
- 菜鸟学IT之Hadoop综合大作业
Hadoop综合大作业 作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 1.将爬虫大作业产生的csv文件上传到HDF ...
- 大数据应用期末总评Hadoop综合大作业
作业要求来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 1.将爬虫大作业产生的csv文件上传到HDFS 此次作业选取的 ...
- Hadoop综合大作业1
本次作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 一.课程评分标准: 分数组成: 考勤 10 平时作业 30 爬 ...
- 【大数据应用技术】作业十二|Hadoop综合大作业
本次作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 前言 本次作业是在<爬虫大作业>的基础上进行的 ...
随机推荐
- MySQL数据库之互联网常用分库分表方案
一.数据库瓶颈 不管是IO瓶颈,还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载活跃连接数的阈值.在业务Service来看就是,可用数据库连接少甚至无连接可用.接下来就 ...
- js数组【续】(相关方法)
一.数组的栈,队列方法[调用这些方法原数组会发生改变]var arr = [2,3,4,5,6];1.栈 LIFO (Last-In-First-Out)a.push() 可接受任意类型的参数,将它们 ...
- Oracle数据库之操作符及函数
一.操作符: 1.分类: 算术.比较.逻辑.集合.连接: 2.算术操作符: 执行数值计算: -- 工资加1000 from emp; 3.比较操作符: -- 比较运算符(between and包头不包 ...
- day 07 预科
目录 异常处理 字符串内置方法 1.索引取值 2.切片 3.成员运算 4.for循环 5.len() 6.strip(): 默认去掉两端空格 7.lsteip()/rstrip(): 去左端/右端 空 ...
- 【Flask】 python学习第一章 - 5.0 模板
jinjia2 模板 python实现 flask 内置语言 参照Djago实现 设置模板文件夹 设置模板语言 jinja2 demo6_template.html ----> 从代码渲染 ...
- 数据库开发-Django ORM的单表查询
数据库开发-Django ORM的单表查询 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.查询集 1>.查询集相关概述 查询会返回结果的集,它是django.db.mod ...
- pdsh工具的使用
pdsh的全称是parallel distributed shell,与pssh类似,pdsh可并行执行对远程目标主机的操作,在有批量执行命令或分发任务的运维需求时,使用这个命令可达到事半功倍的效果. ...
- python coding style guide 的快速落地实践——业内python 编码风格就pep8和谷歌可以认作标准
python coding style guide 的快速落地实践 机器和人各有所长,如coding style检查这种可自动化的工作理应交给机器去完成,故发此文帮助你在几分钟内实现coding st ...
- java技术思维导图(转载)
在网上看到有个人总结的java技术的东东,觉得很好,就保存下来了,码农还真是累啊,只有不断的学习才能有所提高,才能拿更多的RMB啊. java技术思维导图 服务端思维导图 前端思维导图
- pageContext 和 config 内置对象
forword("目标页面") : 使当前页面跳转到另一个目标页面 include("目标页面") ;使当前页面包含另一个页面的信息