Stanford coursera Andrew Ng 机器学习课程第四周总结(附Exercise 3)
Introduction
Neural NetWork的由来
先考虑一个非线性分类,当特征数很少时,逻辑回归就可以完成了,但是当特征数变大时,高阶项将呈指数性增长,复杂度可想而知。如下图:对房屋进行高低档的分类,当特征值只有x1,x2,x3时,我们可以对它进行处理,分类。但是当特征数增长为x1,x2....x100时,分类器的效率就会很低了。
Neural NetWork模型
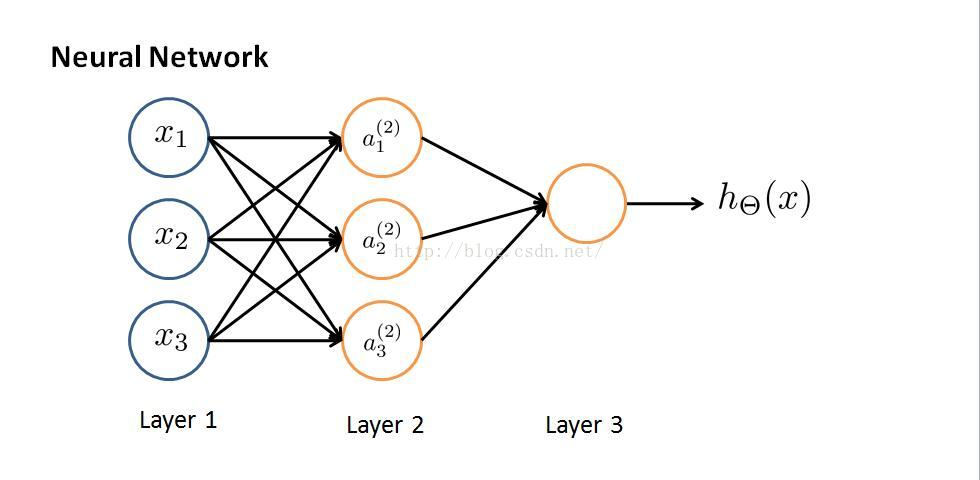
该图是最简单的神经网络,共有3层,输入层Layer1;隐藏层Layer2;输出层Layer3,每层都有多个激励函数ai(j).通过层与层之间的传递参数Θ得到最终的假设函数hΘ(x)。我们的目的是通过大量的输入样本x(作为第一层),训练层与层之间的传递参数(经常称为权重),使得假设函数尽可能的与实际输出值接近h(x)≈y(代价函数J尽可能的小)。
逻辑回归模型
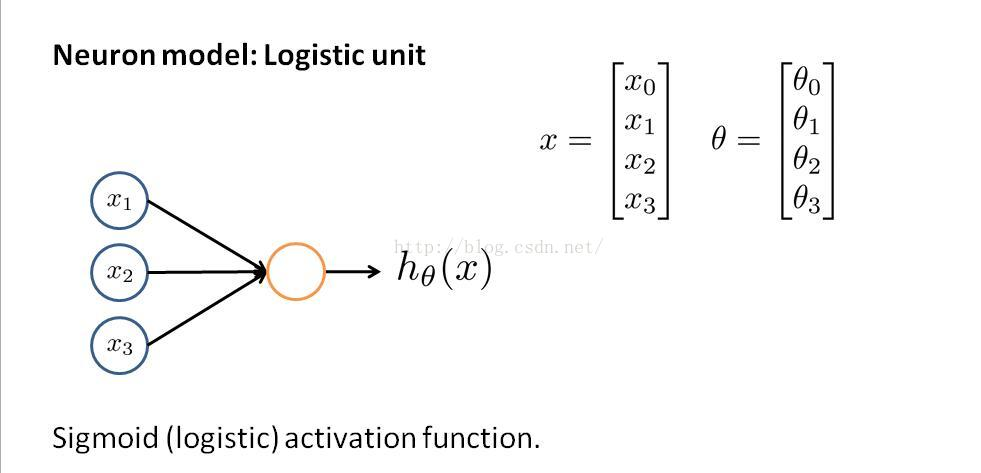
很容易看出,逻辑回归是没有隐藏层的神经网络,层与层之间的传递函数就是θ。
Neural NetWork
神经网络模型---正向传播
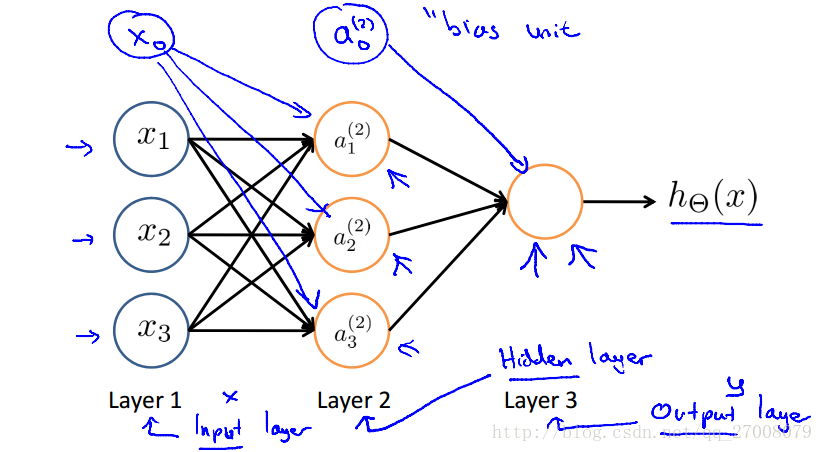
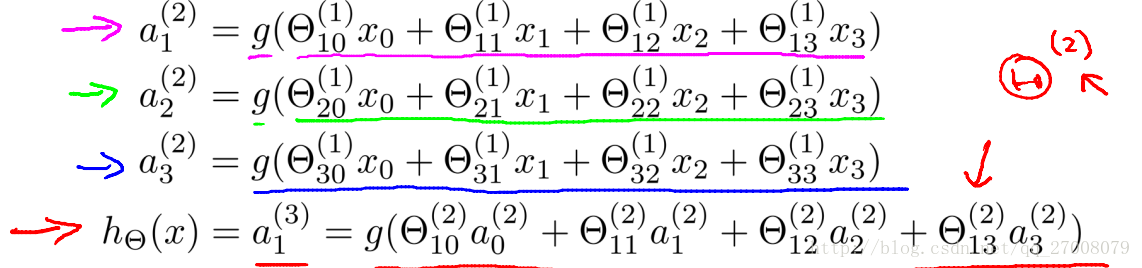
Cost function(代价函数)
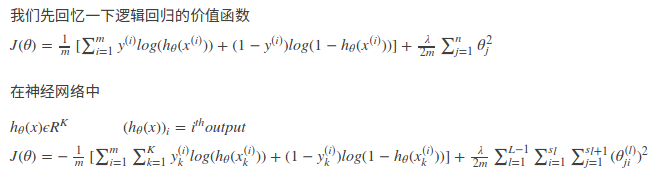
Examples and intuitions


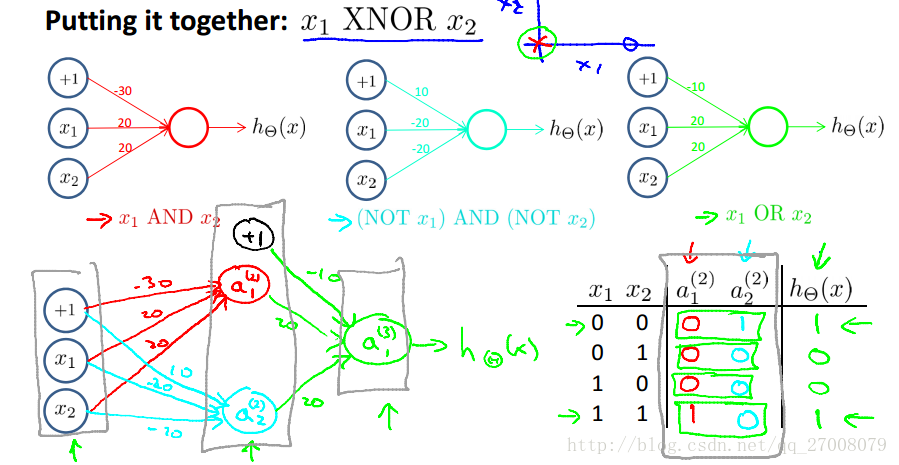
Multi-class classification
对于多分类问题,我们可以通过设置多个输出值来实现。
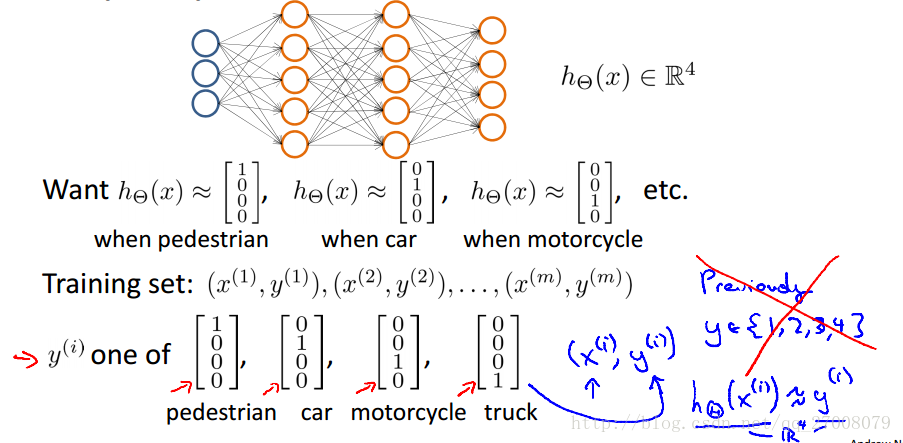
编程作业就是一个多分类问题——手写数字识别
输入的是手写的照片(数字0-9),5000组样本、每个像素点用20×20的点阵表示成一行,输入向量为5000×400的矩阵X,经过神经网络传递后,输出一个假设函数(列向量),取最大值所在的行号即为假设值(0-9中的一个)。也就是输出值y = 1,2,3,4,5.....10又有可能,为了方便数值运算,我们用10×1的列向量表示,譬如 y = 5,有

Exercises
这次的作业是用逻辑回归和神经网络来实现手写数字识别,比较下两者的准确性。
Logistic Regression
lrCostFunction.m
function [J, grad] = lrCostFunction(theta, X, y, lambda)
%LRCOSTFUNCTION Compute cost and gradient for logistic regression with
%regularization
% J = LRCOSTFUNCTION(theta, X, y, lambda) computes the cost of using
% theta as the parameter for regularized logistic regression and the
% gradient of the cost w.r.t. to the parameters. % Initialize some useful values
m = length(y); % number of training examples % You need to return the following variables correctly
J = 0;
grad = zeros(size(theta)); % ====================== YOUR CODE HERE ======================
% Instructions: Compute the cost of a particular choice of theta.
% You should set J to the cost.
% Compute the partial derivatives and set grad to the partial
% derivatives of the cost w.r.t. each parameter in theta
%
% Hint: The computation of the cost function and gradients can be
% efficiently vectorized. For example, consider the computation
%
% sigmoid(X * theta)
%
% Each row of the resulting matrix will contain the value of the
% prediction for that example. You can make use of this to vectorize
% the cost function and gradient computations.
%
% Hint: When computing the gradient of the regularized cost function,
% there're many possible vectorized solutions, but one solution
% looks like:
% grad = (unregularized gradient for logistic regression)
% temp = theta;
% temp(1) = 0; % because we don't add anything for j = 0
% grad = grad + YOUR_CODE_HERE (using the temp variable)
%
theta_reg=[0;theta(2:size(theta))]; J = (-y'*log(sigmoid(X*theta))-(1-y)'*log(1-sigmoid(X*theta)))/m + lambda/(2*m)*(theta_reg')*theta_reg; grad = X'*(sigmoid(X*theta)-y)/m + lambda/m*theta_reg; % ============================================================= grad = grad(:); end
oneVsAll.m
function [all_theta] = oneVsAll(X, y, num_labels, lambda)
%ONEVSALL trains multiple logistic regression classifiers and returns all
%the classifiers in a matrix all_theta, where the i-th row of all_theta
%corresponds to the classifier for label i
% [all_theta] = ONEVSALL(X, y, num_labels, lambda) trains num_labels
% logistic regression classifiers and returns each of these classifiers
% in a matrix all_theta, where the i-th row of all_theta corresponds
% to the classifier for label i % Some useful variables
m = size(X, 1);
n = size(X, 2); % You need to return the following variables correctly
all_theta = zeros(num_labels, n + 1); % Add ones to the X data matrix
X = [ones(m, 1) X]; % ====================== YOUR CODE HERE ======================
% Instructions: You should complete the following code to train num_labels
% logistic regression classifiers with regularization
% parameter lambda.
%
% Hint: theta(:) will return a column vector.
%
% Hint: You can use y == c to obtain a vector of 1's and 0's that tell you
% whether the ground truth is true/false for this class.
%
% Note: For this assignment, we recommend using fmincg to optimize the cost
% function. It is okay to use a for-loop (for c = 1:num_labels) to
% loop over the different classes.
%
% fmincg works similarly to fminunc, but is more efficient when we
% are dealing with large number of parameters.
%
% Example Code for fmincg:
%
% % Set Initial theta
% initial_theta = zeros(n + 1, 1);
%
% % Set options for fminunc
% options = optimset('GradObj', 'on', 'MaxIter', 50);
%
% % Run fmincg to obtain the optimal theta
% % This function will return theta and the cost
% [theta] = ...
% fmincg (@(t)(lrCostFunction(t, X, (y == c), lambda)), ...
% initial_theta, options);
% initial_theta = zeros(n + 1, 1); options = optimset('GradObj', 'on', 'MaxIter', 50); for c = 1:num_labels
all_theta(c,:) = fmincg (@(t)(lrCostFunction(t, X, (y == c), lambda)), initial_theta, options);
end % ========================================================================= end
predictOneVsAll.m
function p = predictOneVsAll(all_theta, X)
%PREDICT Predict the label for a trained one-vs-all classifier. The labels
%are in the range 1..K, where K = size(all_theta, 1).
% p = PREDICTONEVSALL(all_theta, X) will return a vector of predictions
% for each example in the matrix X. Note that X contains the examples in
% rows. all_theta is a matrix where the i-th row is a trained logistic
% regression theta vector for the i-th class. You should set p to a vector
% of values from 1..K (e.g., p = [1; 3; 1; 2] predicts classes 1, 3, 1, 2
% for 4 examples) m = size(X, 1);
num_labels = size(all_theta, 1); % You need to return the following variables correctly
p = zeros(size(X, 1), 1); % Add ones to the X data matrix
X = [ones(m, 1) X]; % ====================== YOUR CODE HERE ======================
% Instructions: Complete the following code to make predictions using
% your learned logistic regression parameters (one-vs-all).
% You should set p to a vector of predictions (from 1 to
% num_labels).
%
% Hint: This code can be done all vectorized using the max function.
% In particular, the max function can also return the index of the
% max element, for more information see 'help max'. If your examples
% are in rows, then, you can use max(A, [], 2) to obtain the max
% for each row.
% [maxx, p]=max(X*all_theta',[],2); % ========================================================================= end
Training Set Accuracy: 95.100000
下面是以三层bp神经网络处理的手写数字识别,其中权重矩阵已给出。
predict.m
function p = predict(Theta1, Theta2, X)
%PREDICT Predict the label of an input given a trained neural network
% p = PREDICT(Theta1, Theta2, X) outputs the predicted label of X given the
% trained weights of a neural network (Theta1, Theta2) % Useful values
m = size(X, 1);
num_labels = size(Theta2, 1); % You need to return the following variables correctly
p = zeros(size(X, 1), 1); % ====================== YOUR CODE HERE ======================
% Instructions: Complete the following code to make predictions using
% your learned neural network. You should set p to a
% vector containing labels between 1 to num_labels.
%
% Hint: The max function might come in useful. In particular, the max
% function can also return the index of the max element, for more
% information see 'help max'. If your examples are in rows, then, you
% can use max(A, [], 2) to obtain the max for each row.
%
X = [ones(m, 1) X]; temp=sigmoid(X*Theta1'); temp = [ones(m, 1) temp]; temp2=sigmoid(temp*Theta2'); [maxx, p]=max(temp2, [], 2); % ========================================================================= end
Training Set Accuracy: 97.520000
注意事项
1.X = [ones(m, 1) X];是确保矩阵维度一致。X0就是一行1
2.正则化时theta0要用0替代,处理如theta_reg=[0;theta(2:size(theta))];
Stanford coursera Andrew Ng 机器学习课程第四周总结(附Exercise 3)的更多相关文章
- Stanford coursera Andrew Ng 机器学习课程编程作业(Exercise 2)及总结
Exercise 1:Linear Regression---实现一个线性回归 关于如何实现一个线性回归,请参考:http://www.cnblogs.com/hapjin/p/6079012.htm ...
- Stanford coursera Andrew Ng 机器学习课程第二周总结(附Exercise 1)
Exercise 1:Linear Regression---实现一个线性回归 重要公式 1.h(θ)函数 2.J(θ)函数 思考一下,在matlab里面怎么表达?如下: 原理如下:(如果你懂了这道作 ...
- Stanford coursera Andrew Ng 机器学习课程编程作业(Exercise 1)
Exercise 1:Linear Regression---实现一个线性回归 在本次练习中,需要实现一个单变量的线性回归.假设有一组历史数据<城市人口,开店利润>,现需要预测在哪个城市中 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 15—Anomaly Detection异常检测
Lecture 15 Anomaly Detection 异常检测 15.1 异常检测问题的动机 Problem Motivation 异常检测(Anomaly detection)问题是机器学习算法 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 1_Introduction and Basic Concepts 介绍和基本概念
目录 1.1 欢迎1.2 机器学习是什么 1.2.1 机器学习定义 1.2.2 机器学习算法 - Supervised learning 监督学习 - Unsupervised learning 无 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 17—Large Scale Machine Learning 大规模机器学习
Lecture17 Large Scale Machine Learning大规模机器学习 17.1 大型数据集的学习 Learning With Large Datasets 如果有一个低方差的模型 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 16—Recommender Systems 推荐系统
Lecture 16 Recommender Systems 推荐系统 16.1 问题形式化 Problem Formulation 在机器学习领域,对于一些问题存在一些算法, 能试图自动地替你学习到 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 14—Dimensionality Reduction 降维
Lecture 14 Dimensionality Reduction 降维 14.1 降维的动机一:数据压缩 Data Compression 现在讨论第二种无监督学习问题:降维. 降维的一个作用是 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 12—Support Vector Machines 支持向量机
Lecture 12 支持向量机 Support Vector Machines 12.1 优化目标 Optimization Objective 支持向量机(Support Vector Machi ...
随机推荐
- JS获取地址栏并拼接參数
比方地址栏是这种:http://www.aa.com/detail.aspx?code=1&start=2014-12-01&end=2014-12-23&name=abc 要 ...
- [Java] 实验5參考代码
实验4月3日晚截止,实验截止后将在此给出完整的參考代码. 1. 怎样使用以下的代码模板: 1.1 在eclipse中创建相应名称的类 1.2 将代码拷贝到类文件中 1.3 在//todo凝视中 ...
- Cracking the Coding Interview 150题(一)
1.数组与字符串 1.1 实现一个算法,确定一个字符串的所有字符是否全都不同.假设不允许使用额外的数据结构,又该如何处理? 1.2 用C或C++实现void reverse(char* str)函数, ...
- vue之父子组件之间的通信方式
(一)props与$emit <!-这部分是一个关于父子组件之间参数传递的例子--> <!--父组件传递参数到子组件是props,子组件传递参数到父组件是用事件触发$emit--&g ...
- javascript闭包具体解释
今天我们从内存结构上来解说下 javascript中的闭包概念. 闭包:是指有权訪问另外一个函数作用域中的变量的函数. 创建闭包的常见方式就是在一个函数内部创建另外一个函数. 在javascript中 ...
- 【OI】Kruskal & ufs (克鲁斯卡与并查集)
Kruskal是有关于最小生成树的算法. 这个算法非常好理解,用一句话来概括就是: 从小到大找不同集合的边. 那么,具体是怎样的呢. 1.先把所有顶点初始化为一个连通分量. 2.从所有边中选择最小的( ...
- YTU 2641: 填空题:静态成员---计算学生个数
2641: 填空题:静态成员---计算学生个数 时间限制: 1 Sec 内存限制: 128 MB 提交: 267 解决: 206 题目描述 学生类声明已经给出,在主程序中根据输入信息输出实际建立的 ...
- luogu 3952 时间复杂度
noip2017 D1T2 时间复杂度 某zz选手考场上写了1.5h 考完之后发现自己写的是错的 但是结果A了??? 题目大意: 一种新的编程语言 A++ 给出一个程序只有循环语句 并给出这个程序的时 ...
- python 视频逐帧保存为图片
import cv2 import os def save_img(): video_path = r'F:\test\video1/' videos = os.listdir(video_path) ...
- VS快捷键整理
Ctrl+J 自动提示Ctrl+. 解析ctrl+e,d 格式化代码ctrl+e,s 辅助横线Ctrl+m,o 全部合闭Ctrl+m,l 全部打开Ctrl + Shift + space 方法提示调用 ...