十三 web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址
有多网站,当你浏览器访问时看到的信息,在html源文件里却找不到,由得信息还是滚动条滚动到对应的位置后才显示信息,那么这种一般都是 js 的 Ajax 动态请求生成的信息
我们以百度新闻为列:
1、分析网站
首先我们浏览器打开百度新闻,在网页中间部分找一条新闻信息

然后查看源码,看看在源码里是否有这条新闻,可以看到源文件里没有这条信息,这种情况爬虫是无法爬取到信息的
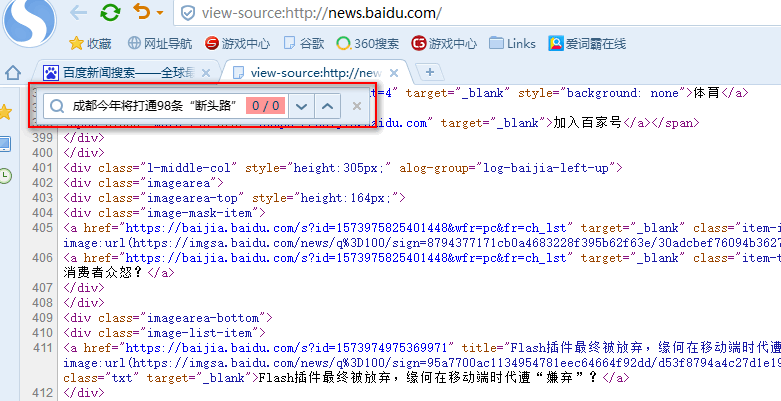
那么我们就需要抓包分析了,启动抓包软件和抓包浏览器,前后有说过软件了,就不在说了,此时我们经过抓包看到这条信息是通过Ajax动态生成的JSON数据,也就是说,当html页面加载完成后才生成的,所有我们在源文件里无法找到,当然爬虫也找不到
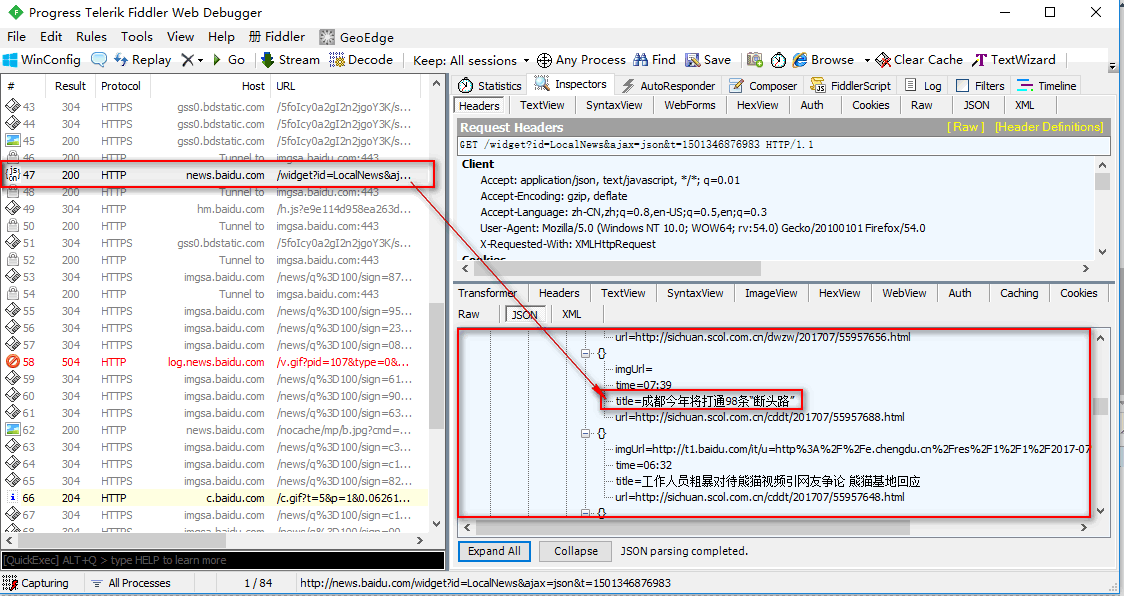
我们首先将这个JSON数据网址拿出来,到浏览器看看,我们需要的数据是不是全部在里面,此时我们看到这次请求里只有 17条信息,显然我们需要的信息不是完全在里面,还得继续看看其他js包
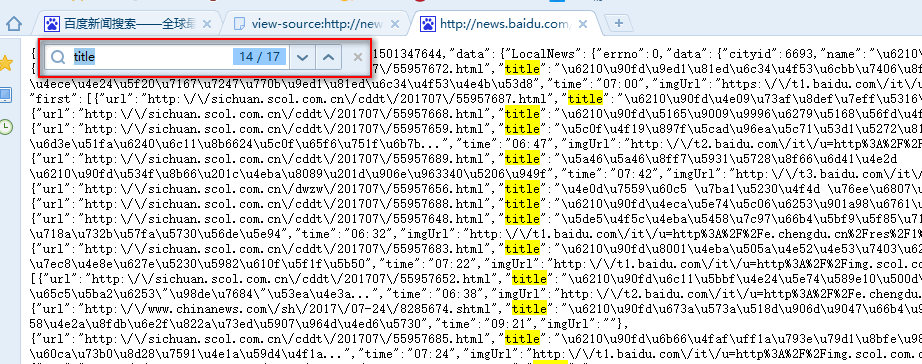
我们将抓包浏览器滚动条拉到底,以便触发所有js请求,然后在继续找js包,我们将所有js包都找完了再也没看到新闻信息的包了
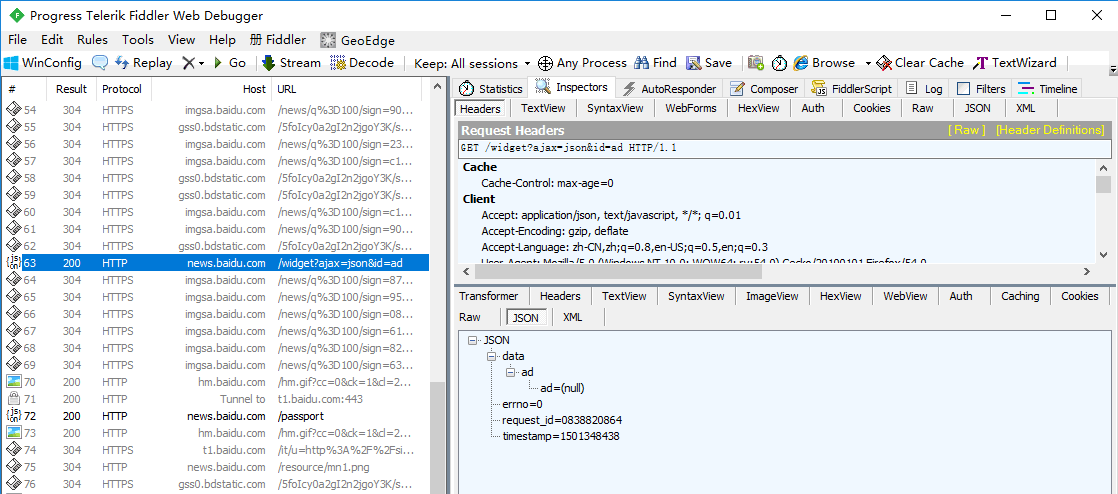
那信息就不在js包里了,我们回头在看看其他类型的请求,此时我们看到很多get请求响应的是我们需要的新闻信息,说明只有第一次那个Ajax请求返回的JSON数据,后面的Ajax请求返回的都是html类型的字符串数据,
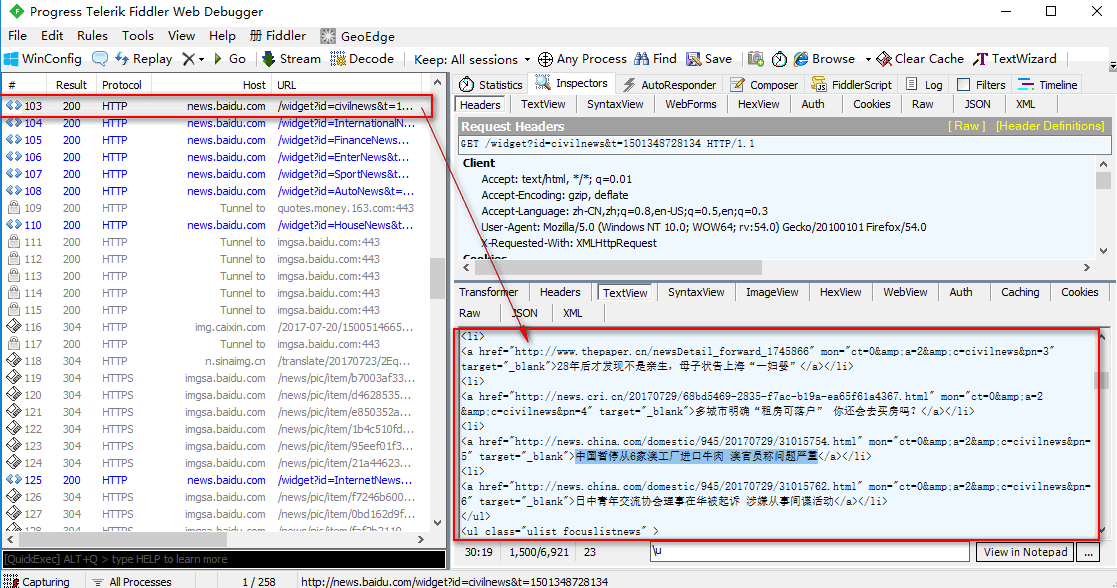
我们将Ajax请求返回的JSON数据的网址和Ajax请求返回html类型的字符串数据网址,拿来做一下比较看看是否能找到一定规律,
此时我们可以看到,JSON数据的网址和html类型的字符串数据网址是一个请求地址,
只是请求时传递的参数不一样而已,那么说明无论返回的什么类型的数据,都是在一个请求地址处理的,只是根据不同的传参返回不同类型的数据而已
http://news.baidu.com/widget?id=LocalNews&ajax=json&t=1501348444467 JSON数据的网址 http://news.baidu.com/widget?id=civilnews&t=1501348728134 html类型的字符串数据网址 http://news.baidu.com/widget?id=InternationalNews&t=1501348728196 html类型的字符串数据网址
我们可以将html类型的字符串数据网址加上JSON数据的网址参数,那是否会返回JSON数据类型?试一试,果然成功了
http://news.baidu.com/widget?id=civilnews&ajax=json 将html类型的字符串数据网址加上JSON数据的网址参数 http://news.baidu.com/widget?id=InternationalNews&ajax=json 将html类型的字符串数据网址加上JSON数据的网址参数
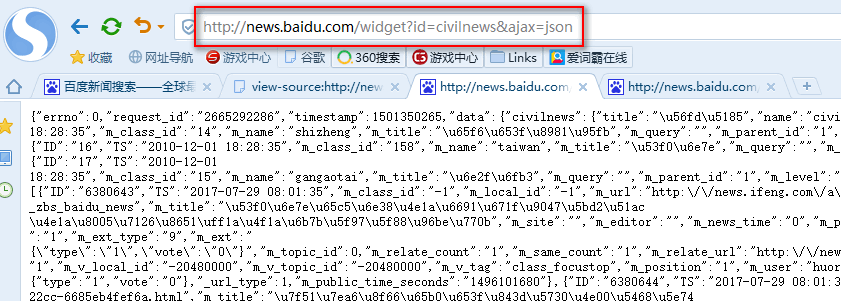
这下就好办了,找到所有的html类型的字符串数据网址,按照上面的方法将其转换成JSON数据的网址,然后循环的去访问转换后的JSON数据的网址,就可以拿到所有新闻的url地址了
crapy实现

# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request,FormRequest
import re
import json
from adc.items import AdcItem
from scrapy.selector import Selector class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider
name = 'pach' #设置爬虫名称
allowed_domains = ['news.baidu.com'] #爬取域名
start_urls = ['http://news.baidu.com/widget?id=civilnews&ajax=json'] qishiurl = [ #的到所有页面id
'InternationalNews',
'FinanceNews',
'EnterNews',
'SportNews',
'AutoNews',
'HouseNews',
'InternetNews',
'InternetPlusNews',
'TechNews',
'EduNews',
'GameNews',
'DiscoveryNews',
'HealthNews',
'LadyNews',
'SocialNews',
'MilitaryNews',
'PicWall'
] urllieb = []
for i in range(0,len(qishiurl)): #构造出所有idURL
kaishi_url = 'http://news.baidu.com/widget?id=' + qishiurl[i] + '&ajax=json'
urllieb.append(kaishi_url)
# print(urllieb) def parse(self, response): #选项所有连接
for j in range(0, len(self.urllieb)):
a = '正在处理第%s个栏目:url地址是:%s' % (j, self.urllieb[j])
yield scrapy.Request(url=self.urllieb[j], callback=self.enxt) #每次循环到的url 添加爬虫 def enxt(self, response):
neir = response.body.decode("utf-8")
pat2 = '"m_url":"(.*?)"'
url = re.compile(pat2, re.S).findall(neir) #通过正则获取爬取页面 的URL
for k in range(0,len(url)):
zf_url = url[k]
url_zf = re.sub("\\\/", "/", zf_url)
pduan = url_zf.find('http://')
if pduan == 0:
print(url_zf) #输出获取到的所有url
十三 web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息的更多相关文章
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码 打码接口文件 # -*- coding: cp936 -*- import sys import os ...
- 第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录 模拟浏览器登录 start_requests()方法,可以返回一个请求给爬虫的起始网站,这个返回的请求相当于star ...
- 第三百三十二节,web爬虫讲解2—Scrapy框架爬虫—Scrapy使用
第三百三十二节,web爬虫讲解2—Scrapy框架爬虫—Scrapy使用 xpath表达式 //x 表示向下查找n层指定标签,如://div 表示查找所有div标签 /x 表示向下查找一层指定的标签 ...
- 第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令 Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --u ...
- 十 web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --upgrade pip2.安装,wheel(建议网络安装) pip install wheel ...
- python爬虫随笔-scrapy框架(1)——scrapy框架的安装和结构介绍
scrapy框架简介 Scrapy,Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 ...
- Scrapy框架-----爬虫
说明:文章是本人读了崔庆才的Python3---网络爬虫开发实战,做的简单整理,希望能帮助正在学习的小伙伴~~ 1. 准备工作: 安装Scrapy框架.MongoDB和PyMongo库,如果没有安装, ...
- 第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解 封装模块 #!/usr/bin/env python # -*- coding: utf- ...
随机推荐
- flask扩展 -- flask-script
Flask-Scropt插件:为在Flask里编写额外的脚本提供了支持.这包括运行一个开发服务器,一个定制的Python命令行,用于执行初始化数据库.定时任务和其他属于web应用之外的命令行任务的脚本 ...
- WebUploader 上传插件结合bootstrap的模态框使用时选择上传文件按钮无效问题的解决方法
由于种种原因(工作忙,要锻炼健身,要看书,要学习其他兴趣爱好,谈恋爱等),博客已经好久没有更新,为这个内心一直感觉很愧疚,今天开始决定继续更新博客,每周至少一篇,最多不限篇幅. 今天说一下,下午在工作 ...
- obj比较
<script> var obj1={name:'one',age:30}; var obj2={name:'one',age:30}; //比较两个字符串对象的[值]是否相等 Objec ...
- 10 Linux Commands Every Developer Should Know
转载:http://azer.bike/journal/10-linux-commands-every-developer-should-know/ As a software engineer, l ...
- spark[源码]-Pool分析
概述 这篇文章主要是分析一下Pool这个任务调度的队列.整体代码量也不是很大,正好可以详细的分析一下,前面在TaskSchedulerImpl提到大体的功能,这个点在丰富一下吧. DAGSchedul ...
- Java GC 标记/清除算法
1) 标记/清除算法是怎么来的? 我们在程序运行期间如果想进行垃圾回收,就必须让GC线程与程序当中的线程互相配合,才能在不影响程序运行的前提下,顺利的将垃圾进行回收. 为了达到这个目的,标记/清除算法 ...
- 粗略介绍Java AQS的实现原理
本文转自 http://www.importnew.com/24006.html 感谢作者 对我很有帮助 ①引言 AQS是JDK1.5提供的一个基于FIFO等待队列一个同步器的基础框架,java中的同 ...
- 数据库中的B树和B+树
B树与B+树 数据库中建立索引能加快数据的存取,但是当索引变得很大时,可能导致内存装不下.这时就需要使用多级索引来实现.而B树和B+树是实现多级索引的一种数据结构. B树 B树是多叉树,其树中每个节点 ...
- 带你走进AJAX(1)
ajax是什么? (1)ajax (asynchronouse javascript and xml) 异步的javascript 和xml (2)ajax是一个粘合剂,将javascript.xml ...
- SpringBoot Web项目中中如何使用Junit
Junit这种老技术,现在又拿出来说,不为别的,某种程度上来说,更是为了要说明它在项目中的重要性. 凭本人的感觉和经验来说,在项目中完全按标准都写Junit用例覆盖大部分业务代码的,应该不会超过一半. ...