第三百三十二节,web爬虫讲解2—Scrapy框架爬虫—Scrapy使用
第三百三十二节,web爬虫讲解2—Scrapy框架爬虫—Scrapy使用
xpath表达式
//x 表示向下查找n层指定标签,如://div 表示查找所有div标签
/x 表示向下查找一层指定的标签
/@x 表示查找指定属性的值,可以连缀如:@id @src
[@属性名称="属性值"]表示查找指定属性等于指定值的标签,可以连缀 ,如查找class名称等于指定名称的标签
/text() 获取标签文本类容
[x] 通过索引获取集合里的指定一个元素
1、将xpath表达式过滤出来的结果进行正则匹配,用正则取最终内容
最后.re('正则')
xpath('//div[@class="showlist"]/li//img')[0].re('alt="(\w+)')
2、在选择器规则里应用正则进行过滤
[re:正则规则]
xpath('//div[re:test(@class, "showlist")]').extract()
实战使用Scrapy获取一个电商网站的、商品标题、商品链接、和评论数

分析源码
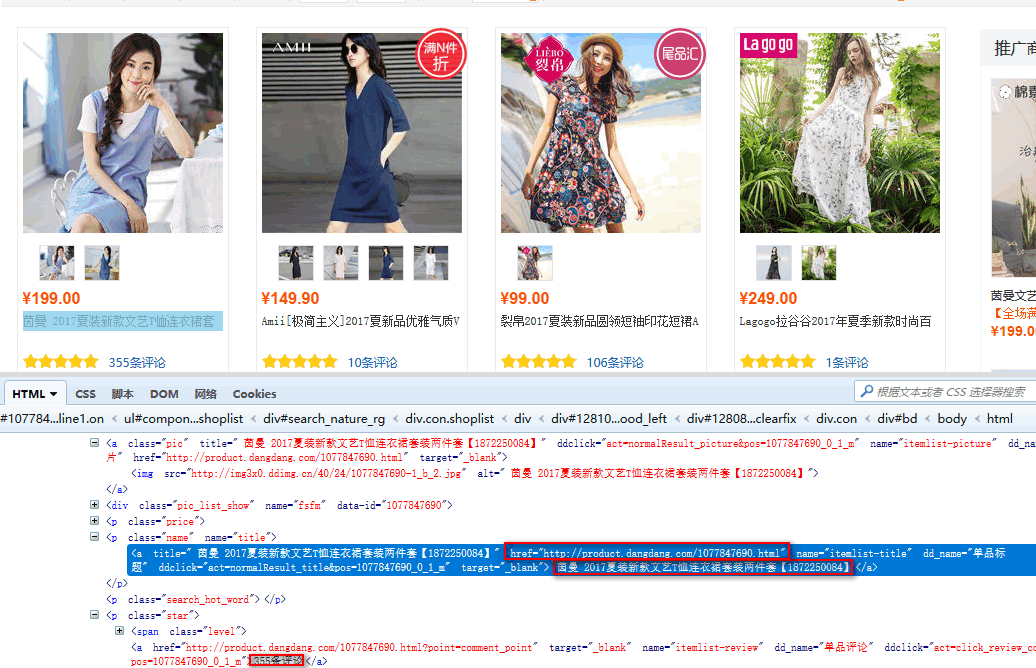
第一步、编写items.py容器文件
我们已经知道了我们要获取的是、商品标题、商品链接、和评论数
在items.py创建容器接收爬虫获取到的数据
设置爬虫获取到的信息容器类,必须继承scrapy.Item类
scrapy.Field()方法,定义变量用scrapy.Field()方法接收爬虫指定字段的信息
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy #items.py,文件是专门用于,接收爬虫获取到的数据信息的,就相当于是容器文件 class AdcItem(scrapy.Item): #设置爬虫获取到的信息容器类
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() #接收爬虫获取到的title信息
link = scrapy.Field() #接收爬虫获取到的连接信息
comment = scrapy.Field() #接收爬虫获取到的商品评论数
第二步、编写pach.py爬虫文件
定义爬虫类,必须继承scrapy.Spider
name设置爬虫名称
allowed_domains设置爬取域名
start_urls设置爬取网址
parse(response)爬虫回调函数,接收response,response里是获取到的html数据对象
xpath()过滤器,参数是xpath表达式
extract()获取html数据对象里的数据
yield item 接收了数据的容器对象,返回给pipelies.py
# -*- coding: utf-8 -*-
import scrapy
from adc.items import AdcItem #导入items.py里的AdcItem类,容器类 class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider
name = 'pach' #设置爬虫名称
allowed_domains = ['search.dangdang.com'] #爬取域名
start_urls = ['http://category.dangdang.com/pg1-cid4008149.html'] #爬取网址 def parse(self, response): #parse回调函数
item = AdcItem() #实例化容器对象
item['title'] = response.xpath('//p[@class="name"]/a/text()').extract() #表达式过滤获取到数据赋值给,容器类里的title变量
# print(rqi['title'])
item['link'] = response.xpath('//p[@class="name"]/a/@href').extract() #表达式过滤获取到数据赋值给,容器类里的link变量
# print(rqi['link'])
item['comment'] = response.xpath('//p[@class="star"]//a/text()').extract() #表达式过滤获取到数据赋值给,容器类里的comment变量
# print(rqi['comment'])
yield item #接收了数据的容器对象,返回给pipelies.py
robots协议
注意:如果获取的网站在robots.txt文件里设置了,禁止爬虫爬取协议,那么将无法爬取,因为scrapy默认是遵守这个robots这个国际协议的,如果想不遵守这个协议,需要在settings.py设置
到settings.py文件里找到ROBOTSTXT_OBEY变量,这个变量等于False不遵守robots协议,等于True遵守robots协议
# Obey robots.txt rules
ROBOTSTXT_OBEY = False #不遵循robots协议
第三步、编写pipelines.py数据处理文件
如果需要pipelines.py里的数据处理类能工作,需在settings.py设置文件里的ITEM_PIPELINES变量里注册数据处理类
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'adc.pipelines.AdcPipeline': 300, #注册adc.pipelines.AdcPipeline类,后面一个数字参数表示执行等级,数值越大越先执行
}
注册后pipelines.py里的数据处理类就能工作
定义数据处理类,必须继承object
process_item(item)为数据处理函数,接收一个item,item里就是爬虫最后yield item 来的数据对象
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html class AdcPipeline(object): #定义数据处理类,必须继承object
def process_item(self, item, spider): #process_item(item)为数据处理函数,接收一个item,item里就是爬虫最后yield item 来的数据对象
for i in range(0,len(item['title'])): #可以通过item['容器名称']来获取对应的数据列表
title = item['title'][i]
print(title)
link = item['link'][i]
print(link)
comment = item['comment'][i]
print(comment)
return item
最后执行
执行爬虫文件,scrapy crawl pach --nolog

可以看到我们需要的数据已经拿到了
第三百三十二节,web爬虫讲解2—Scrapy框架爬虫—Scrapy使用的更多相关文章
- 第三百三十七节,web爬虫讲解2—PhantomJS虚拟浏览器+selenium模块操作PhantomJS
第三百三十七节,web爬虫讲解2—PhantomJS虚拟浏览器+selenium模块操作PhantomJS PhantomJS虚拟浏览器 phantomjs 是一个基于js的webkit内核无头浏览器 ...
- 第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础 在urllib中,我们一样可以使用xpath表达式进行信息提取,此时,你需要首先安装lxml模块 ...
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码 打码接口文件 # -*- coding: cp936 -*- import sys import os ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- 第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录 模拟浏览器登录 start_requests()方法,可以返回一个请求给爬虫的起始网站,这个返回的请求相当于star ...
- 第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令 Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --u ...
- 第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解 封装模块 #!/usr/bin/env python # -*- coding: utf- ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- 第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术.设置用户代理 如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执 ...
随机推荐
- 菜鸟调错(二)——EJB3.0部署消息驱动Bean抛javax.naming.NameNotFoundException异常
在部署EJB的消息驱动Bean时遇到了如下的错误: ERROR [org.jboss.resource.adapter.jms.inflow.JmsActivation] (WorkManager(2 ...
- 【小白的CFD之旅】21 网格划分软件的选择
但是怎样才能获得流体计算网格呢?“工欲善其事必先利其器”,画网格该用什么器呢?小白决定找黄师姐请教一番. 小白找到黄师姐的时候,黄师姐正在电脑上忙着. “黄师姐,我发现网格划分软件有好多种,究竟哪种才 ...
- angular学习笔记(三十)-指令(8)-scope
本篇讲解指令的scope属性: scope属性值可以有三种: 一.scope:false 默认值,这种情况下,指令的作用域就是指令元素当前所在的作用域. 二.scope:true 创建一个继承了父作用 ...
- bash shell(5):if,else,while大小比较
1.if :else 语句 .if的单分支语法格式: if 条件判断;then 语句1 语句2 …… else 语句1 语句2 …… fi .if的多分支语法格式: if 条件判断:then 语句1 ...
- ZendStudio在kali下无法启动
错误如下 # # A fatal error has been detected by the Java Runtime Environment: # # SIGSEGV (0xb) at pc=0 ...
- FFmpeg Basics学习笔记(2)
帧率 fps的概念 帧率,单位FPS(frame per second), 用于衡量视频每秒的处理帧数,对于编码器而言说明编码器在1s的编码的速度,通常可以使用一帧的编码时间倒数简单计算:对于解码器而 ...
- 基于jQuery图片弹出翻转特效代码
分享一款基于jQuery图片弹出翻转特效代码.这是一款基于jQuery+HTML5实现的,里面包含六款不同效果的鼠标点击图片弹出特效下载.效果图如下: 在线预览 源码下载 实现的代码. html代 ...
- mongo批量更新、导入导出脚本
批量更新,一定要加上最后的条件: db.getCollection('cuishou_user').update( {,,,,,]}}, //query {$set:{)}},// update {m ...
- C语言 · 生物芯片
标题:生物芯片 X博士正在研究一种生物芯片.博士在芯片中设计了 n 个微型光源,每个光源操作一次就会改变其状态,即:点亮转为关闭,或关闭转为点亮. 这些光源的编号从 1 到 n,开始的时候所有光源都是 ...
- AT91SAM9260EK-38k产生原理
9260内部有5个内部计数器,分别为TIMER_CLOCK1 --- TIMER_CLOCK5.通过这5个时钟可以为各种内部设备提供时钟基准. 其中,红外发射38K方波,是通过CLOCK1计数产生. ...