python3抓取异步百度瀑布流动态图片(二)get、json下载代码讲解
制作解析网址的get
def gethtml(url,postdata):
header = {'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:46.0) Gecko/20100101 Firefox/46.0',
'Referer':
'http://image.baidu.com',
'Host': 'image.baidu.com',
'Accept': 'text/plain, */*; q=0.01',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Connection':'keep-alive'}
# 解析网页
html_bytes = requests.get(url, headers=header,params = postdata)
return html_bytes
头部的构造请参考上一篇博文:
python3抓取异步百度瀑布流动态图片(一)查找post并伪装头方法
分析网址:
http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=gif&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=gif&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=30&rn=30&gsm=1e&1472364207674=
分解为:
url = 'http://image.baidu.com/search/acjson?' + postdata + lasturl
lasturl为时间戳,精确到后三位小数的时间戳,构造这个时间戳,后三位小数我就随机生成一个三位数了:
import time
import random
timerandom = random.randint(100,999)
nowtime = int(time.time())
lasturl = str(nowtime) + str(timerandom) + '='
最后制作postdata:
# 构造post
postdata = {
'tn':'resultjson_com',
'ipn':'rj',
'ct':201326592,
'is':'',
'fp':'result',
'queryWord': keyword,
'cl': 2,
'lm': -1,
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': -1,
'z':'',
'ic': 0,
'word': keyword,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': 0,
'istype': 2,
'qc': '',
'nc': 1,
'fr': '',
'pn': pn,
'rn': 30,
'gsm': '1e'
}
其中页数pn和搜索关键字keywork为:
# 搜索的关键字
# keywork = input('请输入你要查找的关键字')
keyword = 'gif' # 页数
# pn = int(input('你要抓取多少页:'))
pn = 30
将得到的信息保存在本地,当所有都保存下来了再去下载图片:
# 解析网址
contents = gethtml(url,postdata) # 将文件以json的格式保存在json文件夹
file = open('../json/' + str(pn) + '.json', 'wb')
file.write(contents.content)
file.close()
读取文件夹里面的所有文件:
# 找出文件夹下所有xml后缀的文件
def listfiles(rootdir, prefix='.xml'):
file = []
for parent, dirnames, filenames in os.walk(rootdir):
if parent == rootdir:
for filename in filenames:
if filename.endswith(prefix):
file.append(rootdir + '/' + filename)
return file
else:
pass
遍历json文件夹,读取里面的东西:
# 找到json文件夹下的所有文件名字
files = listfiles('../json/', '.json')
for filename in files:
print(filename)
# 读取json得到图片网址
doc = open(filename, 'rb')
# ('UTF-8')('unicode_escape')('gbk','ignore')
doccontent = doc.read().decode('utf-8', 'ignore')
product = doccontent.replace(' ', '').replace('\n', '')
product = json.loads(product)
查询字典data:
# 得到字典data
onefile = product['data']
将字典里面的图片网址和图片名称放到数组里面:
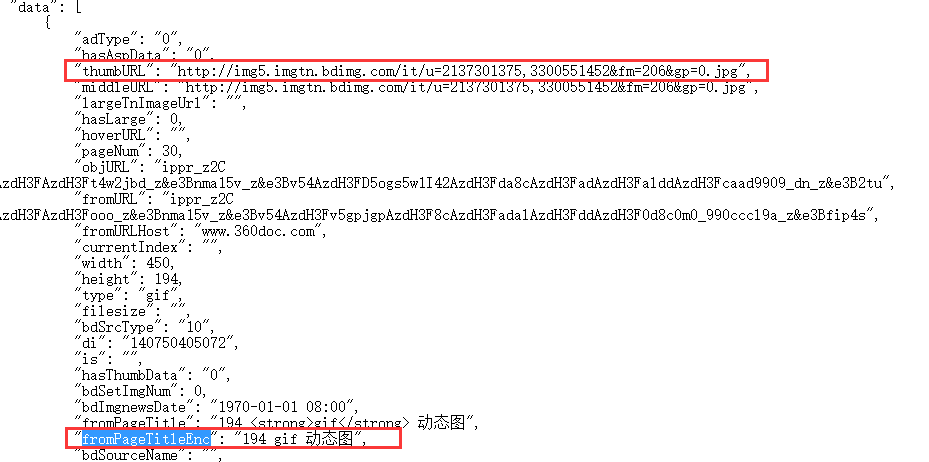
制作一个解析头来解析图片下载:
def getimg(url):
# 制作一个专家
opener = urllib.request.build_opener()
# 打开专家头部
opener.addheaders = [('User-Agent',
'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:46.0) Gecko/20100101 Firefox/46.0'),
('Referer',
'http://image.baidu.com'),
('Host', 'image.baidu.com')]
# 分配专家
urllib.request.install_opener(opener)
# 解析img
html_img = urllib.request.urlopen(url)
return html_img
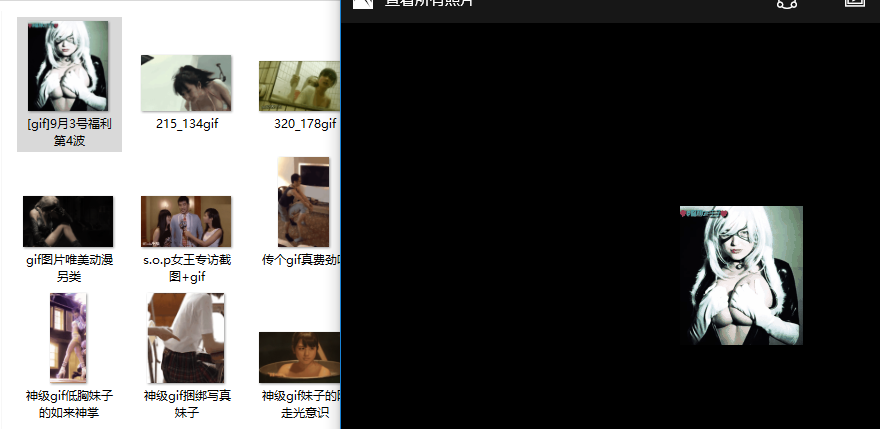
最后将图片下载到本地的gif文件夹:
for item in onefile:
try:
pic = getimg(item['thumbURL'])
# 保存地址和名称
filenamep = '../gif/' + validateTitle(item['fromPageTitleEnc'] + '.gif')
# 保存为gif
filess = open(filenamep, 'wb')
filess.write(pic.read())
filess.close() # 每一次下载都暂停1-3秒
loadimg = random.randint(1, 3)
print('图片' + filenamep + '下载完成')
print('暂停' + loadimg + '秒')
time.sleep(loadimg) except Exception as err:
print(err)
print('暂停' + loadimg + '秒')
time.sleep(loadimg)
pass
得到效果如下:
本文只是编程,处理这种网址最重要的是思想,思想我写在上一篇博文:
python3抓取异步百度瀑布流动态图片(一)查找post并伪装头方法
思想有了,程序是很简单的问题而已。
python3抓取异步百度瀑布流动态图片(二)get、json下载代码讲解的更多相关文章
- python3抓取异步百度瀑布流动态图片(一)查找post并伪装头方法
打开流程: 用火狐打开百度图片-->打开firebug-->输入GIF图-->搜索-->点击网络-->全部 观察页面: 首先要观察的对象是“域”,图片的json一般是放在 ...
- 如何利用Python网络爬虫抓取微信朋友圈的动态(上)
今天小编给大家分享一下如何利用Python网络爬虫抓取微信朋友圈的动态信息,实际上如果单独的去爬取朋友圈的话,难度会非常大,因为微信没有提供向网易云音乐这样的API接口,所以很容易找不到门.不过不要慌 ...
- Java学习-046-日志抓取合并后排序问题解决方案之 --- log4j 二次定制,实现日志输出添加延时10ms
自3月25至今,已经好久没有写学习日志了,今天在写日志抓取合并的小方法,发现抓取后的日志并米有依据系统执行的日志顺序排序.日志抓取排列逻辑如下: 通过日志标识,从各个日志文件(例如 use.log,e ...
- 【js】【图片瀑布流】js瀑布流显示图片20180315
js实现把图片用瀑布流显示,只需要“jquery-1.11.2.min.js”. js: //瀑布流显示图片 var WaterfallImg = { option: { maxWidth: 850, ...
- 利用wget 抓取 网站网页 包括css背景图片
利用wget 抓取 网站网页 包括css背景图片 wget是一款非常优秀的http/ftp下载工具,它功能强大,而且几乎所有的unix系统上都有.不过用它来dump比较现代的网站会有一个问题:不支持c ...
- 简单的抓取淘宝关键字信息、图片的Python爬虫|Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇)
Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇) 淘宝改字段,Bugfix,查看https://github.com/hunterhug/taobaoscrapy.git 由于Gith ...
- Python3抓取javascript生成的html网页
用urllib等抓取网页,只能读取网页的静态源文件,而抓不到由javascript生成的内容. 究其原因,是因为urllib是瞬时抓取,它不会等javascript的加载延迟,所以页面中由javasc ...
- python3抓取淘宝评论内容
好久没有写爬虫了,今天研究了下淘宝商品评论的内容. 一开始用最简单的方法,挂代理,加请求头,对网页请求,是抓不到数据的,在网上找了一些相关文章,也基本已经过时了,就是网站逻辑有改动,用旧的方法是抓不到 ...
- Python3 抓取豆瓣电影Top250
利用 requests 抓取豆瓣电影 Top 250: import re import requests def main(url): global num headers = {"Use ...
随机推荐
- CRM客户关系管理系统 ——客户联系人添加(十五)
需求描述: 1.业务员自己可以查看属于自己的客户信息 2.客服部经理可以查看查看所有客户信息 3.其他人员不得查看客户信息 效果截图:
- 查单神器v1.0 升级 →B站看鬼畜神器v1.0
去年学校实习,我去了一家快递输单公司工作.工作任务就是把运单图片上的内容(寄件人,地址之类)输入到公司的数据库里.每天输单结束后,还要对一些容易错的运单进行排查.单量多的时候一天甚至要查千张以上的运单 ...
- 【转】3 Essential Sublime Text Plugins for Node & JavaScript Developers
原文转自:http://scottksmith.com/blog/2014/09/29/3-essential-sublime-text-plugins-for-node-and-javascript ...
- AWK处理日志入门(转)
前言 这两天自己挽起袖子处理日志,终于把AWK给入门了.其实AWK的基本使用,学起来也就半天的时间,之前总是靠同事代劳,惰性呀. 此文仅为菜鸟入门,运维们请勿围观. 下面是被处理的日志的示例,不那么标 ...
- 【题解】【BST】【Leetcode】Unique Binary Search Trees
Given n, how many structurally unique BST's (binary search trees) that store values 1...n? For examp ...
- eclipse 中文乱码
使用Eclipse编辑文件经常出现中文乱码或者文件中有中文不能保存的问题,Eclipse提供了灵活的设置文件编码格式的选项,我们可以通过设置编码 格式解决乱码问题.在Eclipse可以从几个层面设置编 ...
- ZOJ 1047 Image Perimeters
原题链接 题目大意:鼠标点击一块,求与之联通的所有区域的边长之和. 解法:广度优先搜索.从选中的这个点开始,往周围8个点依次搜索,访问过的点做上标记.如果该点上下左右的一个或多个方向没有相邻的点,边长 ...
- MySql 查询一周内最近7天记录
本周内:select * from wap_content where week(created_at) = week(now) 查询一天:select * from table where to_d ...
- HDU-1520 Anniversary party(树形DP)
题目大意:一棵树,每个节点都带权.从中取出一些节点,并且子节点不能与父节点同时取,求能取得的最大值. 题目分析:定义状态dp(u,0/1)表示u点不取/取.则状态转移方程为: dp(u,1)=sum( ...
- Windows系统下使用Sublime搭建nodejs环境
最近在研究Nodejs开发,俗话说,工欲善其事,必先利其器,当然要找到一款用着顺手的编辑器作为开始.这里我们选择的是Sublime Text 3,除了漂亮的用户界面,最吸引我的就是它的插件扩展功能以及 ...