Tesseract-OCR4.0识别中文与训练字库实例
关于中文的识别,效果比较好而且开源的应该就是Tesseract-OCR了,所以自己亲身试用一下,分享到博客让有同样兴趣的人少走弯路。
文中所用到的身份证图片资源是百度找的,如有侵权可联系我删除。
一、准备工作
1、下载Tesseract-OCR引擎,注意要3.0以上才支持中文哦,按照提示安装就行。
最后下载4.0版本
2、下载chi_sim.traindata字库。要有这个才能识别中文。下好后,放到Tesseract-OCR项目的tessdata文件夹里面。
https://github.com/tesseract-ocr/tessdata/blob/master/chi_sim.traineddata
3、下载jTessBoxEditor,这个是用来训练字库的。
https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/jTessBoxEditor-1.7.3.zip/download
- 为了识别方便建议放到环境变量中.
二、识别
1、进入cmd,进入到要识别的图片的路径下。
-解决bug
出现了这个错误. 下面的意思就是说不能加载’eng’语言包。请将tessdata的父文件夹路径设置为TESSDATA_PREFIX环境变量值,这个就是说在环境变量中新建一个系统变量,变量名称为TESSDATA_PREFIX,tessdata是放置语言包的文件夹,一般在你安装tesseract的目录下,即tesseract的安装目录就是tessdata的父目录,把TESSDATA_PREFIX的值设置为它就行了

2、输入命令
tesseract 图片名称 生成的结果文件的名称 字库
例如我的图片识别就是:
tesseract test.jpg result -l chi_sim

识别完后会生成result.txt文件

三、训练
1、将图片转换成tif格式,用于后面生成box文件。可以通过画图,然后另存为tif即可。
更改图片名字,这个是有要求的=。=
tif文面命名格式[lang].[fontname].exp[num].tif
lang是语言 fontname是字体
比如我们要训练自定义字库 mjorcen字体名normal
那么我们把图片文件重命名 mjorcen.normal.exp0.jpg在转tif。
2、生成box文件。
tesseract mjorcen.normal.exp0.jpg mjorcen.normal.exp0 -l chi_sim batch.nochop makebox
box文件和对应的tif一定要在相同的目录下,不然后面打不开。
3、打开jTessBoxEditor矫正错误并训练
打开train.bat

找到tif图,打开,并校正。切换到图片所指的路径
出现乱码 这是因为你软件设置字体的问题
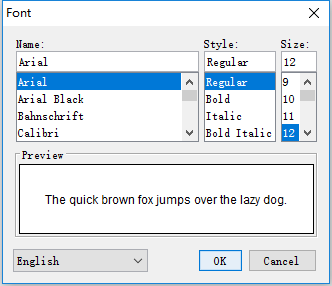
在setting>font 设置中文字体
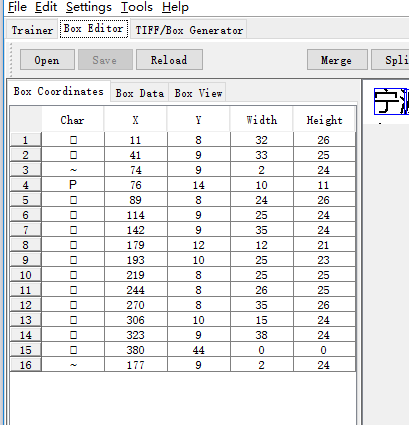
进行矫正 主要就是坐标 位置的调整,注意 添加需要选择上一个文字才能分离

Tesseract-OCR4.0识别中文与训练字库实例的更多相关文章
- Tesseract-OCR识别中文与训练字库实例
关于中文的识别,效果比较好而且开源的应该就是Tesseract-OCR了,所以自己亲身试用一下,分享到博客让有同样兴趣的人少走弯路. 文中所用到的身份证图片资源是百度找的,如有侵权可联系我删除. 一. ...
- 深入学习Tesseract-ocr识别中文并训练字库的方法
上篇文章简单的学习了tesseract-ocr识别图片中的英文(链接地址如下:https://www.cnblogs.com/wj-1314/p/9428909.html),看起来效果还不错,所以这篇 ...
- Tesseract-OCR识别中文与训练字库
转自:https://www.cnblogs.com/lcawen/articles/7040005.html 关于中文的识别,效果比较好而且开源的应该就是Tesseract-OCR了,所以自己亲身试 ...
- Tesseract识别图片提取文字&字库训练
文中测试了3.0和4.0两个版本.发现3.0识别效率不准确,需要训练词库.4.0识别效率就比较高了,而且支持结果生成pdf.txt等格式.所以推荐使用4.0版本. 这个工具可以用在爬虫的时候获取验证码 ...
- Tesseract5.0训练字库,提高OCR特殊场景识别率(一)
0.目标 很多特殊场景,原生的字库识别率不高,这时候就需要根据需求自己训练字库生成traineddata文件. 一.前期准备工作 1.安装jdk 用于运行jTessBoxEditor 2.安装jT ...
- Windows下Tesseract4.0识别与中文手写字体训练
一 . tesseract 4.0 安装及使用 1. tesseract 4.0 安装 安装包下载地址: http://digi.bib.uni-mannheim.de/tesseract/tesse ...
- tesseract-ocr如何训练Tesseract 4.0
引自:https://blog.csdn.net/huobanjishijian/article/details/76212214 原文:https://github.com/tesseract-oc ...
- 【OpenCV】opencv3.0中的SVM训练 mnist 手写字体识别
前言: SVM(支持向量机)一种训练分类器的学习方法 mnist 是一个手写字体图像数据库,训练样本有60000个,测试样本有10000个 LibSVM 一个常用的SVM框架 OpenCV3.0 中的 ...
- tesseract 4.0 ocr图像识别利器,可识别文字。图片越高清越准确
//总地址 https://github.com/tesseract-ocr/tesseract/wiki //windows exe tesseract 4.0下载: https://github. ...
随机推荐
- Linux中安装字体
Linux中安装字体 查看系统中的字体 fc-list 查看系统中的中文字体 fc-list :lang=zh将然后将字体文件拷贝到/usr/share/fonts/中 cp aa.ttl /usr/ ...
- Angular开发实践(二):HRM运行机制
引言 在angular-start项目中启用了模块热替换(HMR - Hot Module Replacement)功能,关于如何在angular-cli启用HRM,请查看HRM配置 那HMR是个什么 ...
- PHP之取得当前时间函数方法
PHP之取得当前时间函数方法 PHP之取得当前时间函数方法文章提供了php的几种获取当前时间的函数,date,time等,同时告诉我如何解决时区问题.php教程取得当前时间函数文章提供了php的几种获 ...
- 笔记:Maven 仓库和插件配置本机私服
通过配置POM中的配置仓库和插件仓库,只在当前项目生效,而实际应用中,我们希望通过一次配置就能让本机所有的Maven项目都使用自己的Maven私服,这个时候我们需要配置 settings.xml文件, ...
- HDU4310HERO贪心问题
问题描述 When playing DotA with god-like rivals and pig-like team members, you have to face an embarrass ...
- 设计模式 --> (10)享元模式
享元模式 运用共享技术有效地支持大量细粒度的对象. 享元对象能做到共享的关键是区分内蕴状态(Internal State)和外蕴状态(External State). 内蕴状态是存储在享元对象内部并且 ...
- STL --> list用法
List介绍 Lists将元素按顺序储存在链表中.与 向量(vectors)相比, 它允许快速的插入和删除,但是随机访问却比较慢. assign() // 给list赋值 back() // 返回最后 ...
- 解决设置clickablespan后长按冲突的问题
解决设置ClickableSpan后长按冲突的问题 问题描述 3月份修改别人代码的时候想要屏蔽TextView的长按事件,发现TextView有重写OnTouchEvent方法,然后在其中加了长按事件 ...
- 后台返回null iOS
1.第一种解决方案 就是在每一个 可能传回null 的地方 使用 if([object isEqual:[NSNUll null]]) 去判断 2.第二种解决方案 网上传说老外写了一个Categor ...
- c# 实时监控数据库 SqlDependency
http://blog.csdn.net/idays021/article/details/49661855 class Program { private static string _connSt ...