Tesseract-OCR4.0识别中文与训练字库实例
关于中文的识别,效果比较好而且开源的应该就是Tesseract-OCR了,所以自己亲身试用一下,分享到博客让有同样兴趣的人少走弯路。
文中所用到的身份证图片资源是百度找的,如有侵权可联系我删除。
一、准备工作
1、下载Tesseract-OCR引擎,注意要3.0以上才支持中文哦,按照提示安装就行。
最后下载4.0版本
2、下载chi_sim.traindata字库。要有这个才能识别中文。下好后,放到Tesseract-OCR项目的tessdata文件夹里面。
https://github.com/tesseract-ocr/tessdata/blob/master/chi_sim.traineddata
3、下载jTessBoxEditor,这个是用来训练字库的。
https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/jTessBoxEditor-1.7.3.zip/download
- 为了识别方便建议放到环境变量中.
二、识别
1、进入cmd,进入到要识别的图片的路径下。
-解决bug
出现了这个错误. 下面的意思就是说不能加载’eng’语言包。请将tessdata的父文件夹路径设置为TESSDATA_PREFIX环境变量值,这个就是说在环境变量中新建一个系统变量,变量名称为TESSDATA_PREFIX,tessdata是放置语言包的文件夹,一般在你安装tesseract的目录下,即tesseract的安装目录就是tessdata的父目录,把TESSDATA_PREFIX的值设置为它就行了

2、输入命令
tesseract 图片名称 生成的结果文件的名称 字库
例如我的图片识别就是:
tesseract test.jpg result -l chi_sim

识别完后会生成result.txt文件

三、训练
1、将图片转换成tif格式,用于后面生成box文件。可以通过画图,然后另存为tif即可。
更改图片名字,这个是有要求的=。=
tif文面命名格式[lang].[fontname].exp[num].tif
lang是语言 fontname是字体
比如我们要训练自定义字库 mjorcen字体名normal
那么我们把图片文件重命名 mjorcen.normal.exp0.jpg在转tif。
2、生成box文件。
tesseract mjorcen.normal.exp0.jpg mjorcen.normal.exp0 -l chi_sim batch.nochop makebox
box文件和对应的tif一定要在相同的目录下,不然后面打不开。
3、打开jTessBoxEditor矫正错误并训练
打开train.bat

找到tif图,打开,并校正。切换到图片所指的路径
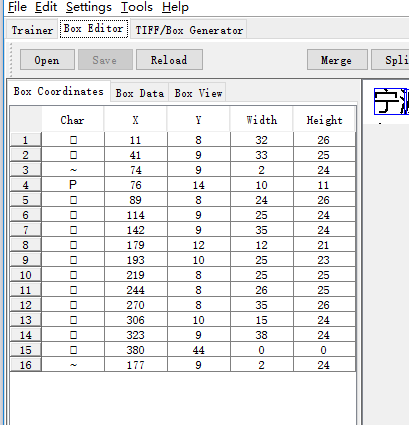
出现乱码 这是因为你软件设置字体的问题
在setting>font 设置中文字体
进行矫正 主要就是坐标 位置的调整,注意 添加需要选择上一个文字才能分离

Tesseract-OCR4.0识别中文与训练字库实例的更多相关文章
- Tesseract-OCR识别中文与训练字库实例
关于中文的识别,效果比较好而且开源的应该就是Tesseract-OCR了,所以自己亲身试用一下,分享到博客让有同样兴趣的人少走弯路. 文中所用到的身份证图片资源是百度找的,如有侵权可联系我删除. 一. ...
- 深入学习Tesseract-ocr识别中文并训练字库的方法
上篇文章简单的学习了tesseract-ocr识别图片中的英文(链接地址如下:https://www.cnblogs.com/wj-1314/p/9428909.html),看起来效果还不错,所以这篇 ...
- Tesseract-OCR识别中文与训练字库
转自:https://www.cnblogs.com/lcawen/articles/7040005.html 关于中文的识别,效果比较好而且开源的应该就是Tesseract-OCR了,所以自己亲身试 ...
- Tesseract识别图片提取文字&字库训练
文中测试了3.0和4.0两个版本.发现3.0识别效率不准确,需要训练词库.4.0识别效率就比较高了,而且支持结果生成pdf.txt等格式.所以推荐使用4.0版本. 这个工具可以用在爬虫的时候获取验证码 ...
- Tesseract5.0训练字库,提高OCR特殊场景识别率(一)
0.目标 很多特殊场景,原生的字库识别率不高,这时候就需要根据需求自己训练字库生成traineddata文件. 一.前期准备工作 1.安装jdk 用于运行jTessBoxEditor 2.安装jT ...
- Windows下Tesseract4.0识别与中文手写字体训练
一 . tesseract 4.0 安装及使用 1. tesseract 4.0 安装 安装包下载地址: http://digi.bib.uni-mannheim.de/tesseract/tesse ...
- tesseract-ocr如何训练Tesseract 4.0
引自:https://blog.csdn.net/huobanjishijian/article/details/76212214 原文:https://github.com/tesseract-oc ...
- 【OpenCV】opencv3.0中的SVM训练 mnist 手写字体识别
前言: SVM(支持向量机)一种训练分类器的学习方法 mnist 是一个手写字体图像数据库,训练样本有60000个,测试样本有10000个 LibSVM 一个常用的SVM框架 OpenCV3.0 中的 ...
- tesseract 4.0 ocr图像识别利器,可识别文字。图片越高清越准确
//总地址 https://github.com/tesseract-ocr/tesseract/wiki //windows exe tesseract 4.0下载: https://github. ...
随机推荐
- 【Unity与23种设计模式】责任链模式(Chain of Responsibility)
GoF中定义: "让一群对象都有机会来处理一项请求,以减少请求发送者与接收者之间的耦合度.将所有的接受对象串联起来,让请求沿着串接传递,直到有一个对象可以处理为止." 举个现实中的 ...
- pycharm中的光标变粗的问题
pycharm中的光标变粗后不能自动打成对的小括号和中括号及引号---->解决办法:按下insert键 按下:insert键进行切换
- 【吐槽向】iOS 中的仿射变换
什么是仿射变换矩阵 CGAffineTransform 实际上就是一个用于绘制 2D 图形的的仿射变换矩阵.仿射变换矩阵用于旋转.缩放.平移.扭曲(skew)在图形上下文中绘制的对象.CGAffine ...
- python趣味——与MS系列编译器一样强大的Unicode变量名支持
中文变量名,中文函数名,中文类名等,可惜Python2不支持,但在Python3时代,这些都可以完美支持了. def 中文函数(): return 1
- ASP.NET Core Web 支付功能接入 支付宝-电脑网页支付篇
这篇文章将介绍ASP.NET Core中使用 开源项目 Payment,实现接入支付宝-电脑网页支付接口及同步跳转及异步通知功能. 开发环境:Win 10 x64.VS2017 15.6.4..NET ...
- 请详细描述(以硬盘启动)Linux系统从打开主机电源到进入登录界面整个过程的流程。
1. 开机进行BIOS(BIOS(Basic Input / Output System)自检测系统外围硬件设备如CPU.内存.IO.显卡.鼠标键盘等.根据BIOS中设置的系统启动顺序搜索用于启动系统 ...
- 手把手的SpringBoot教程,SpringBoot创建web项目(五)
这一节,我们来演示如何在SpringBoot项目中连接数据库,并且自动创建一张表. 按照惯例,数据库我们依然使用mysql,至于什么是jpa呢? jpa是sun推出的持久化规范(java persis ...
- eclipse编码设置
- extract-text-webpack-plugin---webpack插件
var ExtractTextPlugin=require('extract-text-webpack-plugin');//build使用 { test:/\.css$/, use:ExtractT ...
- 【highlight.js】页面代码高亮插件
[highlight.js] 很多博客都支持页面插入各种语言的代码,而这些代码肯定是有高亮设置的.那么在我们自己的页面上如何进行代码高亮设置?有现成的这个highlight.js插件我们可以使用. h ...