小项目一---Python日志分析
日志分析
概述

分析的前提
半结构化数据

文本分析

提取数据(信息提取)
一、空格分隔
with open('xxx.log')as f:
for line in f:
for field in line.split():
print(field)


#注意这里拼接的一些技巧
logs = '''138.60.212.153 - - [19/Feb/2013:10:23:29 +0800] "GET /020/media.html?menu\
=3 HTTP/1.1" 200 16691 "-" "Mozilla/5.0 (compatible; EasouSpider; +http://www.easou\
.com/search/spider.html)"''' fields = []
flag = False
tmp = '' #注意拼接"GET /020/media.html?menu=3 HTTP/1.1"这种字符串需借助标记变量!
for field in logs.split():
if not flag and (field.startswith('[') or field.startswith('"')):
if field.endswith(']') or field.endswith('"'):#处理首尾均有[]的字符串
fields.append(field.strip('[]"'))
# 处理只有左中括号的字符串,但是该字符串应该与接下类的某一段含有右括号的字符拼接起来[19/Feb/2013:10:23:29
else:#
tmp += field[1:]
flag = True
continue
#处理[19/Feb/2013:10:23:29 +0800]中的+0800]
if flag:
if field.endswith(']') or field.endswith('"'):
tmp += " " + field[:-1]
fields.append(tmp)
tmp = ''
flag = False
else:
tmp +=" " + field
continue fields.append(field)#直接加入不带有[]""的字符串
类型转换


import datetime def convert_time(timestr):
return datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z') #若上面的函数可简写成匿名函数形式
lambda timestr:datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z')
请求信息的解析

def get_request(request:str):
return dict(zip(['method','url','protocol'],request.split())) #上面的函数对应为如下匿名函数
lambda request:dict(zip(['method','url','protocol'],request.split()))
映射

import datetime
logs = '''138.60.212.153 - - [19/Feb/2013:10:23:29 +0800] "GET /020/media.html?menu\
=3 HTTP/1.1" 200 16691 "-" "Mozilla/5.0 (compatible; EasouSpider; +http://www.easou\
.com/search/spider.html)"''' def convert_time(timestr):
return datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z') # lambda timestr:datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z') def get_request(request:str):
return dict(zip(['method','url','protocol'],request.split())) # lambda request:dict(zip(['method','url','protocol'],request.split())) names = ('remote','','','datetime','request','status','length','','useragent')
ops = (None,None,None,convert_time,get_request,int,int,None,None) def extract(line):
fields = []
flag = False
tmp = '' #"GET /020/media.html?menu=3 HTTP/1.1"
for field in logs.split():
if not flag and (field.startswith('[') or field.startswith('"')):
if field.endswith(']') or field.endswith('"'):#处理首尾均有[]的字符串
fields.append(field.strip('[]"'))
# 处理只有左中括号的字符串,但是该字符串应该与接下类的某一段含有右括号的字符拼接起来[19/Feb/2013:10:23:29
else:#
tmp += field[1:]
flag = True
continue
#处理[19/Feb/2013:10:23:29 +0800]中的+0800]
if flag:
if field.endswith(']') or field.endswith('"'):
tmp += " " + field[:-1]
fields.append(tmp)
tmp = ''
flag = False
else:
tmp +=" " + field
continue fields.append(field)#直接加入不带有[]""的字符串 # print(fields)
info = {}
for i,field in enumerate(fields):
name = names[i]
op = ops[i]
if op:
info[name] = (op(field))
return info print(extract(logs))
二、正则表达式提取

pattern = '''([\d.]{7,}) - - \[([/\w +:]+)\] "(\w+) (\S+) ([\w/\d.]+)" (\d+) (\d+) .+ "(.+)"'''
names = ('remote','datetime','request','method','url','ptorocol','status','length','useragent')
ops = (None,lambda timestr:datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z'),None,None,None,int,int,None)

pattern = '''(?P<remote>[\d.]{7,}) - - \[(?P<datetime>[/\w +:]+)\] \
"(?P<method>\w+) (?P<url>\S+) (?P<protocol>[\w/\d.]+)"\
(?P<status>\d+) (?P<length>\d+) .+ "(?PM<useragent>.+)"'''
ops = {
'datetime': lambda timestr:datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z'),
'status':int,
'length':int
}
import datetime
import re
logs = '''138.60.212.153 - - [19/Feb/2013:10:23:29 +0800] "GET /020/media.html?menu=3 HTTP/1.1" 200 16997 "-" "Mozilla/5.0 (compatible; EasouSpider; +http://www.easou.com/search/spider.html)"'''
pattern = '''(?P<remote>[\d.]{7,}) - - \[(?P<datetime>[\w/ +:]+)\] "(?P<method>\w+) (?P<url>\S+) (?P<protocol>[\w/\d.]+)" (?P<status>\d+) (?P<length>\d+) .+ "(?P<useragent>.+)"''' ops = {
'datetime': lambda timestr:datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z'),
'status':int,
'length':int
} regex = re.compile(pattern)
def extract(line):
matcher = regex.match(line)
#matcher.groupdict()函数返回一个包含所有match匹配的命名分组的字典
info = {k:ops.get(k,lambda x:x)(v) for k,v in matcher.groupdict().items()}
return info print(extract(logs))
异常处理






滑动窗口
数据载入

时间窗口分析
概念

当width>interval(数据求值时会有重叠)
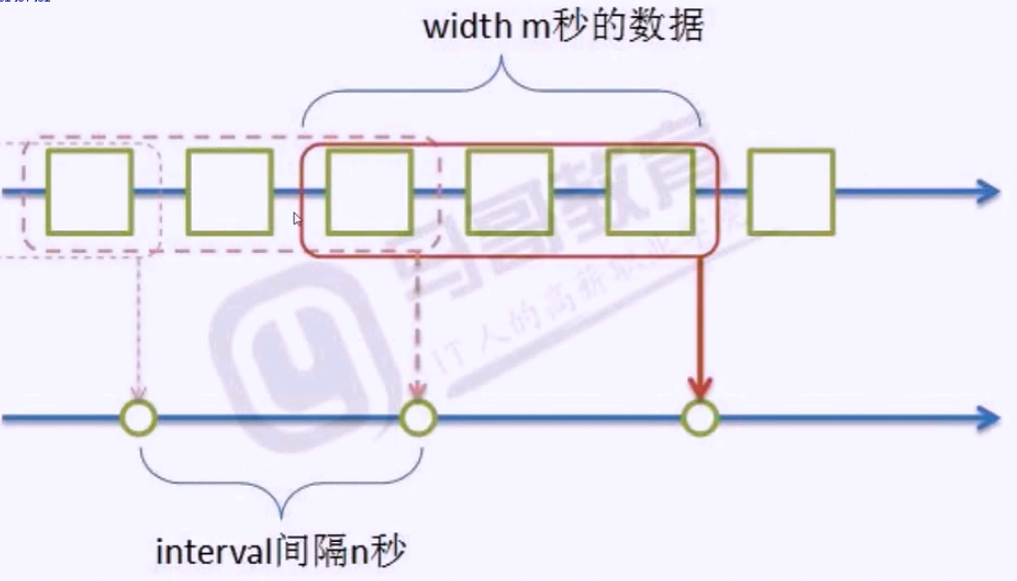
当width=interval(数据求值时没有重叠)
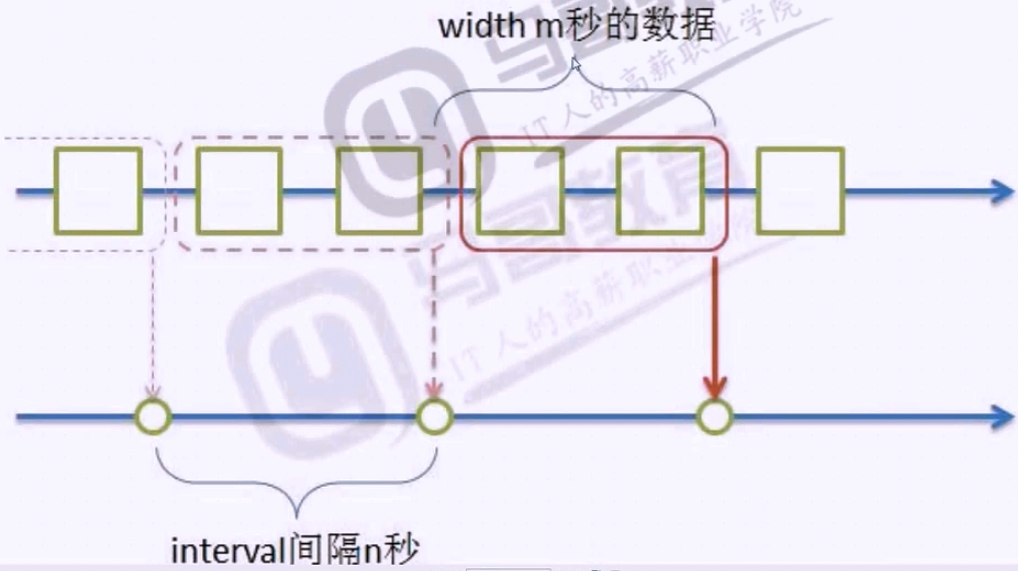
当width<interval(一般不采纳这种方案,会有数据缺失)
时序数据

数据分析基本程序结构

import random
import datetime def source():
while True:
yield {'datetime':datetime.datetime.now(),'value':random.randint(1,10)} #获取数据
src = source()
items = [next(src) for _ in range(3)]
# print(items) #处理函数
def handler(iterable):
vals = [x['value'] for x in iterable]
return sum(vals)/len(vals) print(handler(items))
#上述代码实模拟了一段时间内产生了数据,等了一段固定的时间取数据计算其平均值。
窗口函数实现
将上面的获取数据的程序扩展为windows函数,使用重叠的方案!
#代码实现:
import random
import datetime
import time def source():
while True:
yield {'value':random.randint(1,100),'datetime':datetime.datetime.now()}
time.sleep(1)
def windows(src,handler,width:int,interval:int):
"""
:param src:数据源、生成器、用来拿数据
:param handler: 数据处理函数
:param width: 时间窗口宽度,秒
:param interval: 处理时间间隔,秒
:return:None
"""
start = datetime.datetime.strptime('19710101 00:00:00 +0800','%Y/%m/%d %H:%M:%S %z')
current = datetime.datetime.strptime('19710101 00:00:01 +0800','%Y/%m/%d %H:%M:%S %z')
buffer = [] #窗口中待计算的数据
delta = datetime.timedelta(seconds=width-interval) for data in src:
if data:#存入临时缓存区
buffer.append(x)
current =data['datetime'] if (current - start).total_seconds() >= interval:
ret = handler(buffer)
print("{:.2f}".format(ret))
start = current
#更新buffer,current - delta表示需要重叠的数据
buffer = [x for x in buffer if x['datetime'] > current - delta] #处理函数
def handler(iterable):
vals = [x['value'] for x in iterable]
return sum(vals) / len(vals) windows(source(),handler,10,5)
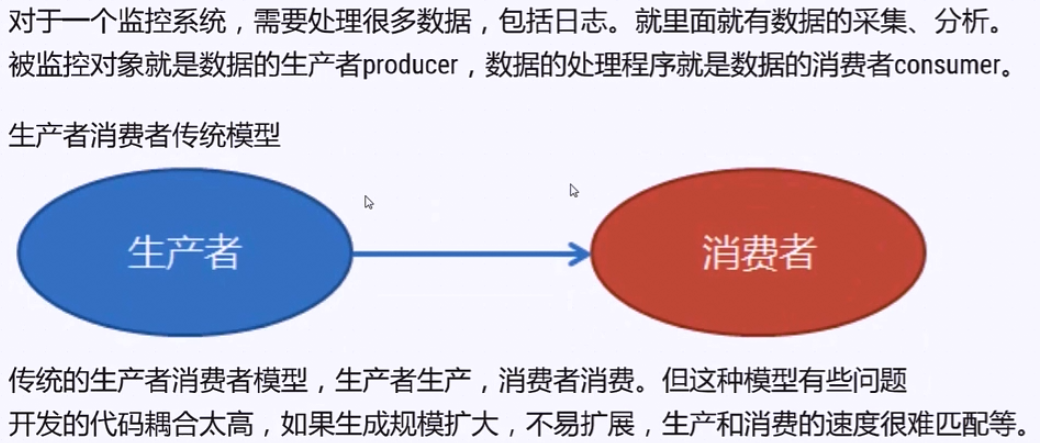
分发
生产者消费模型


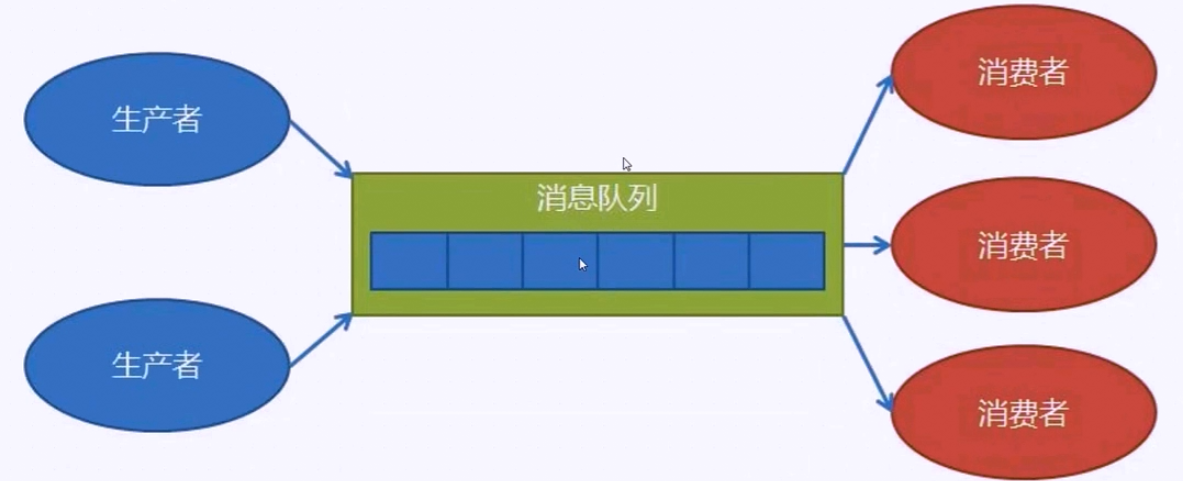


queue模块--队列






from queue import Queue
import random q = Queue()
print(q.put(random.randint(1,100)))
print(q.put(random.randint(1,100))) print(q.get())
print(q.get())
print(q.get(timeout=2))#阻塞两秒后抛出空值异常
分发器的实现






import threading
#定义线程
#target线程中运行的函数;args这个函数运行时需要的实参
t = threading.Thread(target=windows,args=(src,handler,width,interval)) #启动线程
t.start()
分发器代码实现

# Author: Baozi
#-*- codeing:utf-8 -*- # Author: Baozi
#-*- codeing:utf-8 -*- #日志分析项目
'''
1.新建一个python文件test.py
2.从日志文件中复制一条日志信息用于测试。logline存储这个日志字符串
'''
import threading
from queue import Queue
import datetime
import re
import random
import time # logs = '''138.60.212.153 - - [19/Feb/2013:10:23:29 +0800] "GET /020/media.html?menu=3 HTTP/1.1" 200 16997 "-" "Mozilla/5.0 (compatible; EasouSpider; +http://www.easou.com/search/spider.html)"'''
pattern = '''(?P<remote>[\d.]{7,}) - - \[(?P<datetime>[\w/ +:]+)\] "(?P<method>\w+) (?P<url>\S+) (?P<protocol>[\w/\d.]+)" (?P<status>\d+) (?P<length>\d+) .+ "(?P<useragent>.+)"''' ops = {
'datetime': lambda timestr:datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z'),
'status':int,
'length':int
} regex = re.compile(pattern)
def extract(line):
matcher = regex.match(line)
print(matcher.groupdict())
#matcher.groupdict()函数返回一个包含所有match匹配的命名分组的字典
info = {k:ops.get(k,lambda x:x)(v) for k,v in matcher.groupdict().items()}
return info def load(path:str):
#单文件装载
with open(path)as f:
for line in f:
d = extract(line)
if d:
yield d
else:
#TODO 不合格的数据
continue
############################滑动窗口实现##################################################def windows(src:Queue,handler,width:int,interval:int):
"""
:param src:数据源、生成器、用来拿数据
:param handler: 数据处理函数
:param width: 时间窗口宽度,秒
:param interval: 处理时间间隔,秒
:return:
"""
start = datetime.datetime.strptime('1971/01/01 00:00:00 +0800','%Y/%m/%d %H:%M:%S %z')
current = datetime.datetime.strptime('1971/01/01 00:00:01 +0800','%Y/%m/%d %H:%M:%S %z')
buffer = [] #窗口中待计算的数据
delta = datetime.timedelta(seconds=width-interval) while True:
data = src.get()
if data:
buffer.append(data)
current =data['datetime'] if (current - start).total_seconds() >= interval:
ret = handler(buffer)
print(ret)
start = current
#buffer的处理
buffer = [x for x in buffer if x['datetime'] > current - delta] #处理函数
def handler(iterable):
vals = [x['value'] for x in iterable]
return sum(vals) / len(vals) def donothing_handler(iterable:list):
print(iterable)
return iterable ######################分发器实现##########################################
#数据分发器:这里做一个简单的一对多副本发送,一个数据通过分发器,发送到n个消费者
def dispatcher(src):
queues = []
threads = [] def req(handler,width,interval):
q = Queue()
queues.append(q) t = threading.Thread(target=windows,args=(q,handler,width,interval))
threads.append(t) def run():
for t in threads:
t.start() for x in src:#一条数据送到n个消费者各自的队列中
for q in queues:
q.put(x) return req,run req,run = dispatcher(load('test.log')) #req注册窗口
req(donothing_handler,1,1) #启动
run()
完成分析功能

状态码分析

def status_handler(iterable):
#一批时间窗口内的数据
status = {}
for item in iterable:
key = item['status']
if key not in status.keys():
status[key] = 0
status[key] = 1
total = sum(status.values())
return {k:v/total*100 for k,v in status.items()}

日志文件的加载

def openfile(path:str):
with open(path)as f:
for line in f:
d = extract(line)
if d:
yield d
else:
# TODO 不合格的数据
continue def load(*path:str):
#装载日志文件
for file in path:
p = Path(file)
if not p.exists():
continue
if p.is_dir():
for x in p.iterdir():
if x.if_file():
yield from openfile(str(x))
elif p.is_file():
yield from openfile(str(p))

完整代码如下:
#日志分析项目
'''
1.新建一个python文件test.py
2.从日志文件中复制一条日志信息用于测试。logline存储这个日志字符串
'''
import threading
from queue import Queue
import datetime
import re
import random
import time
from pathlib import Path
# logline = '''138.60.212.153 - - [19/Feb/2013:10:23:29 +0800] "GET /020/media.html?menu=3 HTTP/1.1" 200 16997 "-" "Mozilla/5.0 (compatible; EasouSpider; +http://www.easou.com/search/spider.html)"'''
pattern = '''(?P<remote>[\d.]{7,}) - - \[(?P<datetime>[\w/ +:]+)\] "(?P<method>\w+) (?P<url>\S+) (?P<protocol>[\w/\d.]+)" (?P<status>\d+) (?P<length>\d+) .+ "(?P<useragent>.+)"''' ops = {
'datetime': lambda timestr:datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z'),
'status':int,
'length':int
}
regex = re.compile(pattern) def extract(line):
matcher = regex.match(line)
print(matcher.groupdict())
#matcher.groupdict()函数返回一个包含所有match匹配的命名分组的字典
info = {k:ops.get(k,lambda x:x)(v) for k,v in matcher.groupdict().items()}
return info def openfile(path:str):
with open(path)as f:
for line in f:
d = extract(line)
if d:
yield d
else:
# TODO 不合格的数据
continue def load(*path:str):
#文件装载
for file in path:
p = Path(file)
if not p.exists():
continue
if p.is_dir():
for x in p.iterdir():
if x.if_file():
yield from openfile(str(x))
elif p.is_file():
yield from openfile(str(p))
##################################滑动窗口实现##################################################
def windows(src:Queue,handler,width:int,interval:int):
start = datetime.datetime.strptime('1971/01/01 00:00:00 +0800','%Y/%m/%d %H:%M:%S %z')
current = datetime.datetime.strptime('1971/01/01 00:00:01 +0800','%Y/%m/%d %H:%M:%S %z')
buffer = [] #窗口中待计算的数据
delta = datetime.timedelta(seconds=width-interval) while True:
data = src.get()
if data:
buffer.append(data)
current =data['datetime'] if (current - start).total_seconds() >= interval:
ret = handler(buffer)
print(ret)
start = current
#buffer的处理
buffer = [x for x in buffer if x['datetime'] > current - delta] #处理函数
def status_handler(iterable):
#一批时间窗口内的数据
status = {}
for item in iterable:
key = item['status']
if key not in status.keys():
status[key] = 0
status[key] = 1
total = sum(status.values())
return {k:v/total*100 for k,v in status.items()} def handler(iterable):
vals = [x['value'] for x in iterable]
return sum(vals) / len(vals) def donothing_handler(iterable:list):
print(iterable)
return iterable
##########################数据分发器实现####################################
#数据分发器:这里做一个简单的一对多副本发送,一个数据通过分发器,发送到n个消费者
def dispatcher(src):
queues = []
threads = [] def req(handler,width,interval):
q = Queue()
queues.append(q) t = threading.Thread(target=windows,args=(q,handler,width,interval))
threads.append(t) def run():
for t in threads:
t.start() for x in src:#一条数据送到n个消费者各自的队列中
for q in queues:
q.put(x) return req,run req,run = dispatcher(load('test.log'))
#req注册窗口
req(donothing_handler,1,1)
# req(status_handler,2,2) #启动
run()
浏览器分析
useragent


信息提取

from user_agents import parse useragent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36"
uaobj = parse(useragent) print(uaobj.browser)
print(uaobj.browser.family,uaobj.browser.version)
#输出如下:
Browser(family='Chrome', version=(67, 0, 3396), version_string='67.0.3396')
Chrome (67, 0, 3396)
#日志分析完整代码(新增几个小模块)
# Author: Baozi
#-*- codeing:utf-8 -*-
#日志分析项目
'''
1.新建一个python文件test.py
2.从日志文件中复制一条日志信息用于测试。logline存储这个日志字符串
'''
import threading
from queue import Queue
import datetime
import re
import random
import time
from pathlib import Path
from user_agents import parse
from collections import defaultdict # logline = '''138.60.212.153 - - [19/Feb/2013:10:23:29 +0800] "GET /020/media.html?menu=3 HTTP/1.1" 200 16997 "-" "Mozilla/5.0 (compatible; EasouSpider; +http://www.easou.com/search/spider.html)"'''
# pattern = '''(?P<remote>[\d.]{7,}) - - \[(?P<datetime>[\w/ +:]+)\] "(?P<method>\w+) (?P<url>\S+) (?P<protocol>[\w/\d.]+)" (?P<status>\d+) (?P<length>\d+) .+ "(?P<useragent>.+)"'''
pattern = '''(?P<remote>[\d.]{7,}) - - \[(?P<datetime>[\w/ +:]+)\] "(?P<request>[^"]+)" (?P<status>\d+) (?P<length>\d+) .+ "(?P<useragent>.+)"''' ops = {
'datetime': lambda timestr:datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z'),
'status':int,
'length':int,
'request':lambda request:dict(zip(('method','url','ptorocol'),request.split())),
'useragent':lambda useragent:parse(useragent)
}
regex = re.compile(pattern) def extract(line):
matcher = regex.match(line)
print(matcher.groupdict())
#matcher.groupdict()函数返回一个包含所有match匹配的命名分组的字典
info = {k:ops.get(k,lambda x:x)(v) for k,v in matcher.groupdict().items()}
return info def openfile(path:str):
with open(path)as f:
for line in f:
d = extract(line)
if d:
yield d
else:
# TODO 不合格的数据
continue def load(*path:str):
#文件装载
for file in path:
p = Path(file)
if not p.exists():
continue
if p.is_dir():
for x in p.iterdir():
if x.if_file():
yield from openfile(str(x))
elif p.is_file():
yield from openfile(str(p))
###################################滑动窗口实现##############################################
def windows(src:Queue,handler,width:int,interval:int):
start = datetime.datetime.strptime('1971/01/01 00:00:00 +0800','%Y/%m/%d %H:%M:%S %z')
current = datetime.datetime.strptime('1971/01/01 00:00:01 +0800','%Y/%m/%d %H:%M:%S %z')
buffer = [] #窗口中待计算的数据
delta = datetime.timedelta(seconds=width-interval) while True:
data = src.get()
if data:
buffer.append(data)
current =data['datetime'] if (current - start).total_seconds() >= interval:
ret = handler(buffer)
print(ret)
start = current
#buffer的处理
buffer = [x for x in buffer if x['datetime'] > current - delta] #处理函数
#状态码分析
def status_handler(iterable):
#一批时间窗口内的数据
status = {}
for item in iterable:
key = item['status']
if key not in status.keys():
status[key] = 0
status[key] = 1
total = sum(status.values())
return {k:v/total*100 for k,v in status.items()} #浏览器分析
ua_dict = defaultdict(lambda :0)
def browser_handler(iterable:list):
for item in iterable:
ua = item['useragent']
key = (ua.browser.family,ua.browser.version_string)
ua_dict[key] =1
return ua_dict def handler(iterable):
vals = [x['value'] for x in iterable]
return sum(vals) / len(vals) def donothing_handler(iterable:list):
print(iterable)
return iterable
###########################数据分发器实现#####################################
#数据分发器:这里做一个简单的一对多副本发送,一个数据通过分发器,发送到n个消费者
def dispatcher(src):
queues = []
threads = [] def req(handler,width,interval):
q = Queue()
queues.append(q)
t = threading.Thread(target=windows,args=(q,handler,width,interval))
threads.append(t) def run():
for t in threads:
t.start() for x in src:#一条数据送到n个消费者各自的队列中
for q in queues:
q.put(x)
return req,run req,run = dispatcher(load('test.log'))
#req注册窗口
# req(donothing_handler,1,1)
# req(status_handler,2,2)
req(browser_handler,2,2) #启动
run()
小项目一---Python日志分析的更多相关文章
- 【实战小项目】python开发自动化运维工具--批量操作主机
有很多开源自动化运维工具都很好用如ansible/salt stack等,完全不用重复造轮子.只不过,很多运维同学学习Python之后,苦于没小项目训练.本篇就演示用Python写一个批量操作主机的工 ...
- python小项目(python实现鉴黄)源码
import sys import os import _io from collections import namedtuple from PIL import Image class Nude( ...
- 10分钟掌握Python-机器学习小项目
学习机器学习相关技术的最好方式就是先自己设计和完成一些小项目. Python 是一种非常流行和强大的解释性编程语言.不像 R 语言,Python 是个很完整的语言和平台,你既可以用来做研发,也可以用来 ...
- Python+Selenium进行UI自动化测试项目中,常用的小技巧4:日志打印,longging模块(控制台和文件同时输出)
在前段时间,为了给项目中加入日志功能,就想到了 logging 模块,百度logging一大推,都是各种复制的,并没有找到自己想要的结果:我的目的很简单,就是:在把日志写入文件的同时在控制台输出,更加 ...
- Hadoop学习笔记—20.网站日志分析项目案例(一)项目介绍
网站日志分析项目案例(一)项目介绍:当前页面 网站日志分析项目案例(二)数据清洗:http://www.cnblogs.com/edisonchou/p/4458219.html 网站日志分析项目案例 ...
- Hadoop学习笔记—20.网站日志分析项目案例(二)数据清洗
网站日志分析项目案例(一)项目介绍:http://www.cnblogs.com/edisonchou/p/4449082.html 网站日志分析项目案例(二)数据清洗:当前页面 网站日志分析项目案例 ...
- python网页爬虫小项目开发
这是我最近接的一个小项目,花了是整整四天多时间. 任务是将http://www.examcoo.com/index/detail/mid/7网站下所有的试卷里的试题全部提取出来,首先按照题型进行分类, ...
- Azure HDInsight 上的 Spark 群集配合自定义的Python来分析网站日志
一.前言:本文是个实践博客,演示如何结合使用自定义库和 HDInsight 上的 Spark 来分析日志数据. 我们使用的自定义库是一个名为 iislogparser.py的 Python 库. 每步 ...
- python 多线程日志切割+日志分析
python 多线程日志切割+日志分析 05/27. 2014 楼主最近刚刚接触python,还是个小菜鸟,没有学习python之前可以说楼主的shell已经算是可以了,但用shell很多东西实现起来 ...
随机推荐
- ASP.NET Core - 从Program和Startup开始
Program 我们先看一下1.x和2.x的程序入口项的一个差异 1.x public class Program { public static void Main(string[] args) { ...
- C++ 编译期封装-Pimpl技术
Pimpl技术——编译期封装 Pimpl 意思为“具体实现的指针”(Pointer to Implementation), 它通过一个私有的成员指针,将指针所指向的类的内部实现数据进行隐藏, 是隐藏实 ...
- SLAM+语音机器人DIY系列:(八)高阶拓展——2.centos7下部署Django(nginx+uwsgi+django+python3)
0.安装步骤预览(1)系统默认自带python2.x,所以需要先安装python3.x(2)python2对应pip,python3对应pip3,用源码安装python3后pip3也自动安装了(3)用 ...
- 文件输入输出流工具: IOUtils使用总结
序言 以前写文件的复制很麻烦,需要各种输入流,然后读取line,输出到输出流...其实apache.commons.io里面提供了输入流输出流的常用工具方法,非常方便.下面就结合源码,看看IOUTil ...
- AngularJs with Webpackv1 升級到 Webpack4
本篇記錄一下升級的血淚過程 請注意升級前請先創一個新目錄將升級應用與舊應用隔離 1. 需要將相關的套件做統一升級的動作,已確認需要升級所有舊的loaders 其它應用的套件可先不做升級的動作 (如果編 ...
- Redis 小白指南(二)- 聊聊五大类型:字符串、散列、列表、集合和有序集合
Redis 小白指南(二)- 聊聊五大类型:字符串.散列.列表.集合和有序集合 引言 开篇<Redis 小白指南(一)- 简介.安装.GUI 和 C# 驱动介绍>已经介绍了 Redis 的 ...
- Python基础学习01
1.编译型解释型语言区别: 编译型:一次性将全部代码编译成二进制文件,代表c,c++ 优点:执行效率高 缺点:开发速度慢,不能跨平台 解释型:当程序运行时,从上至下一行一行执行,解释成二进制去执行 优 ...
- Java 创建、填充PDF表单域
表单域,可以按用途分为多种不同的类型,常见的有文本框.多行文本框.密码框.隐藏域.复选框.单选框和下拉选择框等,目的是用于采集用户的输入或选择的数据.下面的示例中,将分享通过Java编程在PDF中添加 ...
- HTML中块元素与内联元素的概念
HTML中块元素与内联元素的概念 div就是一个块元素,所谓的块元素就是会独占一行的的元素,无论他的内容有多少,他都会独占一整行. p h1 h2 h3 ... div这个标签没有任何语义,就是一个纯 ...
- 关于Fragment里面嵌套fragment
今天看到一篇好文章 https://www.2cto.com/kf/201609/545979.html 转载过来记录一下,往后需要的时候可以随时查看: 接下来进入正题: 动态fragment的使用 ...