深入浅出KNN算法(二) sklearn KNN实践
姊妹篇:
深入浅出KNN算法(一) 原理介绍
上次介绍了KNN的基本原理,以及KNN的几个窍门,这次就来用sklearn实践一下KNN算法。
一.Skelarn KNN参数概述
要使用sklearnKNN算法进行分类,我们需要先了解sklearnKNN算法的一些基本参数,那么这节就先介绍这些内容吧。
def KNeighborsClassifier(n_neighbors = 5,
weights='uniform',
algorithm = '',
leaf_size = '30',
p = 2,
metric = 'minkowski',
metric_params = None,
n_jobs = None
)
- n_neighbors:这个值就是指 KNN 中的 “K”了。前面说到过,通过调整 K 值,算法会有不同的效果。
- weights(权重):最普遍的 KNN 算法无论距离如何,权重都一样,但有时候我们想搞点特殊化,比如距离更近的点让它更加重要。这时候就需要 weight 这个参数了,这个参数有三个可选参数的值,决定了如何分配权重。参数选项如下:
• 'uniform':不管远近权重都一样,就是最普通的 KNN 算法的形式。
• 'distance':权重和距离成反比,距离预测目标越近具有越高的权重。
• 自定义函数:自定义一个函数,根据输入的坐标值返回对应的权重,达到自定义权重的目的。
- algorithm:在 sklearn 中,要构建 KNN 模型有三种构建方式,1. 暴力法,就是直接计算距离存储比较的那种放松。2. 使用 kd 树构建 KNN 模型 3. 使用球树构建。 其中暴力法适合数据较小的方式,否则效率会比较低。如果数据量比较大一般会选择用 KD 树构建 KNN 模型,而当 KD 树也比较慢的时候,则可以试试球树来构建 KNN。参数选项如下:
• 'brute' :蛮力实现
• 'kd_tree':KD 树实现 KNN
• 'ball_tree':球树实现 KNN
• 'auto': 默认参数,自动选择合适的方法构建模型
不过当数据较小或比较稀疏时,无论选择哪个最后都会使用 'brute'
- leaf_size:如果是选择蛮力实现,那么这个值是可以忽略的,当使用KD树或球树,它就是是停止建子树的叶子节点数量的阈值。默认30,但如果数据量增多这个参数需要增大,否则速度过慢不说,还容易过拟合。
- p:和metric结合使用的,当metric参数是"minkowski"的时候,p=1为曼哈顿距离, p=2为欧式距离。默认为p=2。
- metric:指定距离度量方法,一般都是使用欧式距离。
• 'euclidean' :欧式距离
• 'manhattan':曼哈顿距离
• 'chebyshev':切比雪夫距离
• 'minkowski': 闵可夫斯基距离,默认参数
- n_jobs:指定多少个CPU进行运算,默认是-1,也就是全部都算。
二. KNN代码实例
KNN算法算是机器学习里面最简单的算法之一了,我们来sklearn官方给出的例子,来看看KNN应该怎样使用吧:
数据集使用的是著名的鸢尾花数据集,用KNN来对它做分类。我们先看看鸢尾花长的啥样。
上面这个就是鸢尾花了,这个鸢尾花数据集主要包含了鸢尾花的花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性(特征),以及鸢尾花卉属于『Setosa,Versicolour,Virginica』三个种类中的哪一类(这三种都长什么样我也不知道)。
在使用KNN算法之前,我们要先决定K的值是多少,要选出最优的K值,可以使用sklearn中的交叉验证方法,代码如下:
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
#读取鸢尾花数据集
iris = load_iris()
x = iris.data
y = iris.target
k_range = range(1, 31)
k_error = []
#循环,取k=1到k=31,查看误差效果
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
#cv参数决定数据集划分比例,这里是按照5:1划分训练集和测试集
scores = cross_val_score(knn, x, y, cv=6, scoring='accuracy')
k_error.append(1 - scores.mean())
#画图,x轴为k值,y值为误差值
plt.plot(k_range, k_error)
plt.xlabel('Value of K for KNN')
plt.ylabel('Error')
plt.show()
运行后,我们可以得到下面这样的图:
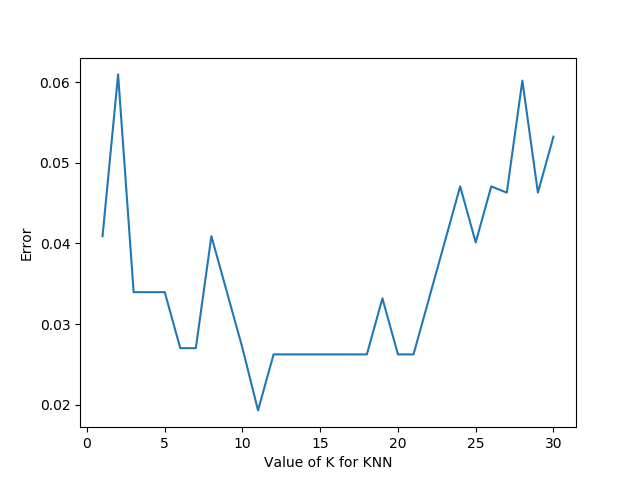
有了这张图,我们就能明显看出K值取多少的时候误差最小,这里明显是K=11最好。当然在实际问题中,如果数据集比较大,那为减少训练时间,K的取值范围可以缩小。
有了K值我们就能运行KNN算法了,具体代码如下:
import matplotlib.pyplot as plt
from numpy import *
from matplotlib.colors import ListedColormap
from sklearn import neighbors, datasets
n_neighbors = 11
# 导入一些要玩的数据
iris = datasets.load_iris()
x = iris.data[:, :2] # 我们只采用前两个feature,方便画图在二维平面显示
y = iris.target
h = .02 # 网格中的步长
# 创建彩色的图
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])
#weights是KNN模型中的一个参数,上述参数介绍中有介绍,这里绘制两种权重参数下KNN的效果图
for weights in ['uniform', 'distance']:
# 创建了一个knn分类器的实例,并拟合数据。
clf = neighbors.KNeighborsClassifier(n_neighbors, weights=weights)
clf.fit(x, y)
# 绘制决策边界。为此,我们将为每个分配一个颜色
# 来绘制网格中的点 [x_min, x_max]x[y_min, y_max].
x_min, x_max = x[:, 0].min() - 1, x[:, 0].max() + 1
y_min, y_max = x[:, 1].min() - 1, x[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
# 将结果放入一个彩色图中
Z = Z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
# 绘制训练点
plt.scatter(x[:, 0], x[:, 1], c=y, cmap=cmap_bold)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("3-Class classification (k = %i, weights = '%s')"
% (n_neighbors, weights))
plt.show()
KNN和Kmeans
前面说到过,KNN和Kmeans听起来有些像,但本质是有区别的,这里我们就顺便说一下两者的异同吧。
相同:
- K值都是重点
- 都需要计算平面中点的距离
相异:
Knn和Kmeans的核心都是通过计算空间中点的距离来实现目的,只是他们的目的是不同的。KNN的最终目的是分类,而Kmeans的目的是给所有距离相近的点分配一个类别,也就是聚类。
简单说,就是画一个圈,KNN是让进来圈子里的人变成自己人,Kmeans是让原本在圈内的人归成一类人。
以上
深入浅出KNN算法(二) sklearn KNN实践的更多相关文章
- 具体knn算法概念参考knn代码python实现
具体knn算法概念参考knn代码python实现上面是参考<机器学习实战>的代码,和knn的思想 # _*_ encoding=utf8 _*_ import numpy as npimp ...
- 深入浅出KNN算法(一) KNN算法原理
一.KNN算法概述 KNN可以说是最简单的分类算法之一,同时,它也是最常用的分类算法之一,注意KNN算法是有监督学习中的分类算法,它看起来和另一个机器学习算法Kmeans有点像(Kmeans是无监督学 ...
- 机器学习之KNN算法
1 KNN算法 1.1 KNN算法简介 KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属 ...
- 机器学习-K近邻(KNN)算法详解
一.KNN算法描述 KNN(K Near Neighbor):找到k个最近的邻居,即每个样本都可以用它最接近的这k个邻居中所占数量最多的类别来代表.KNN算法属于有监督学习方式的分类算法,所谓K近 ...
- 机器学习(二)-kNN手写数字识别
一.kNN算法是机器学习的入门算法,其中不涉及训练,主要思想是计算待测点和参照点的距离,选取距离较近的参照点的类别作为待测点的的类别. 1,距离可以是欧式距离,夹角余弦距离等等. 2,k值不能选择太大 ...
- 机器学习【三】k-近邻(kNN)算法
一.kNN算法概述 kNN算法是用来分类的,其依据测量不同特征值之间的距离,其核心思想在于用距离目标最近的k个样本数据的分类来代表目标的分类(这k个样本数据和目标数据最为相似).其精度高,对异常值不敏 ...
- knn算法之预测数字
训练算法并对算法的准确值准确率进行估计 #导入相应模块 import numpy as npimport pandas as pdimport matplotlib.pyplot as plt%mat ...
- 机器学习回顾篇(6):KNN算法
1 引言 本文将从算法原理出发,展开介绍KNN算法,并结合机器学习中常用的Iris数据集通过代码实例演示KNN算法用法和实现. 2 算法原理 KNN(kNN,k-NearestNeighbor)算法, ...
- KNN算法介绍及源码实现
一.KNN算法介绍 邻近算法,或者说K最邻近(KNN,K-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是K个最近的邻居的意思,说的是每个样本都可以用它 ...
- 利用Python实现kNN算法
邻近算法(k-NearestNeighbor) 是机器学习中的一种分类(classification)算法,也是机器学习中最简单的算法之一了.虽然很简单,但在解决特定问题时却能发挥很好的效果.因此,学 ...
随机推荐
- 第一次JVM分析记录:Out of Memory Error (workgroup.cpp:96), pid=6196, tid=139999645685504
tomcat的catalina.out日志报错如下: Exception in thread "http-bio-8081-Acceptor-0" java.lang.OutOfM ...
- 关于linux上postgresql的一些理解
刚开始接触postgresql,安装后就有一个默认用户postgres,而且在启动postgresql后只能通过切换到linux的postgres用户才能登录数据库进行操作,和Mysql的登录认证居然 ...
- Sql Server 复制数据库
确实很实用 https://www.cnblogs.com/ggll611928/p/7451558.html
- Spring boot 配置文件详解 (properties 和yml )
从其他框架来看 我们都有自己的配置文件, hibernate有hbm,mybatis 有properties, 同样, Spring boot 也有全局配置文件. Springboot使用一个全局的配 ...
- CAP 2.5 版本中的新特性
前言 首先,恭喜 CAP 已经成为 eShopOnContainers 官方推荐的生产环境可用的 EventBus 之一. 自从上次 CAP 2.4 版本发布 以来,已经过去了几个月的时间,关注的朋友 ...
- Tampermonkey还你一个干净整洁的上网体验
作为一个前端开发,平时难免要经常浏览一些博客.技术网站,学习新的技术或者寻找解决方案,可能更多是ctrl+c和ctrl+v(^_^|||),但是目前很多网站的布局以及广告对于我们阅读文章造成了很多的障 ...
- 跟我一起学opencv 第二课之图像的掩膜操作
1.掩膜(mask)概念 用选定的图像,图形或物体,对处理的图像(全部或局部)进行遮挡,来控制图像处理的区域或处理过程.用于覆盖的特定图像或物体称为掩模或模板.光学图像处理中,掩模可以足胶片,滤光片等 ...
- springcloud~配置中心实例搭建
server端 build.gradle相关 dependencies { compile('org.springframework.cloud:spring-cloud-config-server' ...
- python学习第四讲,python基础语法之判断语句,循环语句
目录 python学习第四讲,python基础语法之判断语句,选择语句,循环语句 一丶判断语句 if 1.if 语法 2. if else 语法 3. if 进阶 if elif else 二丶运算符 ...
- Spring学习(二):Spring支持的5种Bean Scope
序言 Scope是定义Spring如何创建bean的实例的.Spring容器最初提供了两种bean的scope类型:singleton和prototype,但发布2.0以后,又引入了另外三种scope ...