为什么L1稀疏,L2平滑?
使用机器学习方法解决实际问题时,我们通常要用L1或L2范数做正则化(regularization),从而限制权值大小,减少过拟合风险。特别是在使用梯度下降来做目标函数优化时,很常见的说法是, L1正则化产生稀疏的权值, L2正则化产生平滑的权值。为什么会这样?这里面的本质原因是什么呢?下面我们从两个角度来解释这个问题。
角度一:数学公式
这个角度从权值的更新公式来看权值的收敛结果。
首先来看看L1和L2的梯度(导数的反方向):
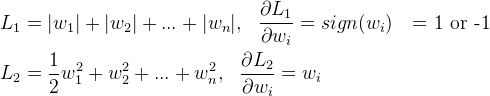
所以(不失一般性,我们假定:wi等于不为0的某个正的浮点数,学习速率η 为0.5):
L1的权值更新公式为wi = wi - η * 1 = wi - 0.5 * 1,也就是说权值每次更新都固定减少一个特定的值(比如0.5),那么经过若干次迭代之后,权值就有可能减少到0。
L2的权值更新公式为wi = wi - η * wi = wi - 0.5 * wi,也就是说权值每次都等于上一次的1/2,那么,虽然权值不断变小,但是因为每次都等于上一次的一半,所以很快会收敛到较小的值但不为0。
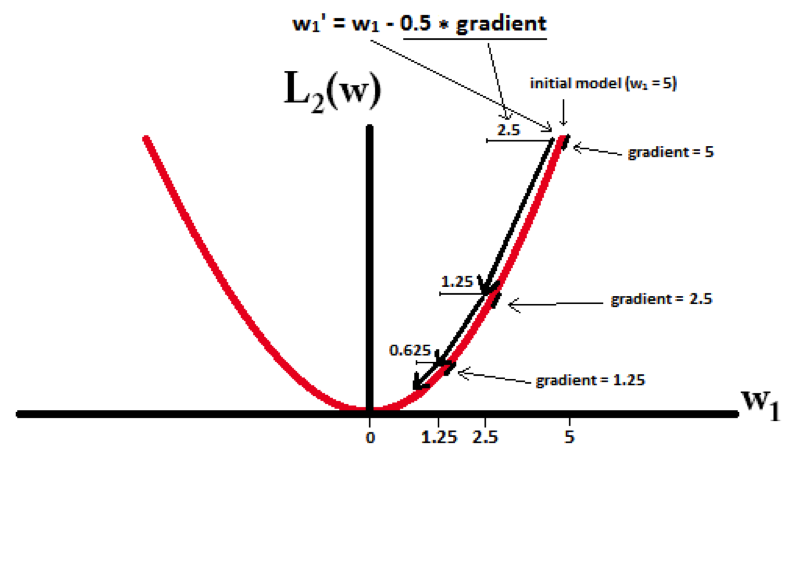
下面的图很直观的说明了这个变化趋势:
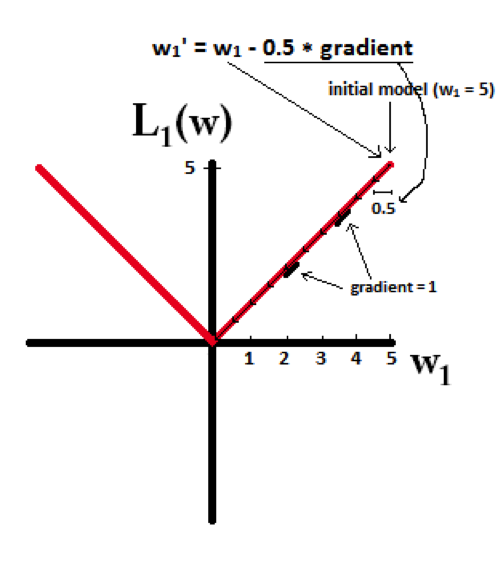
L1能产生等于0的权值,即能够剔除某些特征在模型中的作用(特征选择),即产生稀疏的效果。
L2可以得迅速得到比较小的权值,但是难以收敛到0,所以产生的不是稀疏而是平滑的效果。
角度二:几何空间
这个角度从几何位置关系来看权值的取值情况。
直接来看下面这张图:
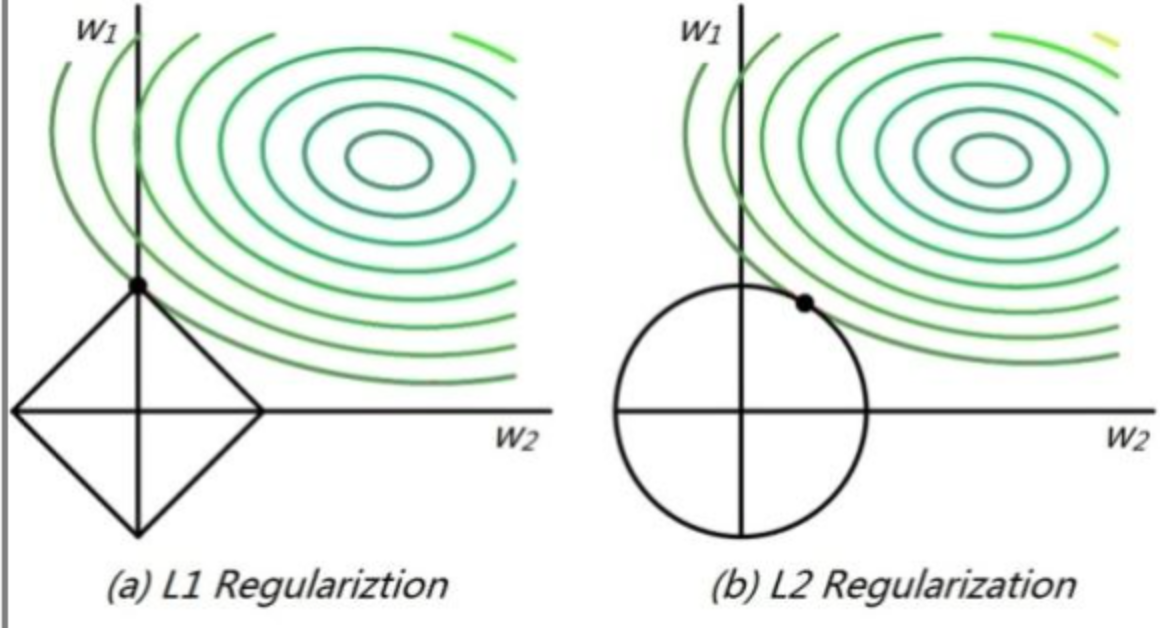
高维我们无法想象,简化到2维的情形,如上图所示。其中,左边是L1图示,右边是L2图示,左边的方形线上是L1中w1/w2取值区间,右边得圆形线上是L2中w1/w2的取值区间,绿色的圆圈表示w1/w2取不同值时整个正则化项的值的等高线(凸函数),从等高线和w1/w2取值区间的交点可以看到,L1中两个权值倾向于一个较大另一个为0,L2中两个权值倾向于均为非零的较小数。这也就是L1稀疏,L2平滑的效果。
文章地址: https://vimsky.com/article/969.html
为什么L1稀疏,L2平滑?的更多相关文章
- L1、L2范式及稀疏性约束
L1.L2范式及稀疏性约束 假设需要求解的目标函数为: E(x) = f(x) + r(x) 其中f(x)为损失函数,用来评价模型训练损失,必须是任意的可微凸函数,r(x)为规范化约束因子,用来对模型 ...
- L1比L2更稀疏
1. 简单列子: 一个损失函数L与参数x的关系表示为: 则 加上L2正则化,新的损失函数L为:(蓝线) 最优点在黄点处,x的绝对值减少了,但依然非零. 如果加上L1正则化,新的损失函数L为:(粉线) ...
- paper 126:[转载] 机器学习中的范数规则化之(一)L0、L1与L2范数
机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http://blog.csdn.net/zouxy09 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
- 机器学习中的范数规则化之(一)L0、L1与L2范数(转)
http://blog.csdn.net/zouxy09/article/details/24971995 机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http: ...
- L0、L1与L2范数、核范数(转)
L0.L1与L2范数.核范数 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化.我们先简单的来理解下常用的L0.L1.L2和核范数规则化.最后聊下规则化项参数的选择问题.这里因为篇幅比较庞大 ...
- 机器学习中的范数规则化之(一)L0、L1与L2范数 非常好,必看
机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http://blog.csdn.net/zouxy09 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
- 机器学习中的范数规则化-L0,L1和L2范式(转载)
机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http://blog.csdn.net/zouxy09 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
- L1与L2正则(转)
概念: L0范数表示向量中非零元素的个数:NP问题,但可以用L1近似代替. L1范数表示向量中每个元素绝对值的和: L1范数的解通常是稀疏性的,倾向于选择:1. 数目较少的一些非常大的值 2. 数目 ...
- L1 与 L2 正则化
参考这篇文章: https://baijiahao.baidu.com/s?id=1621054167310242353&wfr=spider&for=pc https://blog. ...
随机推荐
- cf831D(dp)
题目链接: http://codeforces.com/contest/831/problem/D 题意: 有 n 个人和 k 把钥匙, 数组 a 为 n 个人的初始位置, 数组 b 为 k 把钥匙的 ...
- Eclipse中导入项目的方法
在Eclipse导入其他项目时,可能由于开发软件.JDK版本.Tomcat服务器版本的不同等多种原因,造成项目报错的问题 可以通过以下步骤解决: 1.在Project Explorer面板下,右键— ...
- SpringMVC 思想介绍
MVC 思想简介 博客园好像不支持发布markdown的时序图, 如果你会markdown并且不太熟悉Springmvc执行流程, 照着图在Markdown上面敲一遍执行流程,这是我经历过的最快的记忆 ...
- vue使用webpack压缩后体积过大要怎么优化
vue使用webPack压缩后存储过大,怎么优化 在生产环境去除developtool选项 在webpack.config.js中设置的developtool选项,仅适用于开发环境,这样会造成打包成的 ...
- 文本处理三剑客之gawk
gawk 作者:Aho, Weinberger, Kernighan 版本: GNU awk:gawk New awk:nawk 简介:格式化文本输出工具,模式扫描及处理语言:报告生成器. 用法:ga ...
- 洛谷P3384【模板】树链剖分
题目描述 如题,已知一棵包含\(N\)个结点的树(连通且无环),每个节点上包含一个数值,需要支持以下操作: 操作\(1\): 格式: \(1\) \(x\) \(y\) \(z\) 表示将树从\(x\ ...
- Oracle插入中文数据乱码 设置服务器编码和客户端编码一致
- MacOS下,Python2和Python3完美兼容使用(转)
问题阐述: MacOS默认Python版本是2.7.10,随着Python3的进一步占有市场,Python2.7也将在2020年结束维护,所以在同一台电脑上安装多个Python版本势在必行. 一.py ...
- 求最短路径(Bellman-Ford算法与Dijkstra算法)
前言 Dijkstra算法是处理单源最短路径的有效算法,但它局限于边的权值非负的情况,若图中出现权值为负的边,Dijkstra算法就会失效,求出的最短路径就可能是错的.这时候,就需要使用其他的算法来求 ...
- Python+Selenium----使用HTMLTestRunner.py生成自动化测试报告2(使用PyCharm )
1.说明 在我前一篇文件(Python+Selenium----使用HTMLTestRunner.py生成自动化测试报告1(使用IDLE ))中简单的写明了,如何生产测试报告,但是使用IDLE很麻烦, ...