Elasticsearch+Logstash+Kibana搭建分布式日志平台
一、前言
编译安装
1、ELK简介
下载相关安装包地址:https://www.elastic.co/cn/downloads
ELK是Elasticsearch+Logstash+Kibana的简称
ElasticSearch是一个基于Lucene的分布式全文搜索引擎,提供 RESTful API进行数据读写
Logstash是一个收集,处理和转发事件和日志消息的工具
- Kibana是Elasticsearch的开源数据可视化插件,为查看存储在ElasticSearch提供了友好的Web界面,并提供了条形图,线条和散点图,饼图和地图等分析工具
总的来说,ElasticSearch负责存储数据,Logstash负责收集日志,并将日志格式化后写入ElasticSearch,Kibana提供可视化访问ElasticSearch数据的功能。
2、ELK工作流
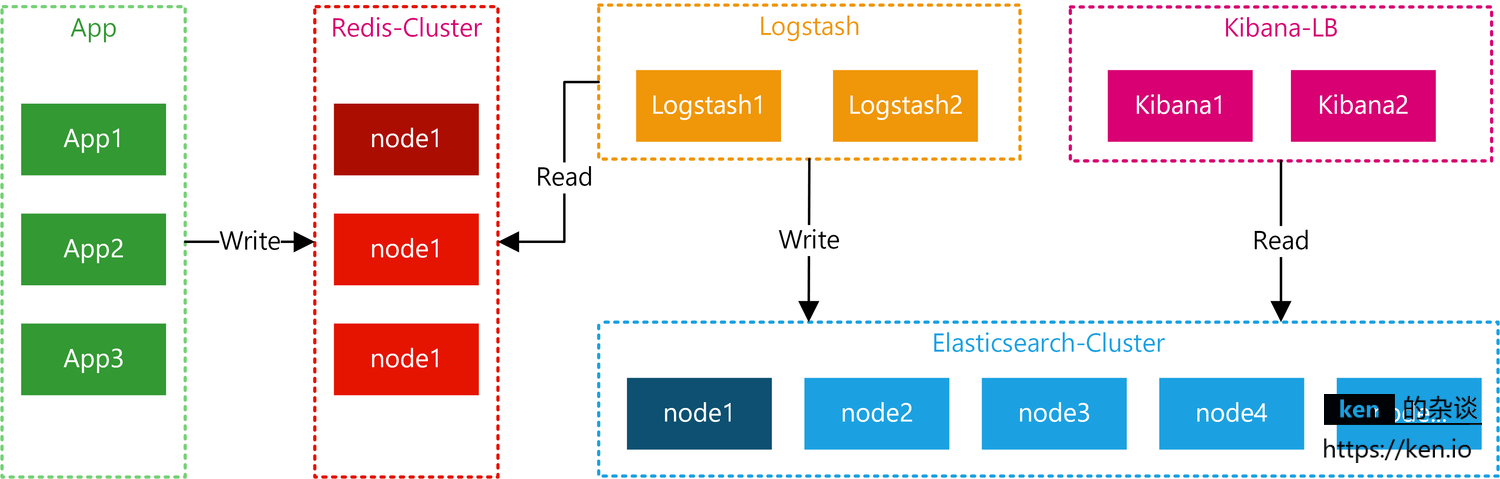
应用将日志按照约定的Key写入Redis,Logstash从Redis中读取日志信息写入ElasticSearch集群。Kibana读取ElasticSearch中的日志,并在Web页面中以表格/图表的形式展示。
二、准备工作
1、服务器&软件环境说明
- 服务器
一共准备3台CentOS7 Server
| 服务器名 | IP | 说明 |
|---|---|---|
| es1 | 192.168.1.31 | 部署ElasticSearch主节点 |
| es2 | 192.168.1.32 | 部署ElasticSearch从节点 |
| elk | 192.168.1.21 | 部署Logstash + Kibana + Redis |
这里为了节省,只部署2台Elasticsearch,并将Logstash + Kibana + Redis部署在了一台机器上。
如果在生产环境部署,可以按照自己的需求调整。
- 软件环境
| 项 | 说明 |
|---|---|
| Linux Server | CentOS 7 |
| Elasticsearch | 7.0.1 |
| Logstash | 7.0.1 |
| Kibana | 7.0.1 |
| Redis | 4.0 |
| JDK | 1.8 |
2、ELK环境准备
由于Elasticsearch、Logstash、Kibana均不能以root账号运行。
但是Linux对非root账号可并发操作的文件、线程都有限制。
所以,部署ELK相关的机器都要调整:
- 修改文件限制
# 修改系统文件
vi /etc/security/limits.conf
#增加的内容
* soft nofile 65536
* hard nofile 65536
* soft nproc 2048
* hard nproc 4096
- 调整进程数
#修改系统文件
vi /etc/security/limits.d/20-nproc.conf
#调整成以下配置
* soft nproc 4096
root soft nproc unlimited
- 调整虚拟内存&最大并发连接
#修改系统文件
vi /etc/sysctl.conf
#增加的内容
vm.max_map_count=655360
fs.file-max=655360
以上操作重启系统后生效
reboot
- JDK8安装
CentO安装JDK8:https://ken.io/note/centos-java-setup
- 创建ELK专用用户
useradd elk
su elk- 创建ELK相关目录并赋权
#创建ELK 数据目录
mkdir /home/elsearch/data
#创建ELK 日志目录
mkdir /home/elsearch/logs #更改目录Owner
chown -R elk:elk/home/elsearch/data
chown -R elk:elk/home/elsearch/logs
- 下载ELK包并解压
https://www.elastic.co/downloads
#打开文件夹
cd /home/download
#下载
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.0.1.tar.gz
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.0.1.tar.gz
wget wget https://artifacts.elastic.co/downloads/kibana/kibana-7.0.1-linux-x86_64.tar.gz
#解压
tar -zvxf elasticsearch-7.0.1.tar.gz
tar -zvxf logstash-7.0.1.tar.gz
tar -zvxf kibana-7.0.1-linux-x86_64.tar.gz
三、Elasticsearch 部署
本次一共要部署两个Elasticsearch节点,所有文中没有指定机器的操作都表示每个Elasticsearch机器都要执行该操作
1、准备工作
- 移动Elasticsearch到统一目录
#移动目录
mv /home/download/elasticsearch-7.0.1 /usr/elk
#赋权
chown -R elk:elk /usr/elk/elasticsearch-7.0.1/
- 开放端口
#增加端口
firewall-cmd --add-port=9200/tcp --permanent
firewall-cmd --add-port=9300/tcp --permanent
#重新加载防火墙规则
firewall-cmd --reload
2、Elasticsearch节点配置
- 修改配置
#打开目录
cd /usr/elk/elasticsearch-7.0.1
#修改配置
vi config/elasticsearch.yml
- 主节点配置(192.168.1.31)
cluster.name: es
node.name: es1
path.data: /elk/es/data
path.logs: /elk/es/logs
network.host: 192.168.1.31
http.port: 9200
transport.tcp.port: 9300
node.master: true
node.data: true
discovery.zen.ping.unicast.hosts: ["192.168.1.31:9300","192.168.1.32:9300"]
discovery.zen.minimum_master_nodes: 1
- 从节点配置(192.168.1.32)
cluster.name: es
node.name: es2
path.data: /elk/es/data
path.logs: /elk/es/logs
network.host: 192.168.1.32
http.port: 9200
transport.tcp.port: 9300
node.master: false
node.data: true
discovery.zen.ping.unicast.hosts: ["192.168.1.31:9300","192.168.1.32:9300"]
discovery.zen.minimum_master_nodes: 1
- 配置项说明
| 项 | 说明 |
|---|---|
cluster.name |
集群名 |
node.name |
节点名 |
| path.data | 数据保存目录 |
| path.logs | 日志保存目录 |
| network.host | 节点host/ip |
| http.port | HTTP访问端口 |
| transport.tcp.port | TCP传输端口 |
| node.master | 是否允许作为主节点 |
| node.data | 是否保存数据 |
| discovery.zen.ping.unicast.hosts | 集群中的主节点的初始列表,当节点(主节点或者数据节点)启动时使用这个列表进行探测 |
| discovery.zen.minimum_master_nodes | 主节点个数 |
3、Elasticsearch启动&健康检查
- 启动
#进入elasticsearch根目录
cd /usr/elk/elasticsearch-7.0.1
#启动
./bin/elasticsearch
- 查看健康状态
curl http://192.168.1.31:9200/_cluster/health
如果返回status=green表示正常
{
"cluster_name": "esc",
"status": "green",
"timed_out": false,
"number_of_nodes": 2,
"number_of_data_nodes": 2,
"active_primary_shards": 0,
"active_shards": 0,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100.0
}
四、Logstash 部署
1、准备工作
- 部署Redis
Redis4 安装与配置:https://ken.io/note/centos7-redis4-setup
由于本次核心是ELK搭建,所以ken.io偷懒,Redis没有部署集群,采用的单节点。
- 移动Logstash到统一目录
#移动目录
mv /home/download/logstash-6.0.0 /usr/elk
#赋权
chown -R elk:elk /usr/elk/logstash-6.0.0/
- 切换账号
#账号切换到 elk
su - elk
- 数据&日志目录
#创建Logstash主目录
mkdir /elk/logstash
#创建Logstash数据目录
mkdir /elk/logstash/data
#创建Logstash日志目录
mkdir /elk/logstash/logs
2、Logstash配置
- 配置数据&日志目录
#打开目录
cd /usr/elk/logstash-6.0.0
#修改配置
vi config/logstash.yml
#增加以下内容
path.data: /elk/logstash/data
path.logs: /elk/logstash/logs
- 配置Redis&Elasticsearch
vi config/input-output.conf
#配置内容
input {
redis {
data_type => "list"
key => "logstash"
host => "192.168.1.21"
port => 6379
threads => 5
codec => "json"
}
}
filter {
}
output {
elasticsearch {
hosts => ["192.168.1.31:9200","192.168.1.32:9200"]
index => "logstash-%{type}-%{+YYYY.MM.dd}"
document_type => "%{type}"
}
stdout {
}
}
该配置就是从redis中读取数据,然后写入指定的elasticsearch
Redis核心配置项说明:
| 配置项 | 说明 |
|---|---|
| data_type => “list” | 数据类型为list |
| key => “logstash” | 缓存key为:logstash |
| codec => “json” | 数据格式为:json |
- root用户启动
#进入Logstash根目录
cd /usr/elk/logstash-6.0.0
#启动
./bin/logstash -f config/input-output.conf
启动成功后,在启动输出的最后一行会看到如下信息:
[INFO ][logstash.pipeline ] Pipeline started {"pipeline.id"=>"main"}
[INFO ][logstash.agent ] Pipelines running {:count=>1, :pipelines=>["main"]}
五、Kibana 部署
1、准备工作
- 移动Kibana到统一目录
#移动目录
mv /home/download/kibana-6.0.0-linux-x86_64 /usr/elk/kibana-7.0.1
#赋权
chown -R elk:elk /usr/elk/kibana-7.0.1/
- 开放端口
#增加端口
firewall-cmd --add-port=5601/tcp --permanent
#重新加载防火墙规则
firewall-cmd --reload
- 切换账号
#账号切换到 elk
su - elk
3、Kibana配置与访问测试
- 修改配置
#进入kibana-6.0.0根目录
cd /usr/elk/kibana-7.0.1
#修改配置
vi config/kibana.yml
#增加以下内容
server.port: 5601
server.host: "192.168.1.21"
elasticsearch.hosts: '["http://192.168.1.31:9200"]'
- 启动
#进入kibana-7.0.1根目录
cd /usr/elk/kibana-7.0.1
#启动
./bin/kibana
- 访问
浏览器访问: 192.168.1.21:5601
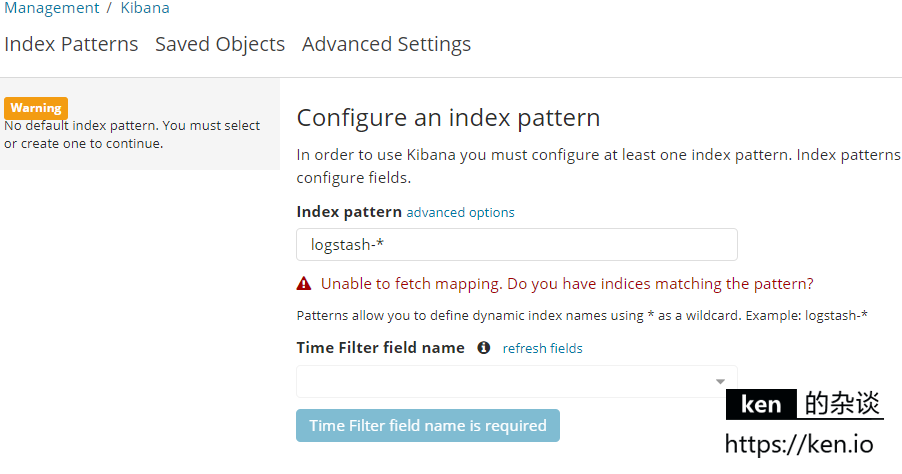
警告提示:No default index pattern. You must select or create one to continue.
错误提示:Unable to fetch mapping. do you have indices matching the pattern?
不用担心,这是因为还没有写入日志
六、测试
1、日志写入
日历写入的话,写入到logstash监听的redis即可。
数据类型之前在/usr/elk/logstash-7.0.1/config/input-uput.conf中有配置
- redis命令方式
#启动redis客户端
#执行以下命令
lpush logstash '{"host":"127.0.0.1","type":"logtest","message":"hello"}'
- Java代码批量写入(引入Jedis)
Jedis jedis = new Jedis("192.168.1.21", 6379);
for (int i = 0; i < 1000; i++) {
jedis.lpush("logstash", "{\"host\":\"127.0.0.1\",\"type\":\"logtest\",\"message\":\"" + i + "\"}");
}
2、Kibana使用
浏览器访问:192.168.1.21:5601
此时会提示: Configure an index pattern
直接点击create即可
浏览器访问:192.168.1.21:5601/app/kibana#/discover 即可查看日志
大功告成!
七、备注
1、Kibana使用教程
2、 ELK开机启动
ELK开机启动,需要学习下以下知识
- nohup命令使用:https://www.ibm.com/developerworks/cn/linux/l-cn-nohup/index.html
- 自定义系统服务,可以参考Redis的开机启动:https://ken.io/note/centos7-redis4-setup
Elasticsearch+Logstash+Kibana搭建分布式日志平台的更多相关文章
- ELK6.0部署:Elasticsearch+Logstash+Kibana搭建分布式日志平台
一.前言 1.ELK简介 ELK是Elasticsearch+Logstash+Kibana的简称 ElasticSearch是一个基于Lucene的分布式全文搜索引擎,提供 RESTful API进 ...
- 用ElasticSearch,LogStash,Kibana搭建实时日志收集系统
用ElasticSearch,LogStash,Kibana搭建实时日志收集系统 介绍 这套系统,logstash负责收集处理日志文件内容存储到elasticsearch搜索引擎数据库中.kibana ...
- 【转】ELK(ElasticSearch, Logstash, Kibana)搭建实时日志分析平台
[转自]https://my.oschina.net/itblog/blog/547250 摘要: 前段时间研究的Log4j+Kafka中,有人建议把Kafka收集到的日志存放于ES(ElasticS ...
- 【Big Data - ELK】ELK(ElasticSearch, Logstash, Kibana)搭建实时日志分析平台
摘要: 前段时间研究的Log4j+Kafka中,有人建议把Kafka收集到的日志存放于ES(ElasticSearch,一款基于Apache Lucene的开源分布式搜索引擎)中便于查找和分析,在研究 ...
- ELK(ElasticSearch+Logstash+ Kibana)搭建实时日志分析平台
一.简介 ELK 由三部分组成elasticsearch.logstash.kibana,elasticsearch是一个近似实时的搜索平台,它让你以前所未有的速度处理大数据成为可能. Elastic ...
- [Big Data - ELK] ELK(ElasticSearch, Logstash, Kibana)搭建实时日志分析平台
ELK平台介绍 在搜索ELK资料的时候,发现这篇文章比较好,于是摘抄一小段: 以下内容来自: http://baidu.blog.51cto.com/71938/1676798 日志主要包括系统日志. ...
- ELK( ElasticSearch+ Logstash+ Kibana)分布式日志系统部署文档
开始在公司实施的小应用,慢慢完善之~~~~~~~~文档制作 了好作运维同事之间的前期普及.. ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 软件下载地址: https://www.e ...
- 13: ELK(ElasticSearch+Logstash+ Kibana)搭建实时日志分析平台
参考博客:https://www.cnblogs.com/zclzhao/p/5749736.html 51cto课程:https://edu.51cto.com/center/course/less ...
- 从头开始搭建分布式日志平台的docker环境
上篇(spring mvc+ELK从头开始搭建日志平台)分享了从头开始搭建基于spring mvc+redis+logback+logstash+elasticsearch+kibana的分布式日志平 ...
随机推荐
- HTML5坦克大战
在JavaScript中,不要在变量为定义之前去使用,这样很难察觉并且无法运行. 颜色不对. 当我的坦克移动时,敌人坦克消失. tankGame3.html <!DOCTYPE html> ...
- 数据结构C语言版干货------->线性表之顺序表
一:头文件定义 /*************************************************************************** *项目 数据结构 *概要 逻辑 ...
- IIS 高并发导致log记录不完全
项目测试性能过程中,对于高并发测试过程中发现log记录缺失一部分,经过调查,找到了原因是因为IIS连接数的限制,经过修改连接数,成功完成.设置如下: “点击网站”->“右击切换到功能视图”-&g ...
- kylin_学习_01_kylin安装部署
一.环境准备 根据官方文档,kylin是需要运行在hadoop环境下的,如下图: 1.hadoop环境搭建 参考:hadoop_学习_02_Hadoop环境搭建(单机) 2.hbase环境搭建 参考: ...
- Mybatis学习--Mapper XML文件
学习笔记,选自Mybatis官方中文文档:http://www.mybatis.org/mybatis-3/zh/sqlmap-xml.html#insert_update_and_delete My ...
- POJ1422 Air Raid 和 CH6902 Vani和Cl2捉迷藏
Air Raid Language:Default Air Raid Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 9547 A ...
- bzoj 1312: Hard Life 01分数规划+网络流
题目: Description 在一家公司中,人事部经理与业务部经理不和.一次,总经理要求人事部从公司的职员中挑选出一些来帮助业务部经理完成一项任务.人事部经理发现,在公司的所有职员中,有一些人相处得 ...
- vi查找替换命令详解
一.查找 查找命令 /pattern<Enter> :向下查找pattern匹配字符串 ?pattern<Enter>:向上查找pattern匹配字符串 使用了查找命令之后,使 ...
- node包管理工具nvm
去NVM官网下载NVM压缩包,下载nvm-setup.zip,直接傻瓜式安装 安装成功后运行命令: nvm -v 常用命令: nvm install <version> ## 安装指定版本 ...
- linux日常管理-xarge_exec
在find搜索到文件之后再进行操作 exec是find的一个选项. {}表示前面搜索到的结果,\:是exec特殊的用法. xarge拥有同样的功能,需用选项 -i 可以用在其他命令的后面