第八次作业:聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
import numpy as np
x = np.random.randint(1,100,[20,1])
y = np.zeros(20)
k = 3
def initcenter(x,k):
return x[:k] kc = initcenter(x,k)
kc
def nearest(kc,i):
d=(abs(kc-i))
w=np.where(d==np.min(d))
return w[0][0] kc = initcenter(x,k)
nearest(kc,56)
def xclassify(x,y,kc):
for i in range(x.shape[0]):
y[i] = nearest(kc,x[i])
return y kc = initcenter(x,k)
y = xclassify(x,y,kc)
print(kc,y)
def kcmean(x,y,kc,k):
l = list(kc)
flag = False
for c in range(k):
m = np.where(y == c)
n = np.mean(x[m])
if l[c] != n:
l[c] = n
flag = True
print(l,flag)
return (np.array(l),flag) kc = initcenter(x,k)
flag = True
k = 3 while flag:
y = xclassify(x,y,kc)
kc,flag = kcmean(x,y,kc,k)
运行结果

二.鸢尾花花瓣长度数据做聚类并用散点图显示
import numpy as np
from sklearn.datasets import load_iris
iris = load_iris()
x = iris.data[:,1]
y = np.zeros(150) def initcenter(x,k): #初始聚类中心数组
return x[0:k].reshape(k) def nearest(kc,i): #数组中的值,与聚类中心最小距离所在类别的索引号
d = (abs(kc-i))
w = np.where(d == np.min(d))
return w[0][0] def xclassify(x,y,kc):
for i in range(x.shape[0]): #对数组的每个值进行分类,shape[0]读取矩阵第一维度的长度
y[i] = nearest(kc,x[i])
return y def kcmean(x,y,kc,k): #计算各聚类新均值
l = list(kc)
flag = False
for c in range(k):
print(c)
m = np.where(y == c)
n=np.mean(x[m])
if l[c] != n:
l[c] = n
flag = True #聚类中心发生变化
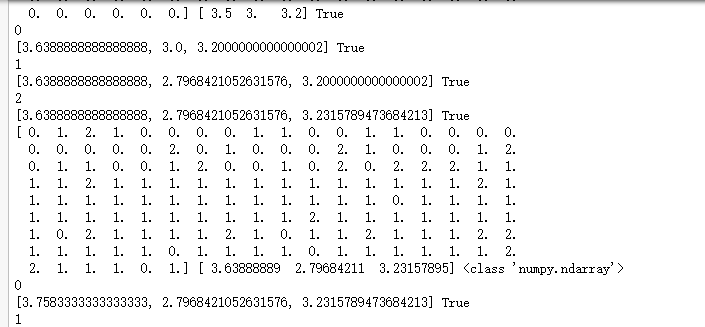
print(l,flag)
return (np.array(l),flag) k = 3
kc = initcenter(x,k) flag = True
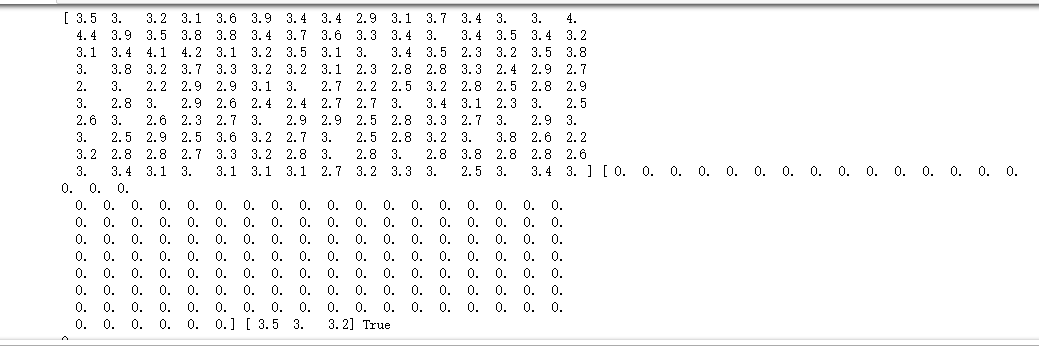
print(x,y,kc,flag) #判断聚类中心和目标函数的值是否发生改变,若不变,则输出结果,若改变,则返回2
while flag:
y = xclassify(x,y,kc)
kc, flag = kcmean(x,y,kc,k)
print(y,kc,type(kc)) print(x,y)
import matplotlib.pyplot as plt
plt.scatter(x,x,c=y,s=50,cmap="rainbow");
plt.show()
运行结果


第八次作业:聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用的更多相关文章
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
- 聚类--K均值算法
import numpy as np from sklearn.datasets import load_iris iris = load_iris() x = iris.data[:,1] y = ...
- K 均值算法-如何让数据自动分组
公号:码农充电站pro 主页:https://codeshellme.github.io 之前介绍到的一些机器学习算法都是监督学习算法.所谓监督学习,就是既有特征数据,又有目标数据. 而本篇文章要介绍 ...
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 机器学习之K均值算法(K-means)聚类
K均值算法(K-means)聚类 [关键词]K个种子,均值 一.K-means算法原理 聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中. K-Means算法是一种聚类分析 ...
- 一句话总结K均值算法
一句话总结K均值算法 核心:把样本分配到离它最近的类中心所属的类,类中心由属于这个类的所有样本确定. k均值算法是一种无监督的聚类算法.算法将每个样本分配到离它最近的那个类中心所代表的类,而类中心的确 ...
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- Bisecting KMeans (二分K均值)算法讲解及实现
算法原理 由于传统的KMeans算法的聚类结果易受到初始聚类中心点选择的影响,因此在传统的KMeans算法的基础上进行算法改进,对初始中心点选取比较严格,各中心点的距离较远,这就避免了初始聚类中心会选 ...
- KMeans (K均值)算法讲解及实现
算法原理 KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标 ...
随机推荐
- 51nod1363 最小公倍数之和
题目描述 给出一个n,求1-n这n个数,同n的最小公倍数的和. 例如:n = 6,1,2,3,4,5,6 同6的最小公倍数分别为6,6,6,12,30,6,加在一起 = 66. 由于结果很大,输出Mo ...
- python 画广东省等压线图
最近开发时要实现一个业务逻辑: 调用中国气象数据网API接口获取广东省实时气象数据 根据数据,基于广东省地图渲染等压线图 最终效果图是这样的: 首先是获取实时气压数据,由于中国气象数据网每次只能获得3 ...
- “妄”眼欲穿-CSS之flex布局和边框阴影
妄:狂妄: 不会的东西只有怀着一颗狂妄的心,假装能把它看穿吧. 作为一个什么都不会的小白,为了学习(zb),特别在拿来主义之后写一些对于某些css布局的总结,进一步加深对知识的记忆.知识是人类的共同财 ...
- windows 根据端口查看进行PID 并杀掉进程
1. 首先用netstat -ano | find “端口号”查出进程号 明明有端口号是17568和18892, 如何确定是17568呢 2. takslist 查询当前的进行 3. 如何杀死进程呢 ...
- MVC基本登陆与验证码功能实现
一.基本登陆实现与验证码功能实现,该功能是和spring.net功能集合使用的,因为后面要用到验证是否处于登陆状态 1. 先构建一个登陆页面 @{ Layout = null; } <!DOCT ...
- 网站性能测试工具 webbench 的安装和使用
1.webbench的下载和安装 wget http://home.tiscali.cz/~cz210552/distfiles/webbench-1.5.tar.gz sudo tar xvf we ...
- NGS概念大科普(转)
NGS又称为下一代测序技术,高通量测序技术 以高输出量和高解析度为主要特色,能一次并行对几十万到几百万条DNA分子进行序列读取,在提供丰富的遗传学信息的同时,还可大大降低测序费用.缩短测序时间的测序技 ...
- rocketMQ No route info of this topic 错误
最近在使用rocketmq 发送消息,出现了No route info of this topic 异常,但奇怪的是我的其它的服务都可以成功发送,唯有crs服务不能成功发送,在网上搜索的解决方式基本上 ...
- 现代 PHP 新特性 —— Zend Opcache (转)
转自:https://laravelacademy.org/post/4396.html 1.概述 字节码缓存不是PHP的新特性,有很多独立的扩展可以实现,比如APC.eAccelerator和Xac ...
- ubuntu 安装nginx, 出现 Unable to locate package
今天在初始化一台新的ubuntu 服务器时,敲上了 sudo apt-get install nginx 来安装nginx, 却发现提示: Reading package lists... Done ...