L1正则化和L2正则化

L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
一、L1正则化
1、L1正则化
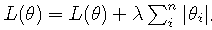
需注意,L1 正则化除了和L2正则化一样可以约束数量级外,L1正则化还能起到使参数更加稀疏的作用,稀疏化的结果使优化后的参数一部分为0,另一部分为非零实值。非零实值的那部分参数可起到选择重要参数或特征维度的作用,同时可起到去除噪声的效果。此外,L1正则化和L2正则化可以联合使用:
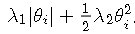
这种形式也被称为“Elastic网络正则化”。
L1相比于L2,有所不同:
- L1减少的是一个常量,L2减少的是权重的固定比例
- 孰快孰慢取决于权重本身的大小,权重刚大时可能L2快,较小时L1快
- L1使权重稀疏,L2使权重平滑,一句话总结就是:L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0
实践中L2正则化通常优于L1正则化。
2、为什么要生成稀疏矩阵?
上面提到L1正则化有助于生成一个稀疏权值矩阵,进而可以用于特征选择。为什么要生成一个稀疏矩阵?
稀疏矩阵指的是很多元素为0,只有少数元素是非零值的矩阵,即得到的线性回归模型的大部分系数都是0. 通常机器学习中特征数量很多,例如文本处理时,如果将一个词组(term)作为一个特征,那么特征数量会达到上万个(bigram)。在预测或分类时,那么多特征显然难以选择,但是如果代入这些特征得到的模型是一个稀疏模型,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,或者贡献微小(因为它们前面的系数是0或者是很小的值,即使去掉对模型也没有什么影响),此时我们就可以只关注系数是非零值的特征。这就是稀疏模型与特征选择的关系。
3、L1正则化和特征选择
假设有如下带L1正则化的损失函数:
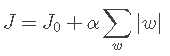


4.L1针对不可导的正则项如何解决?
【Lasso回归使用L1正则,这个问题可以看做是求解Lasso回归的L1】
Lasso回归使得一些系数变小,甚至还是一些绝对值较小的系数直接变为0,因此特别适用于参数数目缩减与参数的选择,因而用来估计稀疏参数的线性模型。但是Lasso回归有一个很大的问题,导致我们需要把它单独拎出来讲,就是它的损失函数不是连续可导的,由于L1范数用的是绝对值之和,导致损失函数有不可导的点。也就是说,我们的最小二乘法,梯度下降法,牛顿法与拟牛顿法对它统统失效了。那我们怎么才能求有这个L1范数的损失函数极小值呢?
两种全新的求极值解法坐标轴下降法(coordinate descent)和最小角回归法( Least Angle Regression, LARS)该隆重出场了。
(1)坐标轴下降法
坐标轴下降法顾名思义,是沿着坐标轴的方向去下降,这和梯度下降不同。梯度下降是沿着梯度的负方向下降。不过梯度下降和坐标轴下降的共性就都是迭代法,通过启发式的方式一步步迭代求解函数的最小值。

于是我们的优化目标就是在θ的n个坐标轴上(或者说向量的方向上)对损失函数做迭代的下降,当所有的坐标轴上的θi(i = 1,2,...n)都达到收敛时,我们的损失函数最小,此时的θ即为我们要求的结果。

以上就是坐标轴下降法的求极值过程,可以和梯度下降做一个比较:
- a) 坐标轴下降法在每次迭代中在当前点处沿一个坐标方向进行一维搜索 ,固定其他的坐标方向,找到一个函数的局部极小值。而梯度下降总是沿着梯度的负方向求函数的局部最小值。
- b) 坐标轴下降优化方法是一种非梯度优化算法。在整个过程中依次循环使用不同的坐标方向进行迭代,一个周期的一维搜索迭代过程相当于一个梯度下降的迭代。
- c) 梯度下降是利用目标函数的导数来确定搜索方向的,该梯度方向可能不与任何坐标轴平行。而坐标轴下降法法是利用当前坐标方向进行搜索,不需要求目标函数的导数,只按照某一坐标方向进行搜索最小值。
- d) 两者都是迭代方法,且每一轮迭代,都需要O(mn)的计算量(m为样本数,n为系数向量的维度)
(2)最小角回归法
最小角回归法对前向梯度算法和前向选择算法做了折中,保留了前向梯度算法一定程度的精确性,同时简化了前向梯度算法一步步迭代的过程。具体算法是这样的: 、

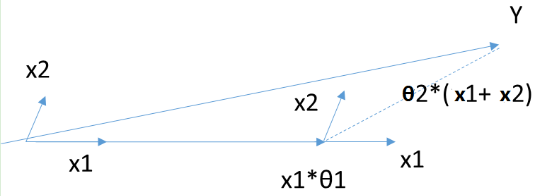
最小角回归法是一个适用于高维数据的回归算法,其主要的优点有:
- 特别适合于特征维度n 远高于样本数m的情况。
- 算法的最坏计算复杂度和最小二乘法类似,但是其计算速度几乎和前向选择算法一样
- 可以产生分段线性结果的完整路径,这在模型的交叉验证中极为有用
主要的缺点是:由于LARS的迭代方向是根据目标的残差而定,所以该算法对样本的噪声极为敏感。
二、L2正则化
1、L2正则化
在深度学习中,用的比较多的正则化技术是L2正则化,其形式是在原先的损失函数后边再加多一项:
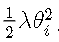
那加上L2正则项的损失函数就可以表示为:
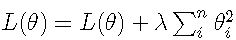
其中θ就是网络层的待学习的参数,λ则控制正则项的大小,较大的取值将较大程度约束模型复杂度,反之亦然。
L2约束通常对稀疏的有尖峰的权重向量施加大的惩罚,而偏好均匀的参数。这样的效果是鼓励神经单元利用上层的所有输入,而不是部分输入。所以L2正则项加入之后,权重的绝对值大小就会整体倾向于减少,尤其不会出现特别大的值(比如噪声),即网络偏向于学习比较小的权重。所以L2正则化在深度学习中还有个名字叫做“权重衰减”(weight decay),也有一种理解这种衰减是对权值的一种惩罚,所以有些书里把L2正则化的这一项叫做惩罚项(penalty).
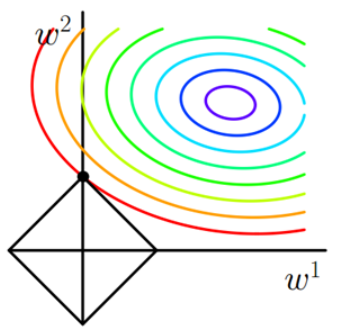
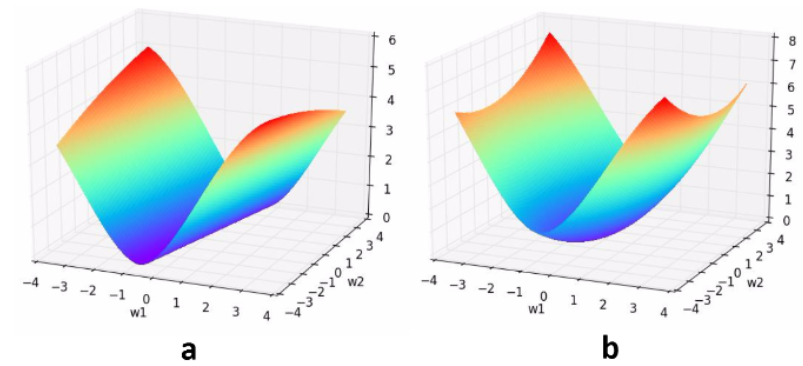
我们通过一个例子形象理解一下L2正则化的作用,考虑一个只有两个参数w1和w2的模型,其损失函数曲面如下图所示。从a可以看出,最小值所在是一条线,整个曲面看起来就像是一个山脊。那么这样的山脊曲面就会对应无数个参数组合,单纯使用梯度下降法难以得到确定解。但是这样的目标函数若加上一项
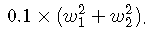
则曲面就会变成b图的曲面,最小值所在的位置就会从一条山岭变成一个山谷了,此时我们搜索该目标函数的最小值就比先前容易了,所以L2正则化在机器学习中也叫做“岭回归”(ridge regression)。
2、为什么L2正则化不具有稀疏性?
假设有如下带L2正则化的损失函数:
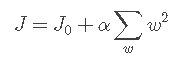


3、为什么L2正则化可以获得值很小的参数?

参考文献:
L1正则化和L2正则化的更多相关文章
- 【深度学习】L1正则化和L2正则化
在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况.正则化是机器学习中通过显式的控制模 ...
- L1正则化比L2正则化更易获得稀疏解的原因
我们知道L1正则化和L2正则化都可以用于降低过拟合的风险,但是L1正则化还会带来一个额外的好处:它比L2正则化更容易获得稀疏解,也就是说它求得的w权重向量具有更少的非零分量. 为了理解这一点我们看一个 ...
- L1正则化与L2正则化的理解
1. 为什么要使用正则化 我们先回顾一下房价预测的例子.以下是使用多项式回归来拟合房价预测的数据: 可以看出,左图拟合较为合适,而右图过拟合.如果想要解决右图中的过拟合问题,需要能够使得 $ ...
- 深入理解L1、L2正则化
过节福利,我们来深入理解下L1与L2正则化. 1 正则化的概念 正则化(Regularization) 是机器学习中对原始损失函数引入额外信息,以便防止过拟合和提高模型泛化性能的一类方法的统称.也就是 ...
- day-17 L1和L2正则化的tensorflow示例
机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作ℓ1-norm和ℓ2-norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数.L2范数也被称为权重衰 ...
- L1与L2正则化的对比及多角度阐述为什么正则化可以解决过拟合问题
正则化是一种回归的形式,它将系数估计(coefficient estimate)朝零的方向进行约束.调整或缩小.也就是说,正则化可以在学习过程中降低模型复杂度和不稳定程度,从而避免过拟合的危险. 一. ...
- L1和L2正则化(转载)
[深度学习]L1正则化和L2正则化 在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况 ...
- L1与L2正则化
目录 过拟合 结构风险最小化原理 正则化 L2正则化 L1正则化 L1与L2正则化 参考链接 过拟合 机器学习中,如果参数过多.模型过于复杂,容易造成过拟合. 结构风险最小化原理 在经验风险最小化(训 ...
- L1、L2正则化详解
正则化是一种回归的形式,它将系数估计(coefficient estimate)朝零的方向进行约束.调整或缩小.也就是说,正则化可以在学习过程中降低模型复杂度和不稳定程度,从而避免过拟合的危险. 一. ...
随机推荐
- ASP.NET使用百度编辑器(UEditor)使用方法
ASP.NET使用百度编辑器(UEditor)方法如下 第一步到百度官网下载百度编辑器 http://ueditor.baidu.com/website/download.html 下载.net版本 ...
- Elasticsearch学习之ES节点类型以及各种节点的分工
ES各种节点的分工 1. 客户端节点 当主节点和数据节点配置都设置为false的时候,该节点只能处理路由请求,处理搜索,分发索引操作等,从本质上来说该客户节点表现为智能负载平衡器.独立的客户端节点在一 ...
- PS-CC常用快捷键总结
灵活使用photoshop软件快捷键是学好该软件的基础,ps快捷键对于ps平时操作有很大帮助 熟练掌握ps的快捷键可以为了处理图片节省很多时间.现在笔者将自己平时常用的快捷键总结如下: 移动工具[V] ...
- 【CF917D】Stranger Trees 树形DP+Prufer序列
[CF917D]Stranger Trees 题意:给你一棵n个点的树,对于k=1...n,问你有多少有标号的n个点的树,与给出的树有恰好k条边相同? $n\le 100$ 题解:我们先考虑容斥,求出 ...
- ios atomic nonatomic区别
atomic和nonatomic用来决定编译器生成的getter和setter是否为原子操作. atomic 设置成员变量的@property属性时,默认为atomic,提供多线程安全 ...
- Android sd卡log日志
import android.os.Environment; import android.util.Log; import java.io.File; import java.io.FileOutp ...
- Thinkphp 验证码点击刷新解决办法
HTML代码如下: <span> <input type="text" name="code" placeholder="验证码&q ...
- PHP将富文本内容去除各类样式图片等只保留txt文本内容(作用于SEO的description)
1.从数据库读取富文本内容样式如下: <p style=";text-indent: 0;padding: 0;line-height: 26px"><span ...
- 小程序中navigator和wx.navigateTo,wx.redirectTo,wx.reLaunch,wx.switchTab,wx.navigateBack的用法
如果用一句话来表明navigator和API中wx.系列的跳转有什么区别,那就是navigator是在wxml中用标签添加open-type属性来达到和wx.系列一样的效果. navigator的属性 ...
- 数据库outer连接
left (此处省略outer) join, 左边连接右边,左边最大,匹配所有的行,不管右边 right join,右边连接左边,右边最大,匹配所有的行,不管左边 条件直接放ON后面,是先筛选右边的表 ...