【spark】共享变量
Spark中的两个重要抽象是RDD和共享变量。
一般情况下,当Spark在集群的多个不同节点的多个任务上并行运行一个函数的时候,
它会把函数中涉及到的每个变量在每个节点每个任务上都生成一个副本。
Spark 操作实际上操作的是这个函数所用变量的一个独立副本。
这些变量被复制到每台机器上,并且这些变量在远程机器上的所有更新都不会传递回驱动程序。
通常跨任务的读写变量是低效的。
但是,有时候我们需要在多个任务之间共享变量,或者在任务和任务控制节点之间共享变量。
为了满足这种需求,Spark提供了两种有限的共享变量:广播变量( broadcast variable )和累加器( accumulator )。
1.广播变量
广播变量用来把变量在所有节点的内存之间进行共享。
广播变量允许开发人员在每台机器上缓存一个只读的变量,而不是为每台机器上每个任务生成一个副本 。
Spark的任务操作一般会跨越多个阶段,对于每个阶段内的所有任务所需要的公共数据,Spark都会自动进行广播。
语法:
SparkContext.broadcase(v);
广播变量就是对普通变量v的一个包装器,通过调用value方法就可以获取这个广播变量的值。
//建立内容为Array(1,2,3)的广播变量
val broadcastVal = sc.broadcast(Array(1,2,3))
//获取广播变量的值
broadcastVal.value()
注意:我们在把变量v建立成广播变量后,在集群中的任何函数,都应该使用broadcase(v),而不是v本身,
这样就不会把v重复的分发到使用变量v的节点上。此外,我们一旦建立了broadcase(v)之后,就不行再次发生修改。
2.累加器
累加器支持在所有不同节点之间进行累加操作。
累加器是仅仅被相关操作累加的变量,通常可以被用来实现计数器和求和。
Spark原生地支持数值型(numeric)的累加器,也可以自己编写对新类型的累加器。
可以通过SparkContext.longAccumulator()或者SparkContext.doubleAccumulator()来创建累加器。
参数有两个(Int,String),第一个参数为初始累加值,默认为0,第二个参数为累加器的名字。
运行在集群中的任务,就可以使用add()方法来把数值累加到累加器上。
但是任务节点执行做累加操作,不能读取累加器的值,只有任务控制节点(Driver Program)可以使用value方法来读取。
import org.apache.spark._
object MyRdd {
def main(args:Array[String]): Unit ={
//初始化配置:设置主机名和程序主类的名字
val conf = new SparkConf().setMaster("local").setAppName("MyRdd");
//通过conf来创建sparkcontext
val sc = new SparkContext(conf);
val accum = sc.longAccumulator("My Accumulator");//后边是计数器的名字
val list = List(1,2,3,4,5);
val rdd = sc.parallelize(list);
rdd.foreach(x => accum.add(x));//调用累加器求和
accum.value;//注意只有任务控制节点(Driver节点)才能使用value方法来获取累加器的值
}
}
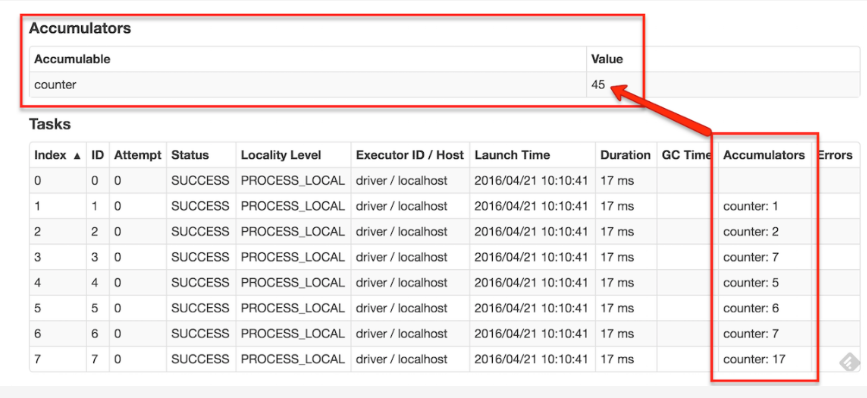
如果创建了一个具名的累加器,它可以在spark的UI中显示。这对于理解运行阶段(running stages)的过程有很重要的作用。
【spark】共享变量的更多相关文章
- spark共享变量
boradcast例子代码: scala版本 spark共享变量之Accumulator 例子代码: scala版本
- 7.spark共享变量
spark共享变量 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性分布式数据集 ...
- Spark——共享变量
Spark执行不少操作时都依赖于闭包函数的调用,此时如果闭包函数使用到了外部变量驱动程序在使用行动操作时传递到集群中各worker节点任务时就会进行一系列操作: 1.驱动程序使将闭包中使用变量封装成对 ...
- Spark共享变量(广播变量、累加器)
转载自:https://blog.csdn.net/Android_xue/article/details/79780463 Spark两种共享变量:广播变量(broadcast variable)与 ...
- SPARK共享变量:广播变量和累加器
Shared Variables Spark does provide two limited types of shared variables for two common usage patte ...
- Spark分布式编程之全局变量专题【共享变量】
转载自:http://www.aboutyun.com/thread-19652-1-1.html 问题导读 1.spark共享变量的作用是什么?2.什么情况下使用共享变量?3.如何在程序中使用共享变 ...
- 9.Spark Streaming
Spark Streaming 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性 ...
- 8.Spark SQL
Spark SQL 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性分布式数据集 ...
- 5.spark弹性分布式数据集
弹性分布式数据集 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性分布式数据集 ...
- 4.Apache Spark的工作原理
Apache Spark的工作原理 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark ...
随机推荐
- 用户登录失败,该用户与可信SQL Server连接无关联,错误:18452
安装好SQLServer2005(或者装了Visual Studio 2008后自带的SQLServer2005)用SQL Server身份验证的登录的时候有时候会发生这种情况: 这样的错误的原因是: ...
- 部门人员能力模型的思考:海军 or 海盗——By Me
我们欢迎您的加入,与我们一起推动安全可视化团队的成长,实现技术上共同进步和感情上的更多互相支持!
- 010-JDK可视化监控工具-VisualVM
一.概述 VisualVM是一个集成多个JDK命令行工具的可视化工具.VisualVM基于NetBeans平台开发,它具备了插件扩展功能的特性,通过插件的扩展,可用于显示虚拟机进程及进程的配置和环境信 ...
- 008-CentOS添加环境变量
在Linux CentOS系统上安装完php和MySQL后,为了使用方便,需要将php和mysql命令加到系统命令中,如果在没有添加到环境变量之前,执行“php -v”命令查看当前php版本信息时时, ...
- SqlHelper简单实现(通过Expression和反射)4.对象反射Helper类
ObjectHelper的主要功能有: 1.通过反射获取Entity的实例的字段值和表名,跳过自增键并填入Dictionary<string,string>中. namespace RA. ...
- hadoop28---netty传对象
Netty中,通讯的双方建立连接后,会把数据按照ByteBuf的方式进行传输,例如http协议中,就是通过HttpRequestDecoder对ByteBuf数据流进行处理,转换成http的对象.基于 ...
- CF715E Complete the Permutations(第一类斯特林数)
题目 CF715E Complete the Permutations 做法 先考虑无\(0\)排列的最小花费,其实就是沿着置换交换,花费:\(n-\)环个数,所以我们主要是要求出规定环的个数 考虑连 ...
- Python3:自动发送账单邮件
Python3:自动发送账单邮件 一.前言 民间借贷,没有信用卡那样,每月会收到账单:为了民间借贷管理更加合理化,写了个还款账单小程序. 二.源码 (1)配置文件代码: [dbmysql] ip = ...
- MongoDB快速入门(十一)- sort() 方法
sort() 方法 要在 MongoDB 中的文档进行排序,需要使用sort()方法. sort() 方法接受一个文档,其中包含的字段列表连同他们的排序顺序.要指定排序顺序1和-1. 1用于升序排列, ...
- Spring Boot 中修改端口和上下文路径
通过修改application.properties内容来改变访问的端口号和上下文路径(很简单!) spring.mvc.view.prefix=/WEB-INF/jsp/ spring.mvc.vi ...