CentOS7搭建hadoop2.6.4+HBase1.1.6
环境:
CentOS7
hadoop2.6.4两个节点:master、slave1
HBase1.1.6
过程:
hadoop安装目录:/usr/hadoop-2.6.4
master节点,hadoop用户登录。在hadoop目录下新建thirdparty目录:
$ mkdir thirdparty
目录结构:

把hbase1.1.6解压到thirdparty目录下:
$ cp ~/hbase-1.1.6-bin.tar.gz thirdparty
$ cd thirdparty
$ tar zxvf hbase-1.1.6-bin.tar.gz
$ cd hbase-1.1.6
$ ls

将hbase添加到环境变量中。
$ sudo gedit /etc/profile
添加:
export HBASE_HOME=/usr/hadoop-2.6.4/thirdparty/hbase-1.1.6
export PATH=$HBASE_HOME/bin:$PATH
$ source /etc/profile生效。
修改hbase-env.sh,添加:
export JAVA_HOME=/usr/java/jdk1..0_101
修改hbase-site.xml:
<configuration>
<property>
<name>hbase.rootdir</name><value>hdfs://master:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name><value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/hadoop-2.6.4/thirdparty/zookeeper</value>
</property>
</configuration>
修改regionservers,在regionservers文件中添加如下内容:
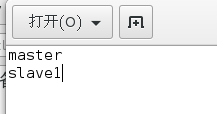
然后在每个DataNode节点上也设立同样的文件结构和配置。
启动hbase。首先启动hadoop:
$ start-dfs.sh && start-yarn.sh
启动hbase:
$ start-hbase.sh

查看hbase进程:
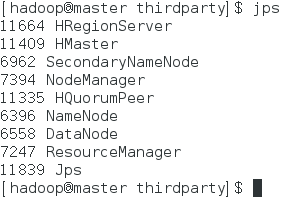
发现多了HMaster和HQuorumPeer这两个进程。
查看DataNode进程:
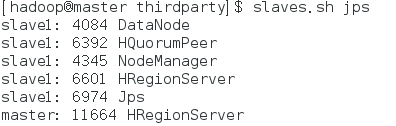
发现多了HQuorumPeer和HRegionServer这两个进程。
浏览器访问http://master:16030/
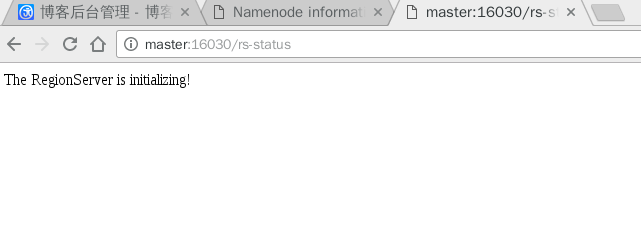 (此处与教程不符?)
(此处与教程不符?)
运行hbase shell命令:
原文:http://blog.csdn.net/wuwenxiang91322/article/details/44684655
CentOS7搭建hadoop2.6.4+HBase1.1.6的更多相关文章
- centos7搭建hadoop2.10高可用(HA)
本篇介绍在centos7中搭建hadoop2.10高可用集群,首先准备6台机器:2台nn(namenode);4台dn(datanode):3台jns(journalnodes) IP hostnam ...
- centos7搭建hadoop2.10完全分布式
本篇介绍在centos7中大家hadoop2.10完全分布式,首先准备4台机器:1台nn(namenode);3台dn(datanode) IP hostname 进程 192.168.30.141 ...
- centos7搭建hadoop-2.7.3,zookeeper-3.4.6,hbase-1.2.5(root用户)
环境:[centos7.hadoop-2.7.3.zookeeper-3.4.6.hbase-1.2.5] 两个节点:[主节点,主机名为Master,用户为root:从节点,主机名为Slave,用户为 ...
- CentOS7.0+Hadoop2.7.2+Hbase1.2.1搭建教程
1.软件版本 CentOS-7.0-1406-x86_64-DVD.iso jdk-7u80-linux-x64.tar.gz hadoop-2.7.2.tar.gz hbase-1.2.1-bin. ...
- CentOS7搭建Hadoop2.8.0集群及基础操作与测试
环境说明 示例环境 主机名 IP 角色 系统版本 数据目录 Hadoop版本 master 192.168.174.200 nameNode CentOS Linux release 7.4.1708 ...
- CentOS7搭建hadoop2.6.4双节点集群
环境: CentOS7+SunJDK1.8@VMware12. NameNode虚拟机节点主机名:master,IP规划:192.168.23.101,职责:Name node,Secondary n ...
- centos7搭建hadoop2.10伪分布模式
1.准备一台Vmware虚拟机,添加hdfs用户及用户组,配置网络见 https://www.cnblogs.com/qixing/p/11396835.html 在root用户下 添加hdfs用户, ...
- Centos7 搭建hadoop2.6 HA
用户配置: User :root Password:toor 2.创建新用户 student Pwd: student 3.安装virtualbox的增强工具软件 4.系统默认安装的是openjdk ...
- Hadoop2.7.3+HBase1.2.5+ZooKeeper3.4.6搭建分布式集群环境
Hadoop2.7.3+HBase1.2.5+ZooKeeper3.4.6搭建分布式集群环境 一.环境说明 个人理解:zookeeper可以独立搭建集群,hbase本身不能独立搭建集群需要和hadoo ...
随机推荐
- Openstack Basic Networking 翻译
自己翻译,加强理解.并学习英文和写作. 英文地址:http://docs.openstack.org/networking-guide/intro_basic_networking.html 目录: ...
- android 之 Toast通知的使用
1.默认效果: 代码: Toast.makeText(getApplicationContext(), "默认Toast样式", Toast.LENGTH_SHORT ...
- 【CodeVS 3123】高精度练习之超大整数乘法 &【BZOJ 2197】FFT快速傅立叶
第一次写法法塔,,,感到威力无穷啊 看了一上午算导就当我看懂了?PS:要是机房里能有个清净的看书环境就好了 FFT主要是用了巧妙的复数单位根,复数单位根在复平面上的对称性使得快速傅立叶变换的时间复杂度 ...
- VS 2013 未找到与约束contractname Microsoft.VisualStudio.Utilities.IContentTypeRegistryService...匹配的导出[vs故障]【转】
未找到与约束 contractname Microsoft.VisualStudio.Utilities.IContentTypeRegistryService RequiredTypeIdentit ...
- IOS并发编程GCD
iOS有三种多线程编程的技术 (一)NSThread (二)Cocoa NSOperation (三)GCD(全称:Grand Central Dispatch) 这三种编程方式从上到下,抽象度层次 ...
- Java Decompiler 反编译工具下载地址及JD-Eclipse设置菜单翻译
官网地址:http://jd.benow.ca/ JD-GUI:jd-gui-0.3.6.windows.zip JD-Eclipse:jd-eclipse-site-1.0.0-RC2.zip 菜单 ...
- Javaweb容器的四种作用域
几乎所有web应用容器都提供了四种类似Map的结构:application session request page,Jsp或者Servlet通过向着这四个对象放入数据,从而实现Jsp和Servlet ...
- servlet注解@PostConstruct与@PreDestroy
从Java EE 5规范开始,Servlet中增加了两个影响Servlet生命周期的注解(Annotion):@PostConstruct和@PreDestroy.这两个注解被用来修饰一个非静态的vo ...
- Java多线程有哪几种实现方式? Java中的类如何保证线程安全? 请说明ThreadLocal的用法和适用场景
java的同步机制,大概是通过:1.synchronized:2.Object方法中的wait,notify:3.ThreadLocal机制来实现的, 其中synchronized有两种用法:1.对类 ...
- Web前端性能优化教程09:图像和Cookie优化
本文是Web前端性能优化系列文章中的第九篇,主要讲述内容:图像和Cookie优化.完整教程可查看: 一. 图像优化 图像基础知识 gif: 适用于动画效果,例如提示的滚动条图案 jpg: 是一种使用 ...