论文解读(Graphormer)《Do Transformers Really Perform Bad for Graph Representation?》
论文信息
论文标题:Do Transformers Really Perform Bad for Graph Representation?
论文作者:Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu
论文来源:2021, NeurIPS
论文地址:download
论文代码:download
1 Introduction
创新点:将 Transfomer 用于图表示领域。
- 首先,我们提出了中心性编码(Centrality Encoding)来捕获图中节点的重要性;
- 其次,我们提出了一种新的空间编码(Spatial Encoding)来捕获节点之间的结构关系;
2 Method
预备知识:
Transformer 两个重要模块:
- a self-attention module
- a position-wise feed-forward network (FFN)
设 $H=\left[h_{1}^{\top}, \cdots, h_{n}^{\top}\right]^{\top} \in \mathbb{R}^{n \times d}$ 表示自注意模块的输入,其中 $d$ 是隐藏维数,$h_{i} \in \mathbb{R}^{1 \times d}$ 。输入 $H$ 由三个矩阵 $W_{Q} \in \mathbb{R}^{d \times d_{K}}$、$W_{K} \in \mathbb{R}^{d \times d_{K}}$ 、 $W_{V} \in \mathbb{R}^{d \times d_{V}} $ 投影到相应的表示形式 $Q$、$K$、$V$。自注意(self-attention)的计算:
$Q=H W_{Q}, \quad K=H W_{K}, \quad V=H W_{V} \quad\quad\quad(3)$
$A=\frac{Q K^{\top}}{\sqrt{d_{K}}}, \quad \operatorname{Attn}(H)=\operatorname{softmax}(A) V \quad\quad\quad(4)$
其中,$A$ 是一个捕获 queries 和 keys 之间的相似性的矩阵。
为了便于说明,我们考虑了单头自注意,并假设 $d_K=d_V=d$。对多头注意力的扩展是标准的和直接的,为了简单起见,我们省略了偏差项
2.1 Structural Encodings in Graphormer
如上述所述,在 Transformer 中使用图结构信息很重要,为此在Graphormer 提出了三种简单而有效的编码器设计。如 Figure 1 所示。
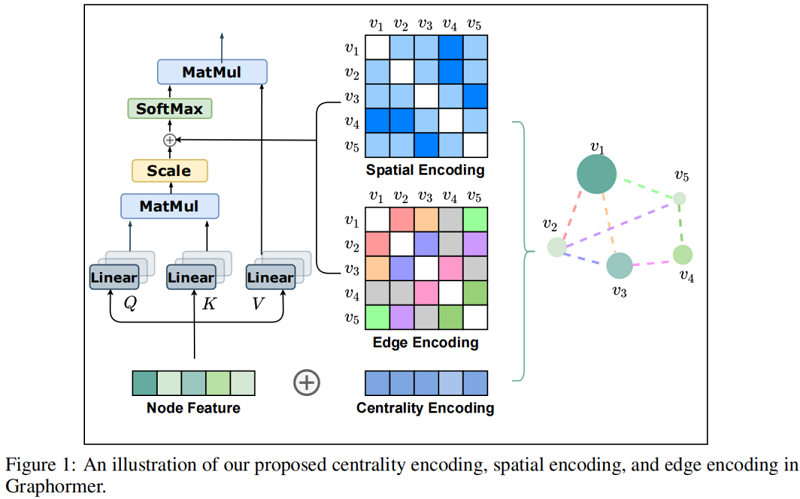
2.1.1 Centrality Encoding
在 $\text{Eq.4}$ 中,根据节点间的语义相关性计算注意力分布。然而,节点中心性(衡量节点在图中的重要性),可以认为是图中强烈的信号。例如,拥有大量粉丝的名人是预测社交网络发展趋势的重要因素。这些信息在当前的注意力计算中被忽略了,我们认为它应该是 Transformer 模型的一个有价值的信号。
$h_{i}^{(0)}=x_{i}+z_{\operatorname{deg}^{-}\left(v_{i}\right)}^{-}+z_{\operatorname{deg}^{+}\left(v_{i}\right)}^{+} \quad\quad\quad(5)$
其中,$z^{-}, z^{+} \in \mathbb{R}^{d}$ 分别是由入度 $deg { }^{-}\left(v_{i}\right)$ 和 出度 $\operatorname{deg}^{+}\left(v_{i}\right)$ 指定的可学习的嵌入向量。对于无向图,$deg { }^{-}\left(v_{i}\right)$ 和 $\operatorname{deg}^{+}\left(v_{i}\right)$ 可以统一为 $\operatorname{deg}\left(v_{i}\right)$。通过在输入中使用中心性编码,softmax attention 可以捕获 queries 和 keys 中的节点重要性信号。因此,该模型可以同时捕获注意机制中的语义相关性和节点的重要性。
2.1.2 Spatial Encoding
在每个 Transformer 层中,每个 token 都可以关注任何位置的信息,但需要解决的问题是空间位置信息表示(位置依赖信息)。对于顺序数据我们使用一个位置嵌入向量,对 Tramsformer 层中的任何两个位置的相对距离进行编码。
但是对于图来说,节点顺序不是按序列排放的,它存在于多维空间,通过边连接。为了对图空间位置信息进行编码,本文提出了一种新的 Spatial Encoding 方法。
具体地说,对于任何图 $G$,定义函数 $\phi\left(v_{i}, v_{j}\right): V \times V \rightarrow \mathbb{R}$ 测量 $v_{i}$ 和 $v_{j}$ 之间的空间关系。函数 $\phi$ 可通过图中节点之间的连通性来定义。在本文中,对于连通节点 $v_{i}$ 和 $v_{j}$ , $\phi\left(v_{i}, v_{j}\right)$ 定义为 $v_{i}$ 和 $v_{j}$ 之间的最短路径(SPD)的距离。如果 $v_{i}$ 和 $v_{j}$ 不连通,将 $\phi$ 设置为一个特殊的值,即 $-1$。本文对给每对连通节点分配一个可学习的标量,将作为自注意模块中的一个偏差项。 $ A_{i j}$ 表示为 Query-Key 乘积矩阵 $A$ 的 $(i,j)$ 元素,因此有:
$A_{i j}=\frac{\left(h_{i} W_{Q}\right)\left(h_{j} W_{K}\right)^{T}}{\sqrt{d}}+b_{\phi\left(v_{i}, v_{j}\right)} \quad\quad\quad(6)$
$b_{\phi\left(v_{i}, v_{j}\right)}$ 是一个由 $\phi\left(v_{i}, v_{j}\right)$ 索引的可学习的标量,并在所有层中共享。
对比于 GNNs,好处是:
- 首先,GNNs 的感受域局限于邻居,而在 $Eq.6$ 中所涉及的范围是全局信息,每个节点可以关注其他节点;
- 其次,通过使用 $b_{\phi\left(v_{i}, v_{j}\right)}$ ,单个 Transformer 层中的每个节点都可以根据图的结构信息自适应地关注所有其他节点。如果 $b_{\phi\left(v_{i}, v_{j}\right)}$ 是相对于 $\phi\left(v_{i}, v_{j}\right)$ 的递减函数,对于每个节点,模型可能会更关注其附近的节点,而对远离它较少的节点;
2.1.3 Edge Encoding in the Attention
类比于原子之间的键,边之间的关系也很重要,将边编码与节点特征一起放入网络中是必不可少的。
以往的边编码方法有两种形式:
- 将边特征添加到相关节点的特征中;
- 对于每个节点,其关联边的特征将与聚合中的节点特征一起使用;
然而,这种使用边特征的方法只将边信息传播到相关的节点,这可能不是利用边缘信息表示整个图的有效方法。
为了更好的将边特征编码到注意力层,本文提出了一种新的边编码方式。
注意机制需要估计每个节点对 $\left(v_{i}, v_{j}\right)$ 的相关性,对于每个有序节点对 $\left(v_{i}, v_{j}\right)$ ,我们找到了从 $v_{i}$ 到 $v_{j}$ 的最短路径 $\mathrm{SP}_{i j}=\left(e_{1}, e_{2}, \ldots, e_{N}\right)$ ,并计算了边特征的点积和沿路径的可学习嵌入的平均值。所提出的边编码通过一个偏差项将边特征合并到注意模块中。
具体地说,我们修改了 $Eq.3$ 中 $A$ 的 $(i,j)$ 元素,通过加入边编码 $c_{i j}$ ,$A$ 进一步表示为:
$A_{i j}=\frac{\left(h_{i} W_{Q}\right)\left(h_{j} W_{K}\right)^{T}}{\sqrt{d}}+b_{\phi\left(v_{i}, v_{j}\right)}+c_{i j}, \;\;\;\; \text { where }\;\;\;\; c_{i j}=\frac{1}{N} \sum\limits_{n=1}^{N} x_{e_{n}}\left(w_{n}^{E}\right)^{T} \quad\quad\quad(7)$
其中 $x_{e_{n}}$ 为 $\mathrm{SP}_{i j}$, $w_{n}^{E} \in \mathbb{R}^{d_{E}}$ 中第 $n$ 条边的特征,$w_{n}^{E} \in \mathbb{R}^{d_{E}}$ 为第 $n$ 个权值向量,$d_{E}$ 为边特征的维数。
2.2 Implementation Details of Graphormer
Graphormer Layer
Graphormer 是建立在经典 Transformer 编码器上。此外,在多头自注意(MHA)和前馈块(FFN)之前应用层归一化(LN)。对于 FFN 子层,将输入、输出和隐藏层的维数设置为与 $d$ 相同的维数。我们正式地描述了 Graphormer 层如下:
$h^{\prime}(l) =\operatorname{MHA}\left(\mathbf{L N}\left(h^{(l-1)}\right)\right)+h^{(l-1)} \quad\quad\quad(8)$
$h^{(l)} =\operatorname{FFN}\left(\operatorname{LN}\left(h^{\prime}(l)\right)\right)+h^{\prime}(l) \quad\quad\quad(9)$
Special Node
如前一节所述,我们提出了各种图池函数来表示图的嵌入。在 Graphormer 中,在图中添加了一个名为 $[VNode]$ 的特殊节点,并分别在 $[VNode]$ 和每个节点之间分别进行连接。在 AGGREGATE-COMBINE 步骤中,$[VNode]$ 的表示已被更新为图中的普通节点,而整个图 $h_G$ 的表示将是最后一层 $[VNode]$ 的节点特征。在 $BERT$ 模型中,有一个类似的标记,即 $[CLS]$,它是每个序列开头附加的特殊标记,用于表示下游任务的序列级特征。虽然 $[VNode]$ 连接到图中的所有其他节点,这意味着对于任何 $\phi\left([\mathrm{VNode}], v_{j}\right)$ 和 $\phi\left(v_{i}\right. , [VNode] )$,最短路径的距离为 $1$,但该连接不是物理的。为了区分物理和虚拟的连接,受[25]的启发,我们将 $b_{\phi\left([\text { VNode }], v_{j}\right)}$ 和 $b_{\phi\left(v_{i},[\text { VNode }]\right)}$ 的所有空间编码重置为一个独特的可学习标量。
2.3 How Powerful is Graphormer?
Graphormer 可以表示 AGGREGATE 和 COMBINE 操作。
Fact 1. By choosing proper weights and distance function $\phi$ , the Graphormer layer can represent AGGREGATE and COMBINE steps of popular GNN models such as GIN, GCN, GraphSAGE.
该事实说明:
- 1) Spatial encoding 使自注意模块能够区分节点 $v_{i}$ 的邻域集 $\mathcal{N}\left(v_{i}\right)$,从而使 softmax 函数能够计算出 $\mathcal{N}\left(v_{i}\right)$ 上的平均统计量;
- 2) 知道一个节点的程度,邻居的平均值可以转换为邻居的和;
- 3) 通过 multiple heads 和 FFN, $v_{i}$ 和 $\mathcal{N}\left(v_{i}\right)$ 的表示可以分别处理,然后再组合在一起;
此外,进一步表明,通过使用空间编码,信号信号器可以超越经典的信息传递 GNNs,其表达能力不超过 1-WL 测试。
Connection between Self-attention and Virtual Node
除了比流行的 GNN 具有更好的表达性外,我们还发现在使用自注意和虚拟节点启发式之间存在着有趣的联系。如 OGB[22] 的排行榜所示,虚拟节点技巧在图中增加了连接到现有图中的所有节点,可以显著提高现有 GNN 的性能。从概念上讲,虚拟节点的好处是它可以聚合整个图的信息(比如 READOUT ),然后将其传播到每个节点。然而,在图中简单地添加一个超节点可能会导致信息传播的意外过度平滑。相反,我们发现这种图级的聚合和传播操作可以通过普通的自注意自然地实现,而不需要额外的编码。具体地说,我们可以证明以下事实:
Fact 2. By choosing proper weights, every node representation of the output of a Graphormer layer without additional encodings can represent MEAN READOUT functions.
这一事实利用了自我注意,每个节点可以注意所有其他节点。因此,它可以模拟图级读出(READOUT)操作,从整个图中聚合信息。除了理论上的论证外,我们还发现 Graphormer 没有遇到过度平滑的问题,这使得改进具有可扩展性。这一事实也激励了我们为图形读出引入一个特殊的节点(见上一小节)。
3 Experiment
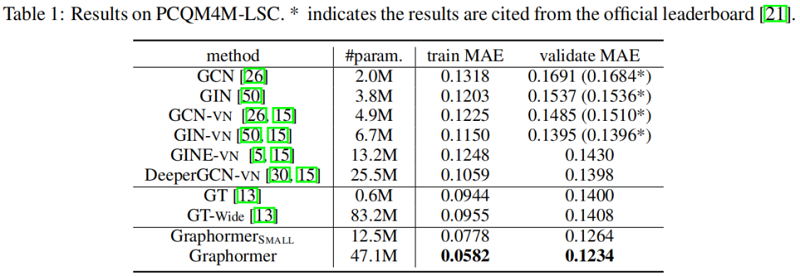
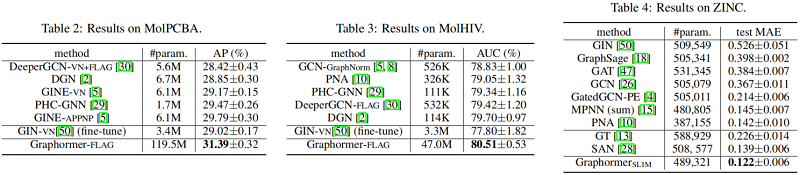
4 Conclusion
我们探讨了变压器在图表示中的直接应用。通过三种新的图结构编码,所提出的制图器在广泛的流行的基准数据集上工作得非常好。虽然这些初步结果令人鼓舞,但仍存在许多挑战。例如,自注意模块的二次复杂度限制了隐指器在大图上的应用。因此,今后发展高效磨粉剂是必要的。通过在特定的图数据集上利用领域知识驱动的编码,可以预期提高性能。最后,提出了一种适用的图采样策略来提取节点表示。我们把他们留给以后的工作吧。
论文解读(Graphormer)《Do Transformers Really Perform Bad for Graph Representation?》的更多相关文章
- 论文解读(GraphMAE)《GraphMAE: Self-Supervised Masked Graph Autoencoders》
论文信息 论文标题:GraphMAE: Self-Supervised Masked Graph Autoencoders论文作者:Zhenyu Hou, Xiao Liu, Yukuo Cen, Y ...
- 论文解读(GMT)《Accurate Learning of Graph Representations with Graph Multiset Pooling》
论文信息 论文标题:Accurate Learning of Graph Representations with Graph Multiset Pooling论文作者:Jinheon Baek, M ...
- 论文解读(LA-GNN)《Local Augmentation for Graph Neural Networks》
论文信息 论文标题:Local Augmentation for Graph Neural Networks论文作者:Songtao Liu, Hanze Dong, Lanqing Li, Ting ...
- 论文解读(SUBLIME)《Towards Unsupervised Deep Graph Structure Learning》
论文信息 论文标题:Towards Unsupervised Deep Graph Structure Learning论文作者:Yixin Liu, Yu Zheng, Daokun Zhang, ...
- 论文解读(GSAT)《Interpretable and Generalizable Graph Learning via Stochastic Attention Mechanism》
论文信息 论文标题:Interpretable and Generalizable Graph Learning via Stochastic Attention Mechanism论文作者:Siqi ...
- 论文解读(PPNP)《Predict then Propagate: Graph Neural Networks meet Personalized PageRank》
论文信息 论文标题:Predict then Propagate: Graph Neural Networks meet Personalized PageRank论文作者:Johannes Gast ...
- 论文解读(DropEdge)《DropEdge: Towards Deep Graph Convolutional Networks on Node Classification》
论文信息 论文标题:DropEdge: Towards Deep Graph Convolutional Networks on Node Classification论文作者:Yu Rong, We ...
- 论文解读(SEP)《Structural Entropy Guided Graph Hierarchical Pooling》
论文信息 论文标题:Structural Entropy Guided Graph Hierarchical Pooling论文作者:Junran Wu, Xueyuan Chen, Ke Xu, S ...
- 论文解读(GATv2)《How Attentive are Graph Attention Networks?》
论文信息 论文标题:How Attentive are Graph Attention Networks?论文作者:Shaked Brody, Uri Alon, Eran Yahav论文来源:202 ...
随机推荐
- Dubbo 服务降级,失败重试怎么做?
可以通过 dubbo:reference 中设置 mock="return null".mock 的值也可以修 改为 true,然后再跟接口同一个路径下实现一个 Mock 类,命名 ...
- spring-boot-关于module自定义jar包打包无法给其他module使用
####世界大坑: 如果仅是使用 <build> <plugins> <plugin> <groupId>org.springframework.boo ...
- spring-boot-learning-使用jsp
加入依赖: <!-- jsp--> <!--引入Spring Boot内嵌的Tomcat对JSP的解析包--> <dependency> <groupId&g ...
- gulp详细基础教程
一.gulp简介 1.gulp是什么? gulp是前端开发过程中一种基于流的代码构建工具,是自动化项目的构建利器:它不仅能对网站资源进行优化,而且在开发过程中很多重复的任务能够使用正确的工具自动完成: ...
- 腾讯云+社区开发者大会开启报名,WeGeek 邀你一起聊聊小程序
刚满 2 岁的微信小程序,正给我们带来一种全新轻便的生活方式. 内测时的青涩还历历在目,到现在,小程序生态已日渐成熟.超过 150 万开发者在这里找到了自己的新天地,打磨出超过 100 万个小程序. ...
- AS的不同布局
AndroidStudio里面支持的布局有挺多种的,但是最最重要的是RelativeLayout(相对布局)和LinearLayout(线性布局),熟练掌握这两种布局也非常够用了,当然还有FrameL ...
- hdfs对文件的增删改查
源代码: pom.xml: <?xml version="1.0" encoding="UTF-8"?> <project xmlns=&qu ...
- oracle数据库存储过程中的select语句的位置
导读:在oracle数据库存储过程中如果用了select语句,要么使用"select into 变量"语句要么使用游标,oracle不支持单独的select语句. 先看下这个存储过 ...
- 引用nodejs的url模块实现url路由功能
我们在本地创建服务器之后需要写不同的后缀名来访问同一个站点的不同页面,如果不实现路由功能.则每次访问localhost:3000 不论后面写什么 比如localhost:3000/index.loc ...
- 项目中常用到的布局 flex
1. 没header,footer固定 html<div class="page"> <div class="top"> <div ...