scrapy框架爬取国际庄2011-2022的天气情况
目标网站:http://www.tianqihoubao.com/lishi/
一.创建项目+初始化爬虫文件:
scrapy startpoject tianqihoubao
cd tianqihoubao
scrapy genspider weather www.tianqihoubao.com
二.配置settings.py
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.30'
ROBOTSTXT_OBEY = False #君子协议 注释掉或者改为false
ITEM_PIPELINES = {
'tianqihoubao.pipelines.TianqihoubaoPipeline': 300,
'tianqihoubao.pipelines.MySQLStoreCnblogsPipeline': 300
}
# 连接数据MySQL
# 数据库地址
MYSQL_HOST = 'localhost'
# 数据库用户名:
MYSQL_USER = 'root'
# 数据库密码
MYSQL_PASSWORD = '123456'
# 数据库端口
MYSQL_PORT = 3306
# 数据库名称
MYSQL_DBNAME = 'data'
# 数据库编码
MYSQL_CHARSET = 'utf8'
三.修改items.py
import scrapy class TianqihoubaoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
riqi = scrapy.Field()
tianqi = scrapy.Field()
qiwen = scrapy.Field()
wind = scrapy.Field()
四.编写weather.py
scrapy.Request()教程:Scrapy爬虫入门教程十一 Request和Response(请求和响应)
import scrapy from tianqihoubao.items import TianqihoubaoItem class WeatherSpider(scrapy.Spider):
name = 'weather'
allowed_domains = ['www.tianqihoubao.com']
start_urls = ['http://www.tianqihoubao.com/lishi/shijiazhuang.html'] def parse(self, response):
#for path in self.start_urls:
data = response.xpath('//div[@id="content"]/table[@class="b"]/tr')
next_page = response.xpath('//div[@id="content"]/div[@class="box pcity"]/ul/li/a/@href').extract()
for i in data[1:]:
item = TianqihoubaoItem()
item['riqi'] = i.xpath('./td/a/text()').extract()[0].replace('\r\n', '').replace('\n', '').replace(' ', '').strip()
item['tianqi'] = i.xpath('./td/text()').extract()[2].replace('\r\n', '').replace('\n', '').replace(' ', '').strip()
item['qiwen'] = i.xpath('./td/text()').extract()[3].replace('\r\n', '').replace('\n', '').replace(' ', '').strip()
item['wind'] = i.xpath('./td/text()').extract()[4].replace('\r\n', '').replace('\n', '').replace(' ', '').strip()
#print(item['tianqi']) yield item print("下一页", next_page)
if next_page and len(next_page) > 5:
# 翻页
for i in next_page:
yield scrapy.Request(url='http://www.tianqihoubao.com'+i, callback=self.parse)
else:
print("没有下一页了" * 10)
print(data)
五.配置pipelines.py(一个保存为csv,一个保存到mysql上)
import copy
import csv
import time from pymysql import cursors
from twisted.enterprise import adbapi class TianqihoubaoPipeline(object):
# 保存为csv格式
def __init__(self):
# 打开文件,指定方式为写,利用第3个参数把csv写数据时产生的空行消除
self.f = open("weather.csv", "a", newline="", encoding="utf-8")
# 设置文件第一行的字段名,注意要跟spider传过来的字典key名称相同
self.fieldnames = ["riqi", "tianqi", "qiwen", "wind"]
# 指定文件的写入方式为csv字典写入,参数1为指定具体文件,参数2为指定字段名
self.writer = csv.DictWriter(self.f, fieldnames=self.fieldnames)
# 写入第一行字段名,因为只要写入一次,所以文件放在__init__里面
self.writer.writeheader() def process_item(self, item, spider):
# 写入spider传过来的具体数值
self.writer.writerow(item)
# 写入完返回
return item def close(self, spider):
self.f.close() class MySQLStoreCnblogsPipeline(object):
# 初始化函数
def __init__(self, db_pool):
self.db_pool = db_pool # 从settings配置文件中读取参数
@classmethod
def from_settings(cls, settings):
# 用一个db_params接收连接数据库的参数
db_params = dict(
host=settings['MYSQL_HOST'],
user=settings['MYSQL_USER'],
password=settings['MYSQL_PASSWORD'],
port=settings['MYSQL_PORT'],
database=settings['MYSQL_DBNAME'],
charset=settings['MYSQL_CHARSET'],
use_unicode=True,
# 设置游标类型
cursorclass=cursors.DictCursor
)
# 创建连接池
db_pool = adbapi.ConnectionPool('pymysql', **db_params) # 返回一个pipeline对象
return cls(db_pool) # 处理item函数
def process_item(self, item, spider):
# 对象拷贝,深拷贝 --- 这里是解决数据重复问题!!!
asynItem = copy.deepcopy(item) # 把要执行的sql放入连接池
query = self.db_pool.runInteraction(self.insert_into, asynItem) # 如果sql执行发送错误,自动回调addErrBack()函数
query.addErrback(self.handle_error, item, spider) # 返回Item
return item # 处理sql函数
def insert_into(self, cursor, item):
# 创建sql语句
sql = "INSERT INTO weather (riqi,tianqi,qiwen,wind) VALUES ('{}','{}','{}','{}')".format(
item['riqi'], item['tianqi'], item['qiwen'], item['wind'])
# 执行sql语句
cursor.execute(sql)
# 错误函数 def handle_error(self, failure, item, spider):
# #输出错误信息
print("failure", failure)
六.结果
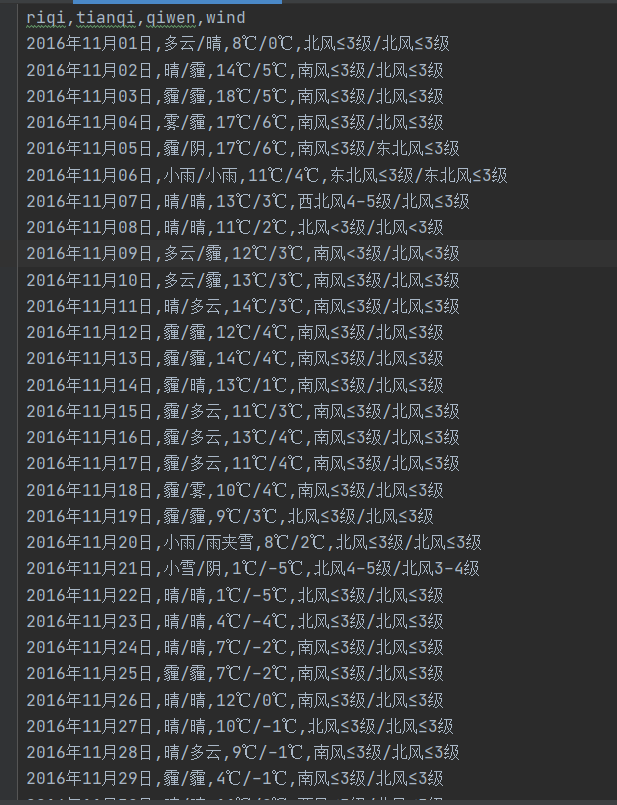

这个在爬取的时候没有按时间顺序来,后续在搞一搞
scrapy框架爬取国际庄2011-2022的天气情况的更多相关文章
- 使用scrapy框架爬取自己的博文(2)
之前写了一篇用scrapy框架爬取自己博文的博客,后来发现对于中文的处理一直有问题- - 显示的时候 [u'python\u4e0b\u722c\u67d0\u4e2a\u7f51\u9875\u76 ...
- scrapy框架爬取笔趣阁完整版
继续上一篇,这一次的爬取了小说内容 pipelines.py import csv class ScrapytestPipeline(object): # 爬虫文件中提取数据的方法每yield一次it ...
- scrapy框架爬取笔趣阁
笔趣阁是很好爬的网站了,这里简单爬取了全部小说链接和每本的全部章节链接,还想爬取章节内容在biquge.py里在加一个爬取循环,在pipelines.py添加保存函数即可 1 创建一个scrapy项目 ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- 爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据
为了入门scrapy框架,昨天写了一个爬取静态小说网站的小程序 下面我们尝试爬取全书网中网游动漫类小说的书籍信息. 一.准备阶段 明确一下爬虫页面分析的思路: 对于书籍列表页:我们需要知道打开单本书籍 ...
- 使用scrapy框架爬取自己的博文(3)
既然如此,何不再抓一抓网页的文字内容呢? 谷歌浏览器有个审查元素的功能,就是按树的结构查看html的组织形式,如图: 这样已经比较明显了,博客的正文内容主要在div 的class = cnblogs_ ...
- 使用scrapy框架爬取自己的博文
scrapy框架是个比较简单易用基于python的爬虫框架,http://scrapy-chs.readthedocs.org/zh_CN/latest/ 这个是不错的中文文档 几个比较重要的部分: ...
- 基于python的scrapy框架爬取豆瓣电影及其可视化
1.Scrapy框架介绍 主要介绍,spiders,engine,scheduler,downloader,Item pipeline scrapy常见命令如下: 对应在scrapy文件中有,自己增加 ...
- scrapy框架爬取豆瓣读书(1)
1.scrapy框架 Scrapy,Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 ...
随机推荐
- WPF优秀组件推荐之MahApps
概述 MahApps是一套基于WPF的界面组件,通过该组件,可以使用较小的开发成本实现一个相对很好的界面效果. 官方网站:MahApps.Metro - Home 开源代码:MahApps · Git ...
- CPU乱序执行基础 —— Tomasulo算法及执行过程
朋友们可以关注下我的公众号,获得最及时的更新: IBM 360/91浮点单元最先实现Tomasulo算法从而允许乱序执行.360体系只有4个双精度浮点寄存器,限制了编译器调度的有效性.而且,IBM 3 ...
- vlan端口隔离配置
对于大型网络来说,vlan是一种不错的解决办法,但对于有些项目,项目本身不需要不同vlan之间进行互访,比如有些监控项目就只需要内网访问,那么就没有必要创建vlan了,用户如果还将不同的端口划入不同的 ...
- HIve的基本使用
WHERE从表中筛选行: SELECT从表中查询指定的列: group by在列上做聚合. -- 假设数据文件的内容,字段之间以ASCII 001(ctrl-A)分隔,行之间以换行分隔. CREATE ...
- 在Ubuntu 内安装spin
相关课程:协议分析与设计 虽然一些镜像仓库内提供了spin,并且可以直接使用apt 或者yum 安装,但其版本总不是最新的,而且无法使用ispin 图形界面.因此本文介绍了手动下载编译spin 的步骤 ...
- Redis安装以及常见问题
安装 下载 redis官网地址:https://redis.io/ centos安装 创建软件放置目录mkdir soft 进入soft目录并下载redis安装包. cd soft wget http ...
- 痞子衡嵌入式:IAR内部C-SPY调试组件配套宏文件(.mac)用法介绍
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家分享的是IAR内部C-SPY调试组件配套宏文件(.mac)用法. 痞子衡之前写过一篇 <JLink Script文件基础及其在IAR下调用 ...
- 抖音网页版高清视频抓取教程selenium
废话不多说,直接上代码 from selenium import webdriver from selenium.webdriver import ChromeOptions import time ...
- bzoj4596/luoguP4336 [SHOI2016]黑暗前的幻想乡(矩阵树定理,容斥)
bzoj4596/luoguP4336 [SHOI2016]黑暗前的幻想乡(矩阵树定理,容斥) bzoj Luogu 题解时间 看一看数据范围,求生成树个数毫无疑问直接上矩阵树定理. 但是要求每条边都 ...
- CF1556F Sports Betting (状压枚举子集DP)
F 对于一张比赛图,经过缩点,会得到dag,且它一定是transitive的,因此我们能直接把比赛图缩成一个有向链.链头作为一个强连通分量,里面的所有点都是胜利的 定义F(win)表示win集合作为赢 ...