【Kaggle】如何有效避免OOM(out of memory)和漫长的炼丹过程
本文介绍一些避免transformers的OOM以及训练等流程太漫长的方法,主要参考了kaggle notebook Optimization approaches for Transformers | Kaggle,其中梯度累积Gradient Accumulation,冻结Freezing已经在之前的博客中介绍过,本文会依次介绍混合精度训练Automatic Mixed Precision, 8-bit Optimizers, and 梯度检查点Gradient Checkpointing, 然后介绍一些NLP专用的方法,比如Dynamic Padding, Uniform Dynamic Padding, and Fast Tokenizers.
Automatic Mixed Precision
作用:不损失最终质量的情况下减少内存消耗和训练时间
关键思想:是使用较低的精度将模型的梯度和参数保持在memory中,即不是使用全精度 (例如float32),而是使用半精度 (例如float16) 将张量保持在memory中。但是,当以较低的精度计算梯度时,某些值可能很小,以至于它们被视为零,这种现象称为 “overflow”。为了防止 “overflow溢出”,原始论文的作者提出了一种梯度缩放方法。
PyTorch提供了一个具有必要功能 (从降低精度到梯度缩放) 的软件包,用于使用自动混合精度,称为torch.cuda.amp。自动混合精度可以轻松地将其插入训练和推理代码中。
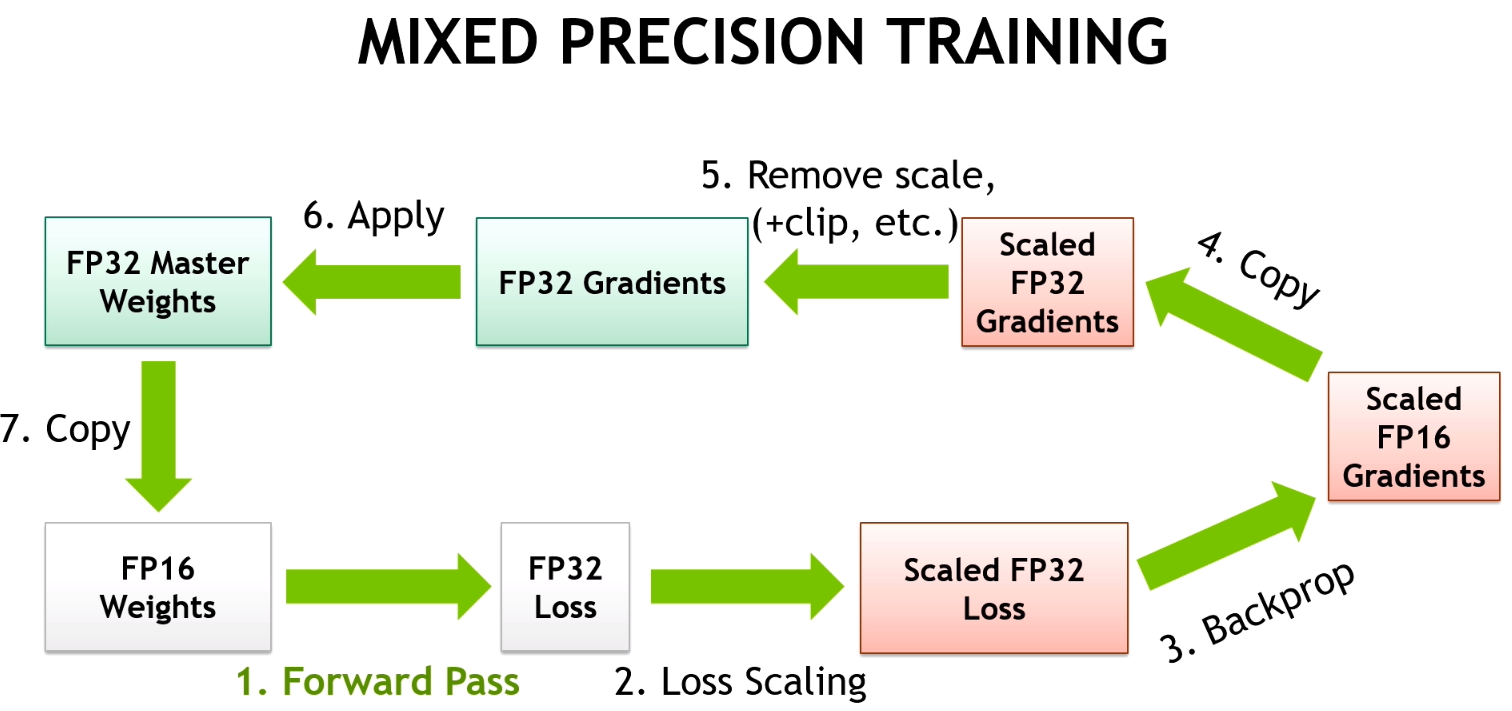
Vanilla training loop
for step, batch in enumerate(loader, 1):
# prepare inputs and targets for the model and loss function respectively.
# forward pass
outputs = model(inputs)
# computing loss
loss = loss_fn(outputs, targets)
# backward pass
loss.backward()
# perform optimization step
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
optimizer.step()
model.zero_grad()
Training loop with Automatic Mixed Precision
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
for step, batch in enumerate(loader, 1):
# prepare inputs and targets for the model and loss function respectively.
# forward pass with `autocast` context manager!!
with autocast(enabled=True):
outputs = model(inputs)
# computing loss
loss = loss_fn(outputs, targets)
# scale gradint and perform backward pass!!
scaler.scale(loss).backward()
# before gradient clipping the optimizer parameters must be unscaled.!!
scaler.unscale_(optimizer)
# perform optimization step
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
scaler.step(optimizer)
scaler.update()
8-bit Optimizers
8位优化器的思想类似于自动混合精度,其中模型的参数和梯度保持在较低的精度,但8位优化器还将优化器的状态保持在较低的精度。https://arxiv.org/abs/2110.02861作者表明8位优化器显著降低了内存利用率,略微加快了训练速度。此外,作者研究了不同超参数设置的影响,并表明8位优化器对不同的学习速率、beta和权重衰减参数的选择是稳定的,不会损失性能或损害收敛性。因此,作者为8位优化器提供了一个高级库,称为bitsandbytes。
Initializing optimizer via PyTorch API
import torch
from transformers import AutoConfig, AutoModel
# initializing model
model_path = "microsoft/deberta-v3-base"
config = AutoConfig.from_pretrained(model_path)
model = AutoModel.from_pretrained(model_path, config=config)
# selecting parameters, which requires gradients
model_parameters = filter(lambda parameter: parameter.requires_grad, model.parameters())
# initializing optimizer
optimizer = torch.optim.AdamW(params=model_parameters, lr=2e-5, weight_decay=0.0)
print(f"32-bit Optimizer:\n\n{optimizer}")
32-bit Optimizer:
AdamW (
Parameter Group 0
amsgrad: False
betas: (0.9, 0.999)
eps: 1e-08
lr: 2e-05
maximize: False
weight_decay: 0.0
)
Initializing optimizer via bitsandbytes API
!pip install -q bitsandbytes-cuda110
def set_embedding_parameters_bits(embeddings_path, optim_bits=32):
"""
https://github.com/huggingface/transformers/issues/14819#issuecomment-1003427930
"""
embedding_types = ("word", "position", "token_type")
for embedding_type in embedding_types:
attr_name = f"{embedding_type}_embeddings"
if hasattr(embeddings_path, attr_name):
bnb.optim.GlobalOptimManager.get_instance().register_module_override(
getattr(embeddings_path, attr_name), 'weight', {'optim_bits': optim_bits}
)
import bitsandbytes as bnb
# selecting parameters, which requires gradients
model_parameters = filter(lambda parameter: parameter.requires_grad, model.parameters())
# initializing optimizer
bnb_optimizer = bnb.optim.AdamW(params=model_parameters, lr=2e-5, weight_decay=0.0, optim_bits=8)
# bnb_optimizer = bnb.optim.AdamW8bit(params=model_parameters, lr=2e-5, weight_decay=0.0) # equivalent to the above line
# setting embeddings parameters
set_embedding_parameters_bits(embeddings_path=model.embeddings)
print(f"8-bit Optimizer:\n\n{bnb_optimizer}")
8-bit Optimizer:
AdamW (
Parameter Group 0
betas: (0.9, 0.999)
eps: 1e-08
lr: 2e-05
weight_decay: 0.0
)
Gradient Checkpointing
有时,即使使用小批量和其他优化技术,例如梯度累积、冻结或自动精度训练,我们仍然可能耗尽内存,尤其是在模型足够大的情况下。作者证明了梯度检查点可以显著地将内存利用率从\(O(n)\)降低到\(O(\sqrt{n})\),其中n是模型中的层数。这种方法实现了在单个GPU上训练大型模型,或提供更多内存以增加批处理大小,从而更好更快地收敛。
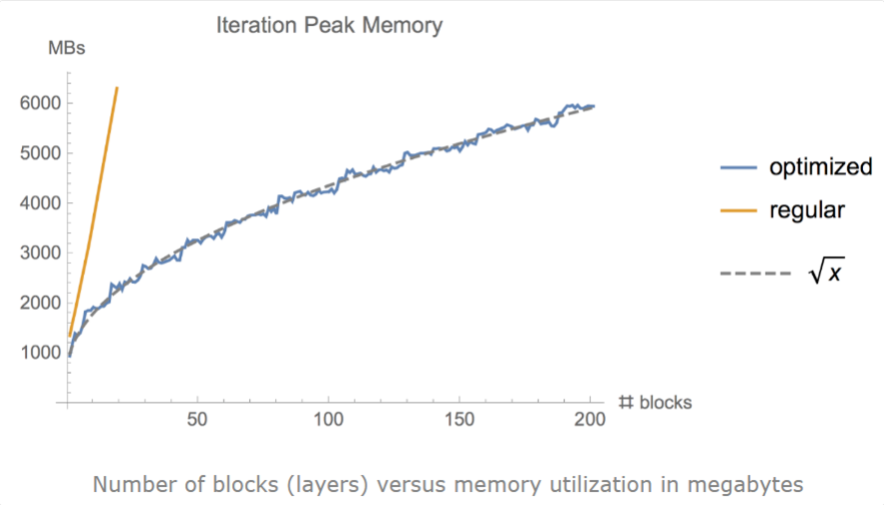
梯度检查点背后的思想是计算小块中的梯度,同时在正向和反向传播过程中从内存中删除不必要的梯度,从而降低内存利用率,尽管这种方法需要更多的计算步骤来再现整个反向传播计算图。
pytorch提供了torch.utils.checkpoint.checkpoint 和 torch.utils.checkpoint.checkpoint_sequential 函数来实现梯度检查点。
"Specifically, in the forward pass, function will run in torch.no_grad() manner, i.e., not storing the intermediate activations. Instead, the forward pass saves the inputs tuple and the function parameter. In the backwards pass, the saved inputs and function is retrieved, and the forward pass is computed on function again, now tracking the intermediate activations, and then the gradients are calculated using these activation values."
另外,huggingface同样支持梯度检查点,可以对PreTrainedModel instance使用gradient_checkpointing_enable 方法。
代码实现
from transformers import AutoConfig, AutoModel
# https://github.com/huggingface/transformers/issues/9919
from torch.utils.checkpoint import checkpoint
# initializing model
model_path = "microsoft/deberta-v3-base"
config = AutoConfig.from_pretrained(model_path)
model = AutoModel.from_pretrained(model_path, config=config)
# gradient checkpointing
model.gradient_checkpointing_enable()
print(f"Gradient Checkpointing: {model.is_gradient_checkpointing}")
Gradient Checkpointing: True
Fast Tokenizers
base和fast tokenizer的区别:fast是在rust编写的,因为python在循环中非常慢,fast可以让我们在tokenize时获得额外的加速。下图是tokenize工作的原理示意,Tokenizer类型可以通过更改 transformers.AutoTokenizer from_pretrained 将 use_fast 属性设为True。

代码实现
from transformers import AutoTokenizer
# initializing Base version of Tokenizer
model_path = "microsoft/deberta-v3-base"
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
print(f"Base version Tokenizer:\n\n{tokenizer}", end="\n"*3)
# initializing Fast version of Tokenizer
fast_tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=True)
print(f"Fast version Tokenizer:\n\n{fast_tokenizer}")
Base version Tokenizer:
PreTrainedTokenizer(name_or_path='microsoft/deberta-v3-base', vocab_size=128000, model_max_len=1000000000000000019884624838656, is_fast=False, padding_side='right', truncation_side='right', special_tokens={'bos_token': '[CLS]', 'eos_token': '[SEP]', 'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'})
Fast version Tokenizer:
PreTrainedTokenizerFast(name_or_path='microsoft/deberta-v3-base', vocab_size=128000, model_max_len=1000000000000000019884624838656, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'bos_token': '[CLS]', 'eos_token': '[SEP]', 'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'})
Dynamic Padding
即对输入的mini batch动态进行padding,将batch的输入填充到该batch的最大输入长度,可以将训练速度提高35%甚至50%,注意,pad token不应包括在某些任务(比如MLM和NER)的损失计算过程中。
Uniform Dynamic Padding
这是基于动态填充的方法,其思想是预先按文本的相应长度对文本进行排序,在训练或推理期间比动态填充需要更少的计算。但不建议在训练期间使用统一的动态填充,因为训练意味着输入的shuffle。
【Kaggle】如何有效避免OOM(out of memory)和漫长的炼丹过程的更多相关文章
- mat 使用 分析 oom 使用 Eclipse Memory Analyzer 进行堆转储文件分析
概述 对于大型 JAVA 应用程序来说,再精细的测试也难以堵住所有的漏洞,即便我们在测试阶段进行了大量卓有成效的工作,很多问题还是会在生产环境下暴露出来,并且很难在测试环境中进行重现.JVM 能够记录 ...
- Android中内存泄露与如何有效避免OOM总结
一.关于OOM与内存泄露的概念 我们在Android开发过程中经常会遇到OOM的错误,这是因为我们在APP中没有考虑dalvik虚拟机内存消耗的问题. 1.什么是OOM OOM:即OutOfMemoe ...
- 【干货】Kaggle 数据挖掘比赛经验分享(mark 专业的数据建模过程)
简介 Kaggle 于 2010 年创立,专注数据科学,机器学习竞赛的举办,是全球最大的数据科学社区和数据竞赛平台.笔者从 2013 年开始,陆续参加了多场 Kaggle上面举办的比赛,相继获得了 C ...
- 由Kaggle竞赛wiki文章流量预测引发的pandas内存优化过程分享
pandas内存优化分享 缘由 最近在做Kaggle上的wiki文章流量预测项目,这里由于个人电脑配置问题,我一直都是用的Kaggle的kernel,但是我们知道kernel的内存限制是16G,如下: ...
- Android 内存管理 &Memory Leak & OOM 分析
转载博客:http://blog.csdn.net/vshuang/article/details/39647167 1.Android 进程管理&内存 Android主要应用在嵌入式设备当中 ...
- Android 内存管理 &Memory Leak & OOM 分析
1.Android 流程管理&内存 Android主要应用在嵌入式设备其中.而嵌入式设备因为一些众所周知的条件限制,通常都不会有非常高的配置,特别是内存是比較有限的. 假设我们编写的代 码其中 ...
- Linux 理解Linux的memory overcommit 与 OOM Killer
Memory Overcommit的意思是操作系统承诺给进程的内存大小超过了实际可用的内存.一个保守的操作系统不会允许memory overcommit,有多少就分配多少,再申请就没有了,这其实有些浪 ...
- Java 性能优化实战记录(3)--JVM OOM的分析和原因追查
前言: C/C++的程序员渴望Java的自由, Java程序员期许C/C++的约束. 其实那里都是围城, 外面的人想进来, 里面的人想出去. 背景: 作为Java程序员, 除了享受垃圾回收机制带来的便 ...
- 深挖android low memory killer
对于PC来说,内存是至关重要.如果某个程序发生了内存泄漏,那么一般情况下系统就会将其进程Kill掉.Linux中使用一种名称为OOM(Out Of Memory,内存不足)的机制来完成这个任务,该机制 ...
随机推荐
- kill -9 进程杀不掉,怎么办?
关注「开源Linux」,选择"设为星标" 回复「学习」,有我为您特别筛选的学习资料~ 用ps和grep命令寻找僵尸进程 ps -A -ostat,ppid,pid,cmd | gr ...
- data structure assignment problem record
Question1: Similar to pause command in linux read -n 1 Question2 read : Illegal option -n 原因为ubuntu ...
- 论文解读(ClusterSCL)《ClusterSCL: Cluster-Aware Supervised Contrastive Learning on Graphs》
论文信息 论文标题:ClusterSCL: Cluster-Aware Supervised Contrastive Learning on Graphs论文作者:Yanling Wang, Jing ...
- 使用BGP-blackhole解决IDC频繁遭受DDOS攻击困扰
项目背景 该项目位于某市级BGP IDC机房,机房客户多为web业务,遭受小流量攻击(10G量级)较为频繁,针对这一现象在机房core旁路部署ADS系统,牵引异常流量清洗后进行回源,该清洗方案在此不再 ...
- zabbix 线路质量监控自定义python模块(Mysql版),多线程(后来发现使用协程更好)降低系统消耗
之前零零碎碎写了一些zabbix 线路监控的脚本,工作中agnet较多,每条线路监控需求不一致,比较杂乱,现在整理成一个py模块,集合之前的所有功能 环境 python3.6以上版本,pip3(pip ...
- Redis集群高频问答,连夜肝出来了
Redis 集群方案 Redis集群方案应该怎么做?都有哪些方案? 使用codis方案:目前用的多的集群方案,基本和twemproxy一致的效果,但它支持在节点数量改变情况下,旧节点数据可恢复到新h ...
- python之数据类型的内置方法(set、tuple、dict)与简单认识垃圾回收机制
目录 字典的内置方法 类型转换 字典取值 修改值 计算字典长度 成员运算 删除元素 获取元素 更新字典 快速生成字典 setdefault()方法 元组的内置方法 类型转换 索引与切片操作 统计长度 ...
- 源码解读etcd heartbeat,election timeout之间的拉锯
转一个我在知乎上回答的有关raft election timeout/ heartbeat interval 的回答吧. 答:准确来讲: election是timeout,而heartbeat 是in ...
- MySQL之事务隔离级别和MVCC
事务隔离级别 事务并发可能出现的问题 脏写 事务之间对增删改互相影响 脏读 事务之间读取其他未提交事务的数据 不可重复读 一个事务在多次执行一个select读到的数据前后不相同.因为被别的未提交事务修 ...
- Spring Authorization Server(AS)从 Mysql 中读取客户端、用户
Spring AS 持久化 jdk version: 17 spring boot version: 2.7.0 spring authorization server:0.3.0 mysql ver ...