GPS地图生成03之数据获取
1. 引言¶
六只脚是国内著名的户外网站,拥有大量的户外GPS轨迹路线,网址为:http://www.foooooot.com/ 
2. 数据分析¶
2.1 获取所有轨迹¶
搜索关键词岳麓山:
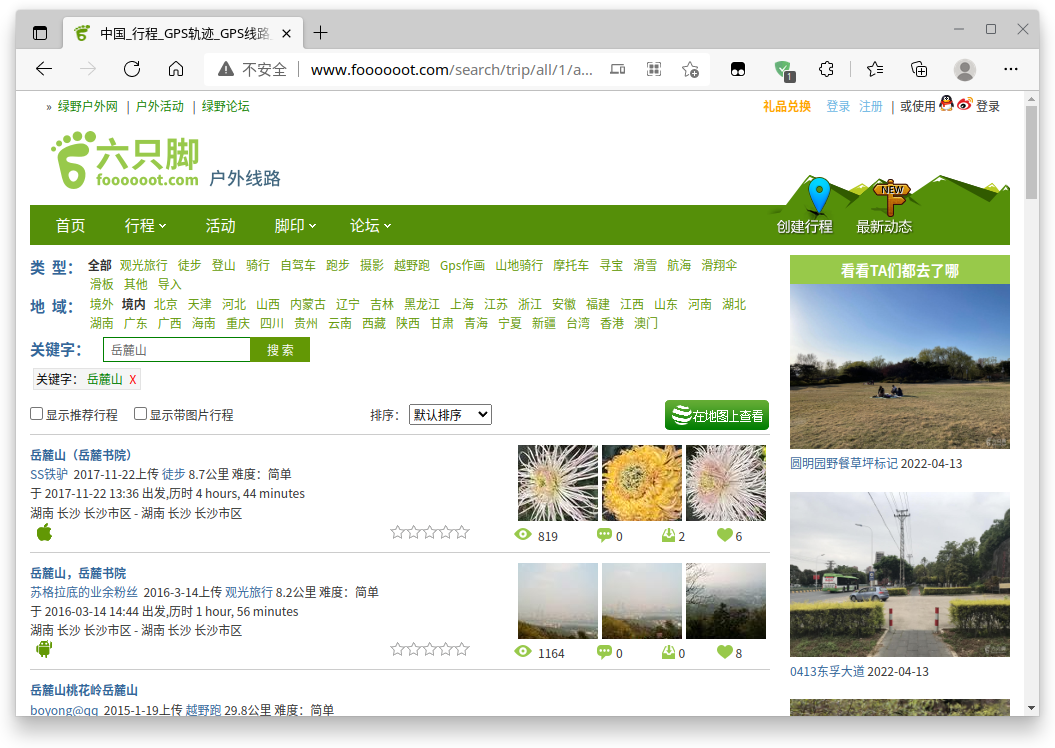
可以发现,每页具有三十个轨迹记录
观察第二页的网址我们可以发现网址为:http://www.foooooot.com/search/trip/all/1/all/time/descent/?page=2&keyword=%E5%B2%B3%E9%BA%93%E5%B1%B1 不难发现其规律:
- page为页数
- keyword为
岳麓山的转义
我们不妨测试page为50的情况,在浏览器输入http://www.foooooot.com/search/trip/all/1/all/time/descent/?page=50&keyword=%E5%B2%B3%E9%BA%93%E5%B1%B1:
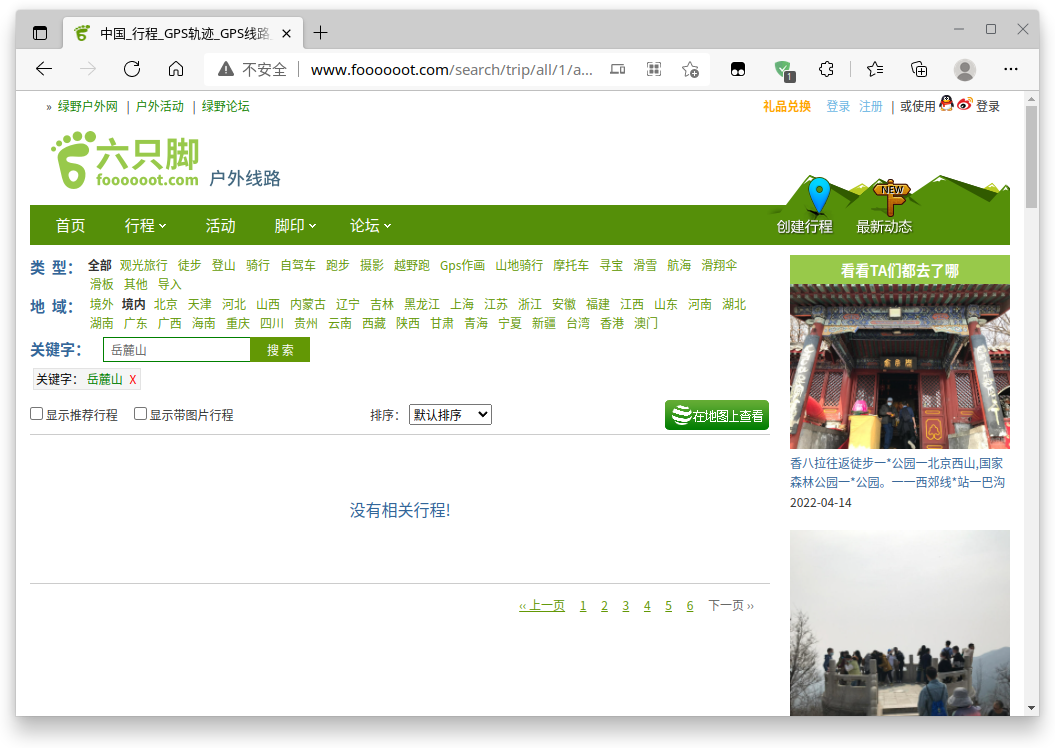
小结:我们可以通过不断增加page的数字,直至某一页不满足三十个轨迹记录,获取该关键词所有的轨迹记录
2.2 获取轨迹ID¶
点击某个具体的轨迹详情:
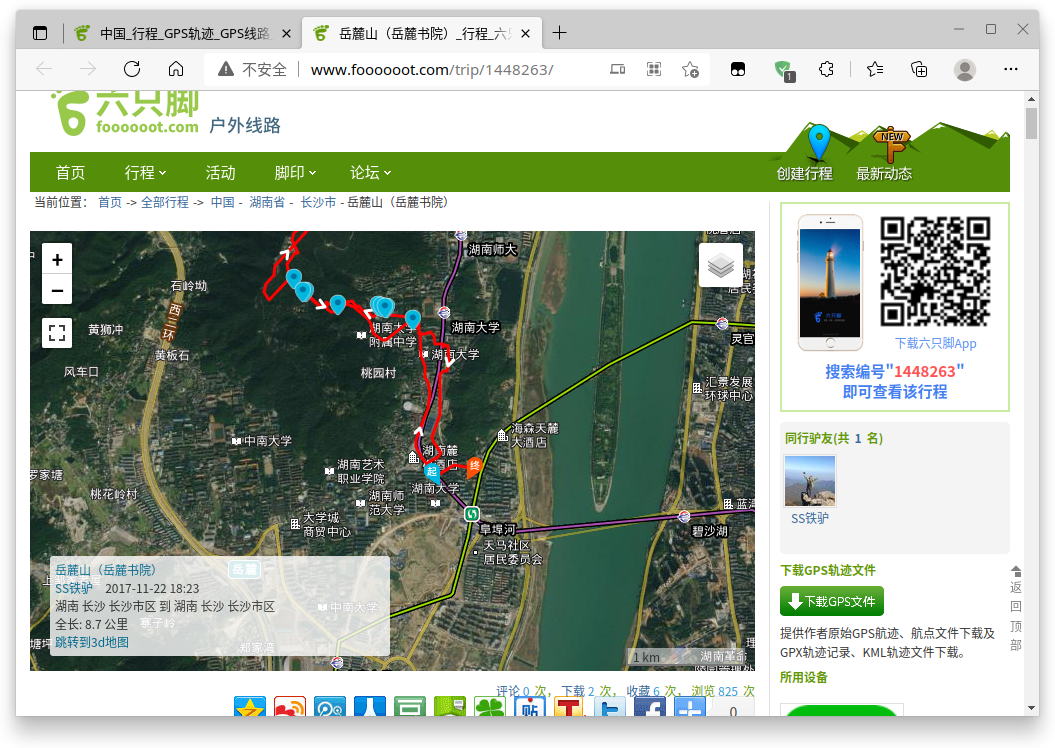
可以看到每一页具体的轨迹页面的网址是由轨迹ID构造的,诸如:http://www.foooooot.com/trip/1448263/
从刚才的列表界面我们就可以找到每个轨迹ID:
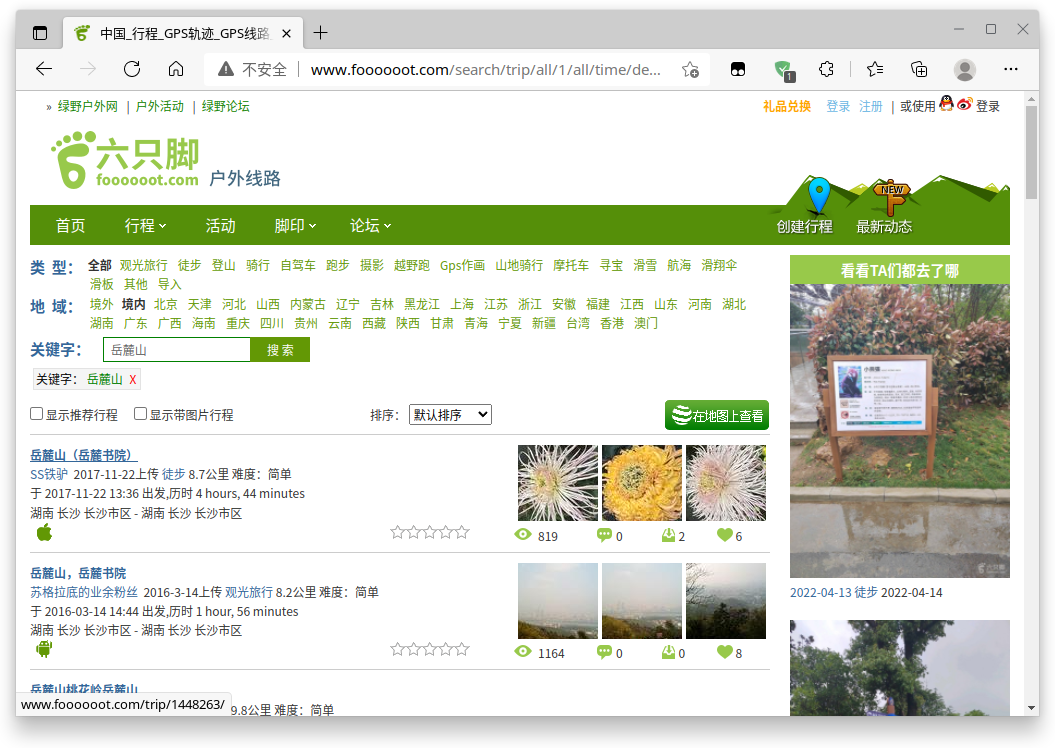
2.3 获取轨迹数据¶
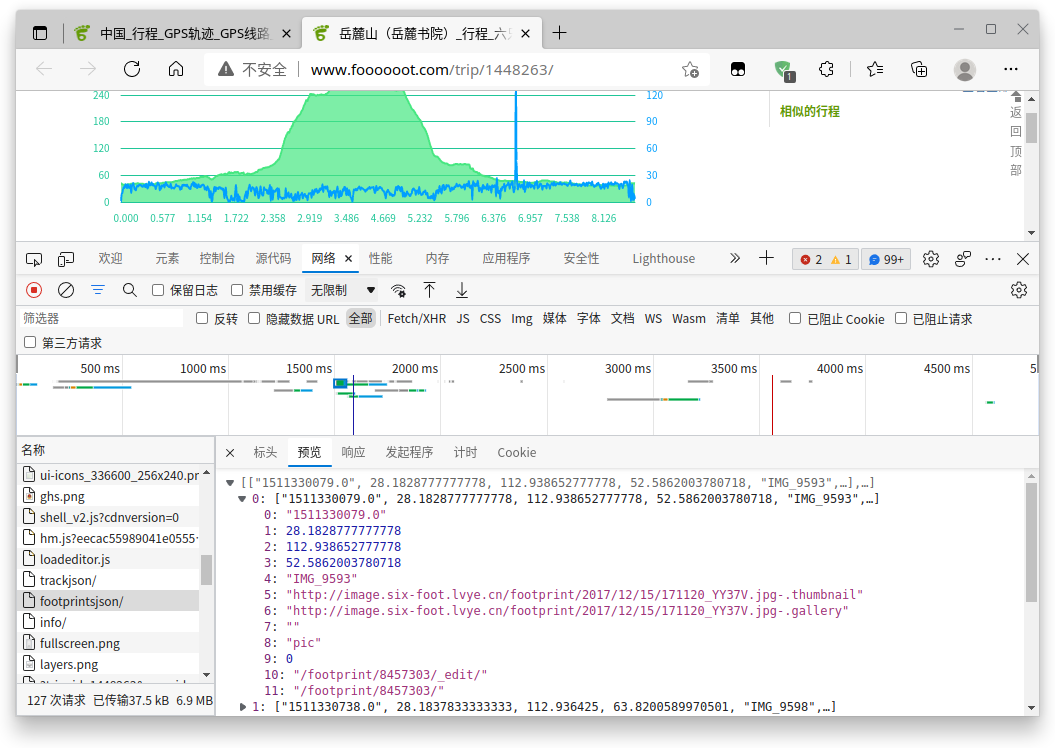
我们打开浏览器控制台(按F12),点击到网络记录界面,刷新网址:
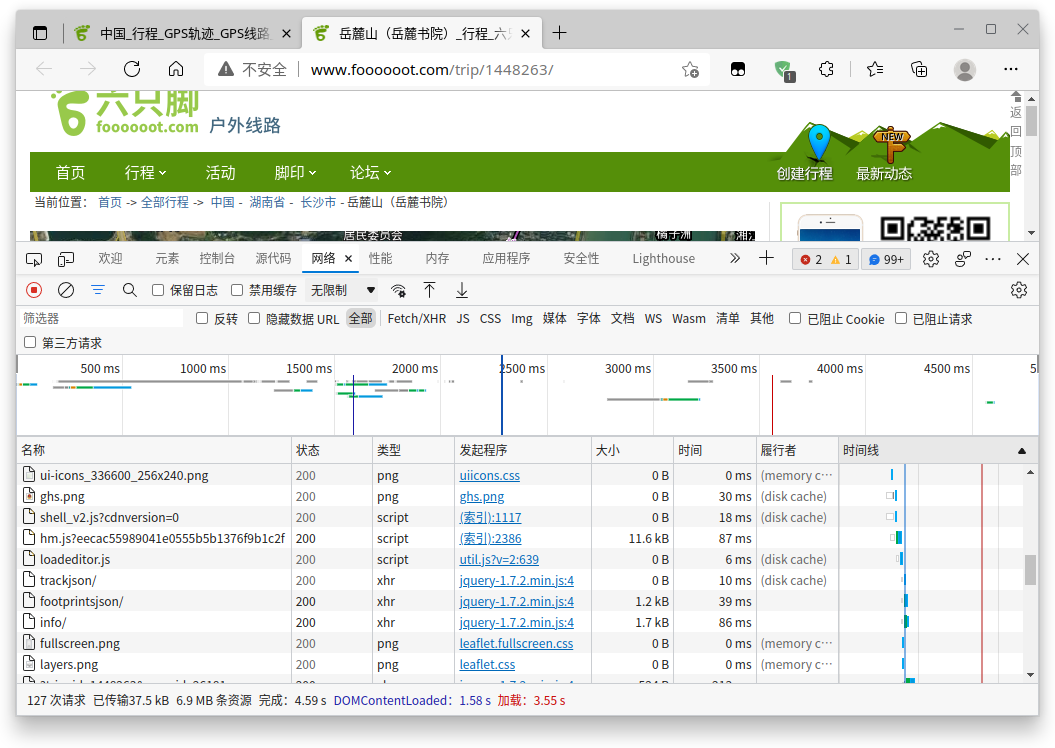
从网络请求记录中我们发现有两个XHR异步请求其名字很像轨迹数据,点开查看:
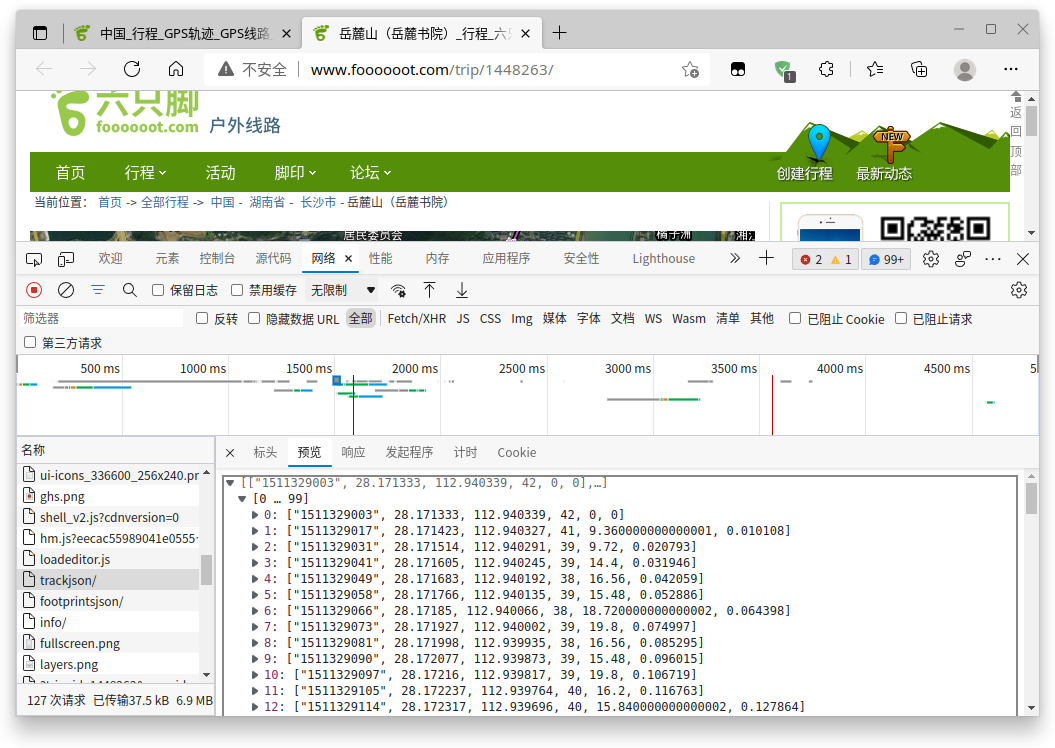
可以看到,这个trackjson就是轨迹的JSON数据:
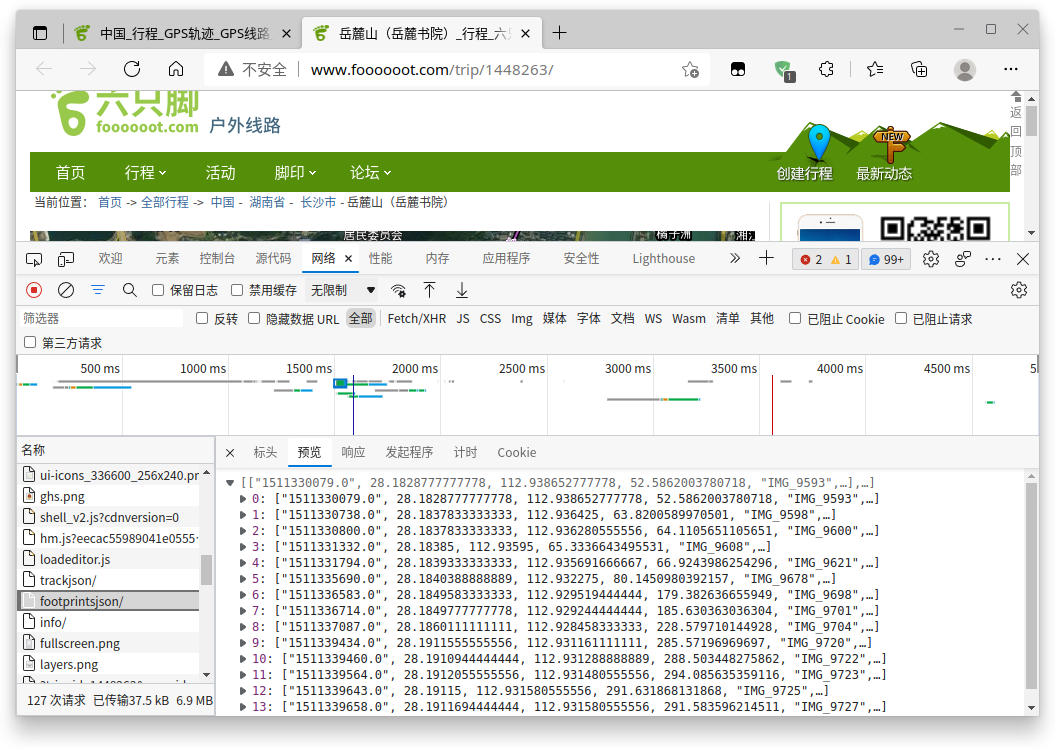
这个footprintsjson就是足迹数据,也就是拍照的那种数据:
2.4 字段解释¶
对于trackjson,前三列个数据项可以快速判断为时间戳和经纬度,对于后面三个数据项,结合网页数据:
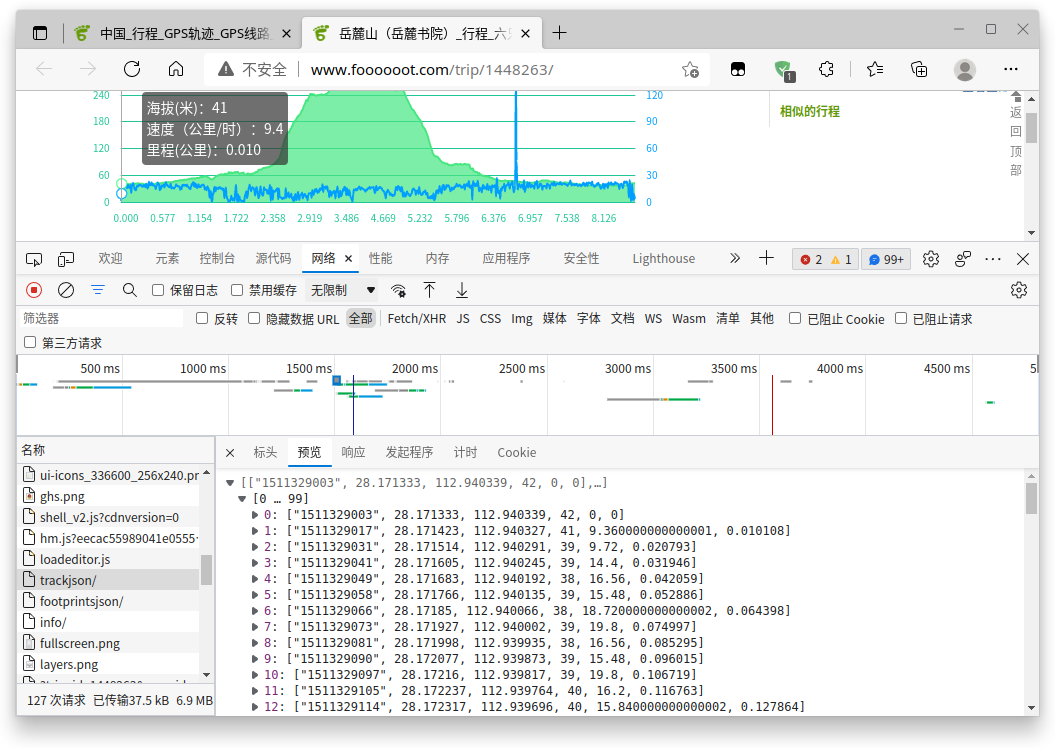
可以判断分别为高程,速度和里程
对于footprintsjson,可以判断前几列数据项分别为时间戳、经纬度、高程、名字、缩略图、详情图,后面几项笔者认为没啥作用
3. 数据爬取¶
经过上面的数据分析,爬取轨迹数据主要就是通过page和keyword构造网址获取轨迹ID,通过轨迹ID构造地址获取trackjson和footprintsjson
笔者此处基于Python,使用requests库发送http请求,使用Xpath解析界面提取数据
3.1 引入库¶
import requests
from lxml import etree
import json
import time- 注意: 如果缺少相关库,请使用pip或者conda安装
3.2 获取所有轨迹ID¶
page_num = 1
track_num_arr = []
keyword = "岳麓山"
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'}
page_url = "http://www.foooooot.com/search/trip/all/1/all/time/descent/?page=" + str(page_num) + "&keyword=" + keyword- 注意:发起请求请务必设置休眠时间,瞬间的大量访问请求会导致网站崩溃
- 目前此网站设置了简易反爬措施,不设置'user-agent'将 无法访问
next_page = True
while(next_page):
response = requests.get(page_url,timeout=5, headers=headers)
tree = etree.HTML(response.text)
trip_list = tree.xpath('//p[@class="trip-title"]/a/@href')
if(len(trip_list) == 30):
page_num = page_num + 1
page_url = "http://www.foooooot.com/search/trip/all/1/all/time/descent/?page=" + str(page_num) + "&keyword=" + keyword
else:
next_page = False
for trip in trip_list:
track_num_arr.append(trip.split('/')[2])
time.sleep(6)print(len(track_num_arr))1170可以看到有1170条轨迹数据
3.3 获取轨迹数据¶
num = 0
for track_num in track_num_arr:
try:
#设置重连次数
requests.adapters.DEFAULT_RETRIES = 5
s = requests.session()
# 设置连接活跃状态为False
s.keep_alive = False
time.sleep(6)
footprint_url = "http://www.foooooot.com/trip/" + str(track_num) + "/footprintsjson/"
trackjson_url = "http://www.foooooot.com/trip/" + str(track_num) + "/trackjson/"
footprint_res = requests.get(footprint_url,headers=headers,stream=False,timeout= 10)
trackjson_res = requests.get(trackjson_url,headers=headers,stream=False,timeout= 10)
try:
trackjson = json.loads(trackjson_res.text)
footprint = json.loads(footprint_res.text)
with open("./trackdata/origin/trackjson" + str(track_num) + ".json","w") as tf:
json.dump(trackjson,tf)
with open("./trackdata/origin/footprint" + str(track_num) + ".json","w") as ff:
json.dump(footprint,ff)
for track in trackjson:
with open("./trackdata/trip_" + str(track_num) + ".txt","a") as tf:
tf.write(str(track[1]) + " " + str(track[2]) + " " + str(track[3]) + " " + str(int(track[0])) + "\n")
with open("./trackdata/all.csv","a") as af:
af.write(str(num) + "," + str(track[2]) + "," + str(track[1]) + "," + str(track[3]) + "," + str(track_num) + "," + str(int(track[0])) + "\n")
num = num + 1
# print("DONE: " + track_num)
# 关闭请求 释放内存
footprint_res.close()
trackjson_res.close()
del(footprint_res)
del(trackjson_res)
except Exception as we:
print(we)
print("ERROR: " + track_num)
with open("./trackdata/error.txt","a") as af:
af.write(str(track_num) + '\n')
# 关闭请求 释放内存
footprint_res.close()
trackjson_res.close()
del(footprint_res)
del(trackjson_res)
except Exception as ce:
print(ce)
time.sleep(60)Expecting value: line 1 column 1 (char 0)
ERROR: 3541376
Expecting value: line 1 column 1 (char 0)
ERROR: 3541373
Expecting value: line 1 column 1 (char 0)
ERROR: 3541372
Expecting value: line 1 column 1 (char 0)
ERROR: 3541371
Expecting value: line 1 column 1 (char 0)
ERROR: 3541430
Expecting value: line 1 column 1 (char 0)
ERROR: 3505289
Expecting value: line 1 column 1 (char 0)
ERROR: 5135959
Expecting value: line 1 column 1 (char 0)
ERROR: 3390423
Expecting value: line 1 column 1 (char 0)
ERROR: 3389498
Expecting value: line 1 column 1 (char 0)
ERROR: 3392149
Expecting value: line 1 column 1 (char 0)
ERROR: 3392065
Expecting value: line 1 column 1 (char 0)
ERROR: 3392040- 笔者遇到过IO错误和连接错误,所以用try except包裹起来,但是两层try总觉得不对劲
- trip_track_num.txt 这个文件写法主要是参考map construction的轨迹文件
- 经笔者验证,
ERROR的那几个轨迹确实没有数据
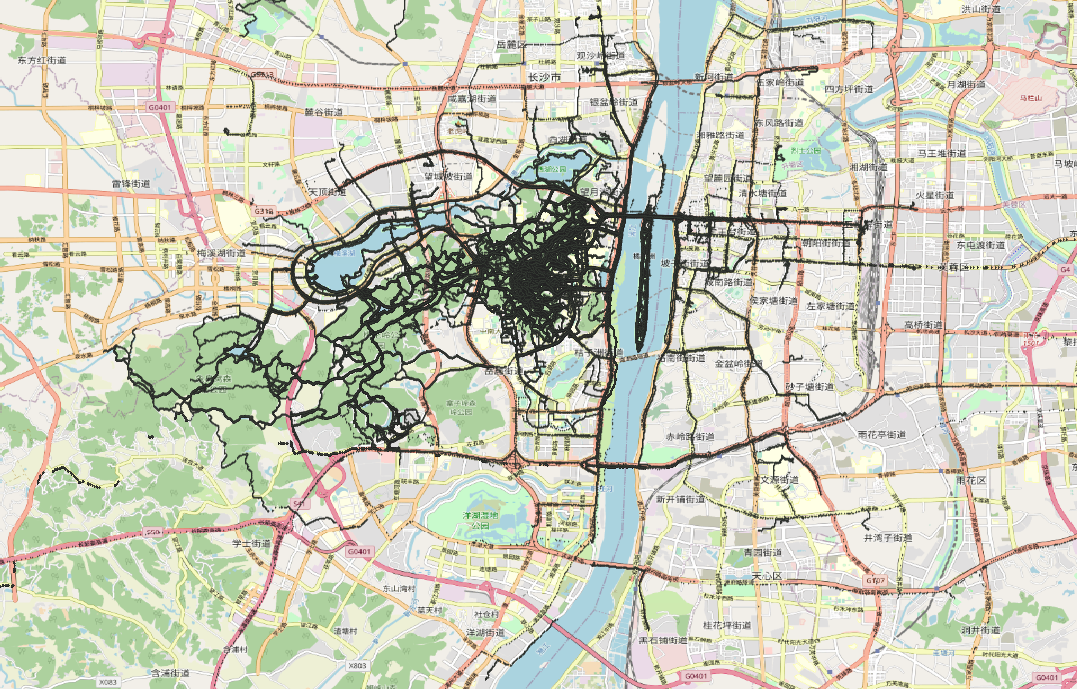
4. 可视化¶
在QGIS中利用加载XY文件的方式加载all.csv文件,并设置OSM底图,预览GPS轨迹:
GPS地图生成03之数据获取的更多相关文章
- unity3d WorldComposer1 卫星地图生成地形
http://blog.csdn.net/myarrow/article/details/42709113 1. 简介 1.1 TerrainComposer(TC) 一个Unity扩展工具,可用于创 ...
- Android百度地图开发03之地图控制 + 定位
前两篇关于百度地图的blog写的是,一些基本图层的展示 和 覆盖物的添加+地理编码和反地理编码. 接下来,这篇blog主要说一些关于地图控制方面的内容和定位功能. 百度地图提供的关于地图的操作主要有: ...
- iPhone手机GPS地图位置好帮手
十一国庆黄金周近在眉睫,我先祝大家过一个愉快开心的国庆长假. 假期内,难免老友聚会吃饭聊天联络感情,年轻朋友相亲约会,一家人出门旅游.平时,我们聚会时,总有要来的人找不到聚会地点,需要反复打电话确认: ...
- RaceWeb介绍(7):由500强公司数据高速生成百度地图——生成坐标字段及坐标数据
接上篇. 一.生成X坐标.Y坐标两个字段. 我们须要为每一个公司建立X坐标和Y坐标字段,用来保存XY坐标. 既然为了突出"快",这一步就有程序来完毕吧. 右键单击"世界5 ...
- echarts使用------地图生成----省市地图的生成及其他相关细节调整
为使用多种业务场景,百度echarts地图示例只有中国地图,那么在使用省市地图的时候,就需要我们使用省市的地图数据了 以下为陕西西安市的地图示例: 此页面引用echarts的js:http://ech ...
- Unity 随机房间地图生成
无论是在迷宫还是类似于地牢的游戏地图中,利用程序来生成每次都不一样的地图是一件叫人兴奋不已的事. 这时我们需要解决两个非常重要的随机事件: 1.在一定范围内随机出各不相同但又不能互相重叠的房间 2.优 ...
- 帝国CMS网站地图生成插件
可以生成电脑端也可以生成手机端的地图XML. 安装方法: 这个帝国sitemap插件的安装跟其他插件的安装方式一样,介于可能有人不会安装帝国的插件,就写一下吧,以后你们如果碰到帝国插件也可以参考这个. ...
- Unity3d 随机地图生成
2D解析图: 3D地形: 嘿嘿.
- gps 地图
http://www.cnblogs.com/sylvanas2012/p/5342530.html http://blog.csdn.net/ma969070578/article/details/ ...
- unity2018使用tileMap生成地图 类似泰拉瑞亚创建和销毁地图块
参考网站:https://blog.csdn.net/pz789as/article/details/79540890 using System.Collections; using System.C ...
随机推荐
- 【Hadoop面试】基础概念、HDFS、MapReduce、Yarn、实战
一.Hadoop概念及架构 1.是否看过Hadoop源码 2.正常工作的hadoop集群中hadoop都分别需要启动哪些进程,他们的作用分别是什么 3.hadoop和spark中的文件缓存方式 4.h ...
- Velero 系列文章(一):基础
概述 Velero 是一个开源工具,可以安全地备份和还原,执行灾难恢复以及迁移 Kubernetes 集群资源和持久卷. 灾难恢复 Velero 可以在基础架构丢失,数据损坏和/或服务中断的情况下,减 ...
- Jenkins&&gitlab2
Jenkins slave 添加jenkins slave节点: jenkins slave节点创建工作目录与基本环境配置,如果jenkins slave节点需要clone代码和执行java 代码编 ...
- 封装一个python的pymysql操作类
最近使用pymysql写脚本的情况越来越多了,刚好整理,简单封装一个pymysql的操作类 import pymysql class MysqlDB: def __init__( self, host ...
- go_json_learn
解析嵌套类型示例: func test3() { b := []byte(`{"Name":"tom","Age":20,"Ema ...
- [常用工具] shell脚本快速入门笔记
Shell 是一个用 C 语言编写的程序,它是用户使用 Linux 的桥梁.Shell 脚本(shell script),是一种为 shell 编写的脚本程序.业界所说的 shell 通常都是指 sh ...
- vulnhub靶场之FUNBOX: UNDER CONSTRUCTION!
准备: 攻击机:虚拟机kali.本机win10. 靶机:Funbox: Under Construction!,下载地址:https://download.vulnhub.com/funbox/Fun ...
- 应用容器引擎-Docker
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux或Windows操作系统的机器上,也可以实现虚拟化.容器是完全使用沙箱 ...
- 网络通讯协议分类-IP地址
网络通讯协议分类 通信的协议还是比较复杂的,java.net包中包含的类和接口,它们提供低层次的通信细节.我们可以直接使用这些类和接口,来专注于网络程序开发,而不用考虑通信的细节. java.net包 ...
- Java语言的跨平台性-JDK,JRE和JVM
Java语言的跨平台性 1 Java虚拟机--JVM JVM(Java Virtual Machine ):Java虚拟机,简称JVM,是运行所有Java程序的假想计算机,是Java程序的 运行环境, ...