Python的scrapy之爬取51job网站的职位
今天老师讲解了Python中的爬虫框架--scrapy,然后带领我们做了一个小爬虫--爬取51job网的职位信息,并且保存到数据库中
用的是Python3.6 pycharm编辑器
爬虫主体:
import scrapy
from ..items import JobspidersItem class JobsspiderSpider(scrapy.Spider):
name = 'jobsspider'
#allowed_domains = ['search.51job.com/list/010000,000000,0000,00,9,99,%2520,2,1.html']
#start_urls = ['https://search.51job.com/list/010000,000000,0000,00,9,99,%2520,2,1.html/']
start_urls = [
'https://search.51job.com/list/010000,000000,0000,01,9,99,python,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='] def parse(self, response):
currentPageItems = response.xpath('/html/body/div[@class="dw_wp"]/div[@class="dw_table"]/div[@class="el"]')
print(currentPageItems) # currentPageItems = response.xpath('//div[@class="el"]')
for jobItem in currentPageItems:
print('----',jobItem)
jobspidersItem = JobspidersItem() jobPosition = jobItem.xpath('p[@class="t1 "]/span/a/text()').extract()
if jobPosition:
#print(jobPosition[0].strip())
jobspidersItem['jobPosition'] = jobPosition[0].strip() jobCompany = jobItem.xpath('span[@class="t2"]/a/text()').extract()
if jobCompany:
#print(jobCompany[0].strip())
jobspidersItem['jobCompany'] = jobCompany[0].strip() jobArea = jobItem.xpath('span[@class="t3"]/text()').extract()
if jobArea:
#print(jobArea[0].strip())
jobspidersItem['jobArea'] = jobArea[0].strip() jobSale = jobItem.xpath('span[@class="t4"]/text()').extract()
if jobSale:
# print(jobCompany[0].strip())
jobspidersItem['jobSale'] = jobSale[0].strip() jobDate = jobItem.xpath('span[@class="t5"]/text()').extract()
if jobDate:
# print(jobCompany[0].strip())
jobspidersItem['jobDate'] = jobDate[0].strip() yield jobspidersItem # 通过yield 调用输出管道
pass
nextPageURL = response.xpath('//li[@class="bk"]/a/@href').extract() # 取下一页的地址
print(nextPageURL)
if nextPageURL:
url = response.urljoin(nextPageURL[-1])
print('url', url)
# 发送下一页请求并调用parse()函数继续解析
yield scrapy.Request(url, self.parse, dont_filter=False)
pass
else:
print("退出")
pass
items.py 设置五个items
import scrapy class JobspidersItem(scrapy.Item):
# define the fields for your item here like:
jobPosition = scrapy.Field()
jobCompany = scrapy.Field()
jobArea = scrapy.Field()
jobSale = scrapy.Field()
jobDate = scrapy.Field()
pass
pipelines.py 输出管道
class JobspidersPipeline(object):
def process_item(self, item, spider):
print('职位:', item['jobPosition'])
print('公司:', item['jobCompany'])
print('工作地点:', item['jobArea'])
print('薪资:', item['jobSale'])
print('发布时间:', item['jobDate'])
print('----------------------------')
return item
pipelinesmysql.py 输出到mysql中 第一行的意思是使用了以前封装的数据库操作类
from week5_day04.dbutil import dbutil # 作业: 自定义的管道,将完整的爬取数据,保存到MySql数据库中
class JobspidersPipeline(object):
def process_item(self, item, spider):
dbu = dbutil.MYSQLdbUtil()
dbu.getConnection() # 开启事物 # 1.添加
try:
#sql = "insert into jobs (职位名,公司名,工作地点,薪资,发布时间)values(%s,%s,%s,%s,%s)"
sql = "insert into t_job (jobname,jobcompany,jobarea,jobsale,jobdata)values(%s,%s,%s,%s,%s)"
#date = []
#dbu.execute(sql, date, True)
dbu.execute(sql, (item['jobPosition'],item['jobCompany'],item['jobArea'],item['jobSale'],item['jobDate']),True)
#dbu.execute(sql,True)
dbu.commit()
print('插入数据库成功!!')
except:
dbu.rollback()
dbu.commit() # 回滚后要提交
finally:
dbu.close()
return item
最终结果:
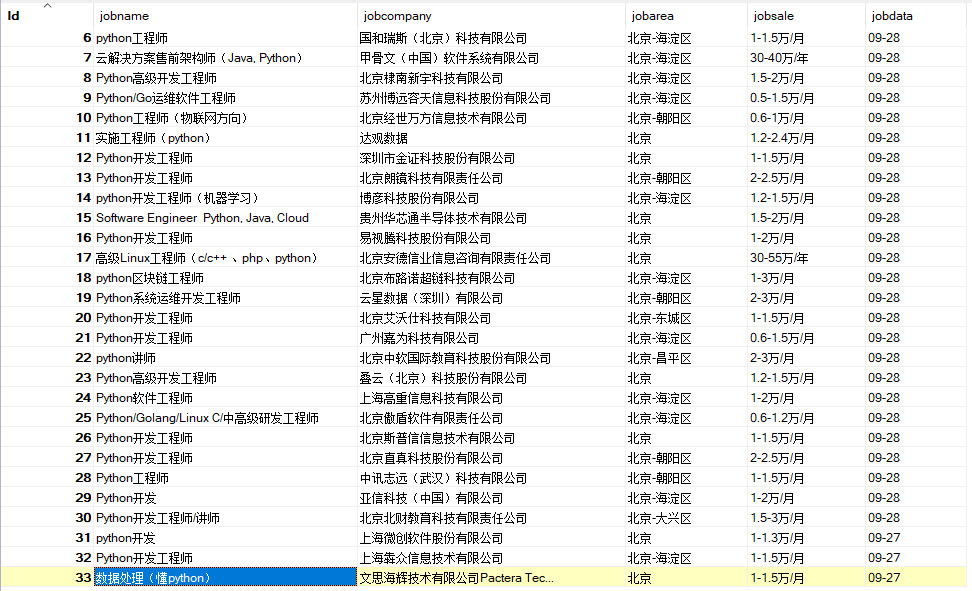
通过这个最基础的51job爬虫,进入到scrapy框架的学习中,这东西挺好使
Python的scrapy之爬取51job网站的职位的更多相关文章
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- 初识python 之 爬虫:爬取某网站的壁纸图片
用到的主要知识点:requests.get 获取网页HTMLetree.HTML 使用lxml解析器解析网页xpath 使用xpath获取网页标签信息.图片地址request.urlretrieve ...
- scrapy版本爬取某网站,加入了ua池,ip池,不限速不封号,100个线程爬崩网站
目录 scrapy版本爬取妹子图 关键所在下载图片 前期准备 代理ip池 UserAgent池 middlewares中间件(破解反爬) settings配置 正题 爬虫 保存下载图片 scrapy版 ...
- Python的scrapy之爬取boss直聘网站
在我们的项目中,单单分析一个51job网站的工作职位可能爬取结果不太理想,所以我又爬取了boss直聘网的工作,不过boss直聘的网站一次只能展示300个职位,所以我们一次也只能爬取300个职位. jo ...
- python爬虫scrapy框架——爬取伯乐在线网站文章
一.前言 1. scrapy依赖包: 二.创建工程 1. 创建scrapy工程: scrapy staratproject ArticleSpider 2. 开始(创建)新的爬虫: cd Artic ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- Python的scrapy之爬取6毛小说网的圣墟
闲来无事想看个小说,打算下载到电脑上看,找了半天,没找到可以下载的网站,于是就想自己爬取一下小说内容并保存到本地 圣墟 第一章 沙漠中的彼岸花 - 辰东 - 6毛小说网 http://www.6ma ...
随机推荐
- [C#]委托和事件(转载)
原文地址:http://blog.csdn.net/dingxiaowei2013/article/details/20249163 引言 委托 和 事件在 .Net Framework中的应用非常广 ...
- ASP.NET向MySQL写入中文的乱码问题-.NET技术/C#
1,在 mysql数据库安装目录下找到my.ini文件,把default-character-set的值修改为 default-character-set=gb2312(修改两处),保存,重新启动. ...
- Oracle日志组添加冗余文件和日志组
rac中需要指定thread添加日志组RAC:alter database add logfile thread 1 group 1('+DATA/irac/redo01_1.log','+DATA/ ...
- [EffectiveC++]item31:将文件间的编译依存关系降至最低
P143:“声明的依赖性"替换“定义的依存性”
- 如何清理Windows缩略图缓存?
从Win95的IE4开始就有缩略图缓存了,缩略图缓存作用主要是用于存储Windows资源管理器缩略图图像文件.这加快了图像的显示速度,因为每次用户查看文件夹时都不需要重新生成这些较小的图像.缩略图缓存 ...
- ABAP的权限检查跟踪(Authorization trace)工具
事务码 STAUTHTRACE 1. 点击"Activate Trace" button激活跟踪: 可以看到跟踪状态已经处于打开状态. 在同一个application server ...
- 【转载】SSH login without password 免密登陆
Your aim You want to use Linux and OpenSSH to automate your tasks. Therefore you need an automatic l ...
- Error: Error SSL Required Code: 403
Error: Error SSL Required Code: 403 Error Message If the 'services' Web directory for ArcGIS is set ...
- System.Chare的成员
实现效果: 知识运用: System.Char的静态方法 (判断一个给定的字符是否为数字 字母 标点符号或其他) 实现效果: static void CharFunctionality() { Con ...
- 剑指offer23 从上往下打印二叉树
没有把队列的头部弹出,出现内存错误: