Python的scrapy之爬取boss直聘网站
在我们的项目中,单单分析一个51job网站的工作职位可能爬取结果不太理想,所以我又爬取了boss直聘网的工作,不过boss直聘的网站一次只能展示300个职位,所以我们一次也只能爬取300个职位。
jobbossspider.py:
# -*- coding: utf-8 -*-
import scrapy
from ..items import JobbossItem class JobbosspiderSpider(scrapy.Spider):
name = 'jobbosspider'
#allowed_domains = ['https://www.zhipin.com/']
allowed_domains = ['zhipin.com']
# 定义入口URL
#start_urls = ['https://www.zhipin.com/c101010100/?query=python&page=1&ka=page-1'] #北京
#start_urls=['https://www.zhipin.com/c100010000/h_101010100/?query=Python&ka=sel-city-100010000'] #全国
#start_urls=['https://www.zhipin.com/c101020100/h_101010100/?query=Python&ka=sel-city-101020100'] #上海
#start_urls=['https://www.zhipin.com/c101280100/h_101010100/?query=Python&ka=sel-city-101280100'] #广州
#start_urls=['https://www.zhipin.com/c101280600/h_101010100/?query=Python&ka=sel-city-101280600'] #深圳
#start_urls=['https://www.zhipin.com/c101210100/h_101010100/?query=Python&ka=sel-city-101210100'] #杭州
#start_urls=['https://www.zhipin.com/c101030100/h_101010100/?query=Python&ka=sel-city-101030100'] #天津
#start_urls=['https://www.zhipin.com/c101110100/h_101010100/?query=Python&ka=sel-city-101110100'] #西安
#start_urls=['https://www.zhipin.com/c101200100/h_101010100/?query=Python&ka=sel-city-101200100'] #武汉
#start_urls=['https://www.zhipin.com/c101270100/h_101010100/?query=Python&ka=sel-city-101270100'] #成都
start_urls=['https://www.zhipin.com/c100010000/h_101270100/?query=python%E7%88%AC%E8%99%AB&ka=sel-city-100010000'] #爬虫工程师,全国 # 定义解析规则,这个方法必须叫做parse
def parse(self, response):
item = JobbossItem()
# 获取页面数据的条数
node_list = response.xpath("//*[@id=\"main\"]/div/div[2]/ul/li")
# 循环解析页面的数据
for node in node_list:
item["job_title"] = node.xpath(".//div[@class=\"job-title\"]/text()").extract()[0]
item["compensation"] = node.xpath(".//span[@class=\"red\"]/text()").extract()[0]
item["company"] = node.xpath("./div/div[2]/div/h3/a/text()").extract()[0]
company_info = node.xpath("./div/div[2]/div/p/text()").extract()
temp = node.xpath("./div/div[1]/p/text()").extract()
item["address"] = temp[0]
item["seniority"] = temp[1]
item["education"] = temp[2]
if len(company_info) < 3:
item["company_type"] = company_info[0]
item["company_finance"] = ""
item["company_quorum"] = company_info[-1]
else:
item["company_type"] = company_info[0]
item["company_finance"] = company_info[1]
item["company_quorum"] = company_info[2]
yield item
# 定义下页标签的元素位置
next_page = response.xpath("//div[@class=\"page\"]/a/@href").extract()[-1]
# 判断什么时候下页没有任何数据
if next_page != 'javascript:;':
base_url = "https://www.zhipin.com"
url = base_url + next_page
yield scrapy.Request(url=url, callback=self.parse) '''
# 斜杠(/)作为路径内部的分割符。
# 同一个节点有绝对路径和相对路径两种写法。
# 绝对路径(absolute path)必须用"/"起首,后面紧跟根节点,比如/step/step/...。
# 相对路径(relative path)则是除了绝对路径以外的其他写法,比如 step/step,也就是不使用"/"起首。
# "."表示当前节点。
# ".."表示当前节点的父节点 nodename(节点名称):表示选择该节点的所有子节点 # "/":表示选择根节点 # "//":表示选择任意位置的某个节点 # "@": 表示选择某个属性
'''
items.py
import scrapy class JobbossItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
job_title = scrapy.Field() # 岗位
compensation = scrapy.Field() # 薪资
company = scrapy.Field() # 公司
address = scrapy.Field() # 地址
seniority = scrapy.Field() # 工作年薪
education = scrapy.Field() # 教育程度
company_type = scrapy.Field() # 公司类型
company_finance = scrapy.Field() # 融资
company_quorum = scrapy.Field() # 公司人数
pipelines输出管道:
class JobbossPipeline(object):
def process_item(self, item, spider):
print('职位名:',item["job_title"])
print('薪资:',item["compensation"])
print('公司名:',item["company"])
print('公司地点:',item["address"])
print('工作经验:',item["seniority"])
print('学历要求:',item["education"])
print('公司类型:',item["company_type"])
print('融资:',item["company_finance"])
print('公司人数:',item["company_quorum"])
print('-'*50)
return item
pipelinemysql输入到数据库中:
# -*- coding: utf-8 -*-
from week5_day04.dbutil import dbutil # 作业: 自定义的管道,将完整的爬取数据,保存到MySql数据库中
class JobspidersPipeline(object):
def process_item(self, item, spider):
dbu = dbutil.MYSQLdbUtil()
dbu.getConnection() # 开启事物 # 1.添加
try:
sql = "insert into boss_job (job_title,compensation,company,address,seniority,education,company_type,company_finance,company_quorum)values(%s,%s,%s,%s,%s,%s,%s,%s,%s)"
#date = []
#dbu.execute(sql, date, True)
dbu.execute(sql, (item["job_title"],item["compensation"],item["company"],item["address"],item["seniority"],item["education"],item["company_type"],item["company_finance"],item["company_quorum"]),True)
dbu.commit()
print('插入数据库成功!!')
except:
dbu.rollback()
dbu.commit() # 回滚后要提交
finally:
dbu.close()
return item
在settings.py中开启如下设置
SPIDER_MIDDLEWARES = {
'jobboss.middlewares.JobbossSpiderMiddleware': 543,
}
DOWNLOADER_MIDDLEWARES = {
'jobboss.middlewares.JobbossDownloaderMiddleware': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None, # 这一行是取消框架自带的useragent
'jobboss.rotateuseragent.RotateUserAgentMiddleware': 400
}
ITEM_PIPELINES = {
'jobboss.pipelines.JobbossPipeline': 300,
'jobboss.pipelinesmysql.JobspidersPipeline': 301,
}
LOG_LEVEL='INFO'
LOG_FILE='jobboss.log'
#最后这两行是加入日志
最后启动项目,可以在pycharm自带的terminal中输入 :scrapy crawl 爬虫文件的名称
也可以创一个小的启动程序:
from scrapy.cmdline import execute execute(['scrapy', 'crawl', 'jobbosspider'])
爬虫启动结果:
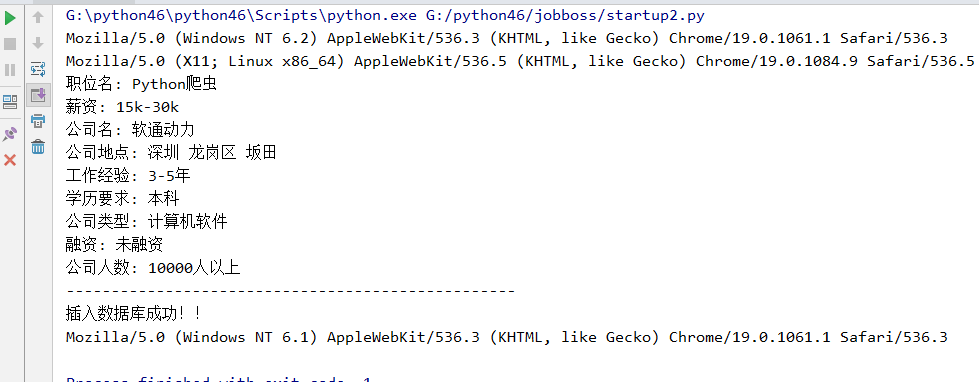
数据库中的数据如下:
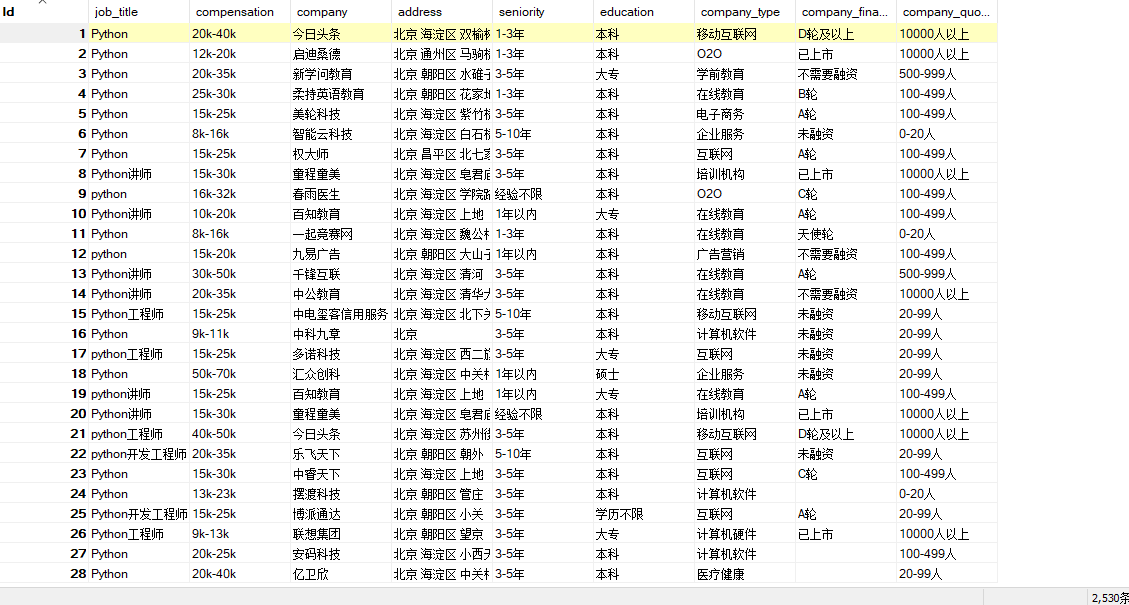
以上就是爬取boss直聘的所有内容了
Python的scrapy之爬取boss直聘网站的更多相关文章
- Scrapy 爬取BOSS直聘关于Python招聘岗位
年前的时候想看下招聘Python的岗位有多少,当时考虑目前比较流行的招聘网站就属于boss直聘,所以使用Scrapy来爬取下boss直聘的Python岗位. 1.首先我们创建一个Scrapy 工程 s ...
- 用BeautifulSoup简单爬取BOSS直聘网岗位
用BeautifulSoup简单爬取BOSS直聘网岗位 爬取python招聘 import requests from bs4 import BeautifulSoup def fun(path): ...
- python3 爬取boss直聘职业分类数据(未完成)
import reimport urllib.request # 爬取boss直聘职业分类数据def subRule(fileName): result = re.findall(r'<p cl ...
- 打造IP代理池,Python爬取Boss直聘,帮你获取全国各类职业薪酬榜
爬虫面临的问题 不再是单纯的数据一把抓 多数的网站还是请求来了,一把将所有数据塞进去返回,但现在更多的网站使用数据的异步加载,爬虫不再像之前那么方便 很多人说js异步加载与数据解析,爬虫可以做到啊,恩 ...
- Python爬取Boss直聘,帮你获取全国各类职业薪酬榜
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 王翔 清风Python PS:如有需要Python学习资料的小伙伴 ...
- scrapy爬取boss直聘实习生数据
这个..是我最近想找实习单位..结果发现boss上很多实习单位名字就叫‘实习生’.......太不讲究了 == 难怪一直搜不到..咳,其实是我自己水平有限,有些简历根本就投不出去 == 所以就想爬下b ...
- Pyhton爬虫实战 - 抓取BOSS直聘职位描述 和 数据清洗
Pyhton爬虫实战 - 抓取BOSS直聘职位描述 和 数据清洗 零.致谢 感谢BOSS直聘相对权威的招聘信息,使本人有了这次比较有意思的研究之旅. 由于爬虫持续爬取 www.zhipin.com 网 ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- 基于python的scrapy框架爬取豆瓣电影及其可视化
1.Scrapy框架介绍 主要介绍,spiders,engine,scheduler,downloader,Item pipeline scrapy常见命令如下: 对应在scrapy文件中有,自己增加 ...
随机推荐
- collectd配置
udp proxy - 192.168.48.112 cat > /etc/collectd_25801.conf << EOF Hostname "kvm-48-112& ...
- 使用embeded tomcat进行嵌入式javaee开发-启动tomcat
昨天在网上研究了下关于将tomcat嵌入到主程序中进行运行,而不是像以前将一个web项目copy到tomcat中进行运行.之所以这样做的原因,即是因为项目部署到客户方,在进行更新的时候,需要手动地进行 ...
- Win10提示“您未连接到nvidia gpu的显示器”的解决方法
显卡有Nvidia 和 ATI两个芯片,我们经常称他们为N卡和A卡,N卡更加注重于性能,而A卡则为颜色艳丽,画面更好.不过,最近一些windows10系统用户在使用N卡过程中,遇到了提示“您当前未使用 ...
- ul li一行两个显示
- SQLServer用存储过程实现插入更新数据
实现 1)有同样的数据,直接返回(返回值:0): 2)有主键同样,可是数据不同的数据,进行更新处理(返回值:2): 3)没有数据,进行插入数据处理(返回值:1). [创建存储过程] Create pr ...
- 20165322 实验一 Java开发环境的熟悉
实验一 Java开发环境的熟悉 一.实验内容及步骤 (一)命令行下Java程序开发 按照步骤新建目录.键入代码,再编译运行输出.运行结果和TREE结构图如下: (二) IDEA下Java程序开发.调试 ...
- Python:IPC-Pipe与IPC-Manger
1,IPC-PIPE: 管道 pipe from multiprocessing import Process from multiprocessing import Pipe p1,p2 = Pip ...
- The Child and Zoo 题解
题目描述 Of course our child likes walking in a zoo. The zoo has n areas, that are numbered from 1 to n. ...
- HDU 5723 Abandoned country 【最小生成树&&树上两点期望】
任意门:http://acm.hdu.edu.cn/showproblem.php?pid=5723 Abandoned country Time Limit: 8000/4000 MS (Java/ ...
- 【luogu P3371 单源最短路径】 模板 SPFA
题目链接:https://www.luogu.org/problemnew/show/P3371 我永远都喜欢Flyod.dijkstra + heap.SPFA #include <cstdi ...