Python的scrapy之爬取51job网站的职位
今天老师讲解了Python中的爬虫框架--scrapy,然后带领我们做了一个小爬虫--爬取51job网的职位信息,并且保存到数据库中
用的是Python3.6 pycharm编辑器
爬虫主体:
import scrapy
from ..items import JobspidersItem class JobsspiderSpider(scrapy.Spider):
name = 'jobsspider'
#allowed_domains = ['search.51job.com/list/010000,000000,0000,00,9,99,%2520,2,1.html']
#start_urls = ['https://search.51job.com/list/010000,000000,0000,00,9,99,%2520,2,1.html/']
start_urls = [
'https://search.51job.com/list/010000,000000,0000,01,9,99,python,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='] def parse(self, response):
currentPageItems = response.xpath('/html/body/div[@class="dw_wp"]/div[@class="dw_table"]/div[@class="el"]')
print(currentPageItems) # currentPageItems = response.xpath('//div[@class="el"]')
for jobItem in currentPageItems:
print('----',jobItem)
jobspidersItem = JobspidersItem() jobPosition = jobItem.xpath('p[@class="t1 "]/span/a/text()').extract()
if jobPosition:
#print(jobPosition[0].strip())
jobspidersItem['jobPosition'] = jobPosition[0].strip() jobCompany = jobItem.xpath('span[@class="t2"]/a/text()').extract()
if jobCompany:
#print(jobCompany[0].strip())
jobspidersItem['jobCompany'] = jobCompany[0].strip() jobArea = jobItem.xpath('span[@class="t3"]/text()').extract()
if jobArea:
#print(jobArea[0].strip())
jobspidersItem['jobArea'] = jobArea[0].strip() jobSale = jobItem.xpath('span[@class="t4"]/text()').extract()
if jobSale:
# print(jobCompany[0].strip())
jobspidersItem['jobSale'] = jobSale[0].strip() jobDate = jobItem.xpath('span[@class="t5"]/text()').extract()
if jobDate:
# print(jobCompany[0].strip())
jobspidersItem['jobDate'] = jobDate[0].strip() yield jobspidersItem # 通过yield 调用输出管道
pass
nextPageURL = response.xpath('//li[@class="bk"]/a/@href').extract() # 取下一页的地址
print(nextPageURL)
if nextPageURL:
url = response.urljoin(nextPageURL[-1])
print('url', url)
# 发送下一页请求并调用parse()函数继续解析
yield scrapy.Request(url, self.parse, dont_filter=False)
pass
else:
print("退出")
pass
items.py 设置五个items
import scrapy class JobspidersItem(scrapy.Item):
# define the fields for your item here like:
jobPosition = scrapy.Field()
jobCompany = scrapy.Field()
jobArea = scrapy.Field()
jobSale = scrapy.Field()
jobDate = scrapy.Field()
pass
pipelines.py 输出管道
class JobspidersPipeline(object):
def process_item(self, item, spider):
print('职位:', item['jobPosition'])
print('公司:', item['jobCompany'])
print('工作地点:', item['jobArea'])
print('薪资:', item['jobSale'])
print('发布时间:', item['jobDate'])
print('----------------------------')
return item
pipelinesmysql.py 输出到mysql中 第一行的意思是使用了以前封装的数据库操作类
from week5_day04.dbutil import dbutil # 作业: 自定义的管道,将完整的爬取数据,保存到MySql数据库中
class JobspidersPipeline(object):
def process_item(self, item, spider):
dbu = dbutil.MYSQLdbUtil()
dbu.getConnection() # 开启事物 # 1.添加
try:
#sql = "insert into jobs (职位名,公司名,工作地点,薪资,发布时间)values(%s,%s,%s,%s,%s)"
sql = "insert into t_job (jobname,jobcompany,jobarea,jobsale,jobdata)values(%s,%s,%s,%s,%s)"
#date = []
#dbu.execute(sql, date, True)
dbu.execute(sql, (item['jobPosition'],item['jobCompany'],item['jobArea'],item['jobSale'],item['jobDate']),True)
#dbu.execute(sql,True)
dbu.commit()
print('插入数据库成功!!')
except:
dbu.rollback()
dbu.commit() # 回滚后要提交
finally:
dbu.close()
return item
最终结果:
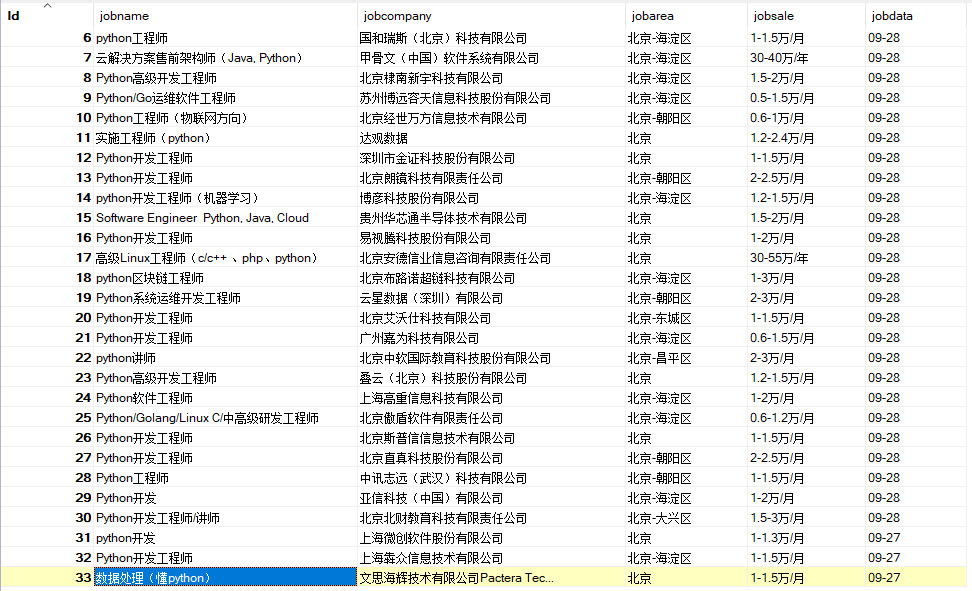
通过这个最基础的51job爬虫,进入到scrapy框架的学习中,这东西挺好使
Python的scrapy之爬取51job网站的职位的更多相关文章
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- 初识python 之 爬虫:爬取某网站的壁纸图片
用到的主要知识点:requests.get 获取网页HTMLetree.HTML 使用lxml解析器解析网页xpath 使用xpath获取网页标签信息.图片地址request.urlretrieve ...
- scrapy版本爬取某网站,加入了ua池,ip池,不限速不封号,100个线程爬崩网站
目录 scrapy版本爬取妹子图 关键所在下载图片 前期准备 代理ip池 UserAgent池 middlewares中间件(破解反爬) settings配置 正题 爬虫 保存下载图片 scrapy版 ...
- Python的scrapy之爬取boss直聘网站
在我们的项目中,单单分析一个51job网站的工作职位可能爬取结果不太理想,所以我又爬取了boss直聘网的工作,不过boss直聘的网站一次只能展示300个职位,所以我们一次也只能爬取300个职位. jo ...
- python爬虫scrapy框架——爬取伯乐在线网站文章
一.前言 1. scrapy依赖包: 二.创建工程 1. 创建scrapy工程: scrapy staratproject ArticleSpider 2. 开始(创建)新的爬虫: cd Artic ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- Python的scrapy之爬取6毛小说网的圣墟
闲来无事想看个小说,打算下载到电脑上看,找了半天,没找到可以下载的网站,于是就想自己爬取一下小说内容并保存到本地 圣墟 第一章 沙漠中的彼岸花 - 辰东 - 6毛小说网 http://www.6ma ...
随机推荐
- c++类模板成员函数报错
类模板成员函数要不就在类模板中实现,要不就和类模板写在同一个文件中. 否则然会出现下面错误: >main.obj : error LNK2019: 无法解析的外部符号 "public: ...
- DispatchAction和ForwardAction
添加功能的步骤:做页面——编写DAO类中的方法——编写和配置action. 如果多个action 使用一个formbean,这种事儿多发生在统一模块中,就可以用一个Action集中处理多个操作,而不要 ...
- monkey使用
一.Monkey测试原理:Monkey是Android中的一个命令行工具,可以运行在模拟器里或实际设备中.它向系统发送伪随机的用户事件流(如按键输入.触摸屏输入.手势输入等),实现对正在开发的应用程序 ...
- YUV数据详解
http://www.cnblogs.com/azraelly/archive/2013/01/01/2841269.html YUV格式有两大类:planar和packed.对于planar的YUV ...
- ubuntu误删home目录
今天第一次写shell脚本,一不小心把home目录全给删除了. 解决方案: 先把手打上二十大板!!! [root@myshell ~]#mkdir /home/test01 / ...
- 【[TJOI2007]可爱的质数】
题目 用一道板子题来复习一下\(bsgs\) \(bsgs\)用于求解形如 \[a^x\equiv b(mod\ p)\] 这样的高次不定方程 由于费马小定理的存在,我们可是直接暴力扫一遍\(p\), ...
- [18/12/07]String 字符串
一.基础概念 1. String类又称作不可变字符序列. 2. String位于java.lang包中,Java程序默认导入java.lang包下的所有类. 3. Java字符串就是Unicode字符 ...
- 一篇博客:分类模型的 Loss 为什么使用 cross entropy 而不是 classification error 或 squared error
https://zhuanlan.zhihu.com/p/26268559 分类问题的目标变量是离散的,而回归是连续的数值. 分类问题,都用 onehot + cross entropy traini ...
- 【洛谷P3834】(模板)可持久化线段树 1(主席树)
[模板]可持久化线段树 1(主席树) https://www.luogu.org/problemnew/show/P3834 主席树支持历史查询,空间复杂度为O(nlogn),需要动态开点 本题用一个 ...
- PAT 1063. Set Similarity
1063. Set Similarity 题目大意 给定 n 个集合, k 个询问, 求任意两个集合的并集和合集. 思路 一道裸的考察 STL 中 set 的题, 我居然还用 hash 错过一遍, 用 ...