python工业互联网应用实战6—任务分解
根据需求定义“任务”是一个完整的业务搬运流程,整个流程涉及到多个机构(设备)分别动作执行多个步骤,所以依据前面的模型设计,需要把任务分解到多个连续的子任务(作业),未来通过顺序串联下达执行的方式来分步骤的完成任务的执行。
1.1. 仓库规划
同样,依据需求我们先来做几个仓库的规划设计,101位置是AGV的入库起始站台,102是提升机门口的入库工位,104是提升机1楼轿厢工位,同理504是提升机在5楼的轿厢工位。左边是5楼的货位区编码规则,完整好的货位号加上楼层编码05-01-01表示五楼的01-01货位,如下图:

有了图上的基本仓库规划设计,我们才能把一个任务依据设计进行分解,例如:任务编码100的搬运任务是把货物从101 入库工位搬运到05-01-01货位存放。
设计约定:
① 102、502为进提升机工位,103、503为出提升机工位,出和入的工位分开来解决任务冲突的问题(当然也可以先规划一个工位,随着程序迭代改进)。
② 提升机控制逻辑与电梯类似,到达指定楼层后会自动开门。
③ 电梯只有关上廊门才能提升/下降。
这样根据约定(前置条件)现在我们针对这个任务逐步分解成以下子任务(作业)如下表,对照早期的需求会发现有增加作业,实际项目中也是如此,早期的需求定义到实际编码的时候,需要根据实际的设备接口协议,规定等调整早期的需求定义。
|
序号 |
作业描述 |
执行设备 |
|
1 |
调度AGV从101站台搬运托盘到102站台 |
1楼AGV |
|
2 |
调度提升机到1楼并打开门 |
提升机 |
|
3 |
调度AGV从102工位搬运到104工位并卸货 |
1楼AGV |
|
4 |
调度空AGV从104工位到103工位 |
1楼AGV |
|
5 |
调度提升机关门 |
提升机 |
|
6 |
调度提升机1楼提升到5楼并开门 |
提升机 |
|
7 |
调度空AGV到504工位并载货 |
5楼AGV |
|
8 |
调度AGV从504工位到503工位 |
5楼AGV |
|
9 |
调度提升机关门 |
提升机 |
|
10 |
调度AGV从503工位搬运到05-01-01货位并卸货 |
5楼AGV |
上面的分解比需求表增加了两个子任务“调度空AGV从104工位到102工位”和“调度AGV从504工位到502工位”,是与实际的AGV设备对接通信协议后增加的,AGV小车的控制系统不能识别“调度AGV从提升机1楼门口工位到提升机并卸货,返回提升机门口工位”需求里“返回”提升机门口工位。依据设备的接口逻辑,只能把这个步骤再分解成两个步骤来执行。
上述分解提供一个简化分解的模型和思路,实际项目可能更为复杂或简单。
1.2. 分解代码实现
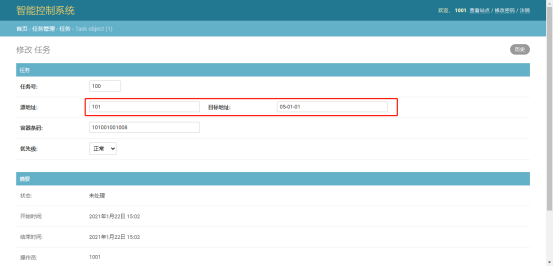
我们在后台任务管理里添加任务编码100、源地址101、目标地址05-01-01的任务,如下图:
同时admin.py里增加新增任务默认状态设置为未处理的代码,我们通过pk值是否为None来判断model是否是新增还是修改。
#Task模型的管理器
class TaskAdmin(admin.ModelAdmin):
... def save_model(self, request, obj, form, change):
#新增任务默认状态设置为 未处理
if obj.pk==None:
obj.State=1
obj.User=request.user
return super().save_model(request, obj, form, change)
接下来,我们演示如何依据上面的分解逻辑用代码来实现把任务分解成子任务并保存到Job对应的表里,同时,把任务的状态从“未处理”更新到“处理完成”状态。这里需要注意的就是任务的分解和状态变更必须在一个事务里完成,系统不能存在任务状态已经变更到处理完成,但是没有对应的作业,也不能存在已有对应的作业任务状态仍然是未处理状态的情形,否则就会造成系统业务上的混乱,前面章节提到的事务应用就非常重要!
#Task模型的管理器
class TaskAdmin(admin.ModelAdmin):
... @atomic
def task_decompose_action(self, request, queryset):
for obj in queryset:
#只处理状态等于未处理的任务
if obj.State==1:
result=self.task_decompose(request,obj)
if result:
self.message_user(request, str(obj.TaskNum) + " 处理成功.")
else:
self.message_user(request, str(obj.TaskNum) + " 处理成功.") task_decompose_action.short_description = '处理所选的' + ' 任务' def task_decompose(self,request,obj):
success=True
try:
job1=Job(**{"Task":obj,"TaskNum":obj.TaskNum,"OrderNo":1,"Source":obj.Source,"Target":'102',"Executor":"AGV01","State":1,\
"Priority":obj.Priority,"Barcode":obj.Barcode,"User":request.user,})
job1.save()
job2=Job(**{"Task":obj,"TaskNum":obj.TaskNum,"OrderNo":2,"Source":None,"Target":'1',"Executor":"ELEVATOR","State":1,\
"Priority":obj.Priority,"Barcode":obj.Barcode,"User":request.user,})
job2.save()
job3=Job(**{"Task":obj,"TaskNum":obj.TaskNum,"OrderNo":3,"Source":"102","Target":'104',"Executor":"AGV01","State":1,\
"Priority":obj.Priority,"Barcode":obj.Barcode,"User":request.user,})
job3.save()
job4=Job(**{"Task":obj,"TaskNum":obj.TaskNum,"OrderNo":4,"Source":'104',"Target":'103',"Executor":"AGV01","State":1,\
"Priority":obj.Priority,"Barcode":obj.Barcode,"User":request.user,})
job4.save()
job5=Job(**{"Task":obj,"TaskNum":obj.TaskNum,"OrderNo":5,"Source":'1',"Target":'5',"Executor":"ELEVATOR","State":1,\
"Priority":obj.Priority,"Barcode":obj.Barcode,"User":request.user,})
job5.save()
job6=Job(**{"Task":obj,"TaskNum":obj.TaskNum,"OrderNo":6,"Source":'504',"Target":'503',"Executor":"AGV05","State":1,\
"Priority":obj.Priority,"Barcode":obj.Barcode,"User":request.user,})
job6.save()
job7=Job(**{"Task":obj,"TaskNum":obj.TaskNum,"OrderNo":7,"Source":'5',"Target":None,"Executor":"ELEVATOR","State":1,\
"Priority":obj.Priority,"Barcode":obj.Barcode,"User":request.user,})
job7.save()
job8=Job(**{"Task":obj,"TaskNum":obj.TaskNum,"OrderNo":8,"Source":'503',"Target":'05-01-01',"Executor":"AGV05","State":1,\
"Priority":obj.Priority,"Barcode":obj.Barcode,"User":request.user,})
job8.save()
#子任务分解完成,并提交数据库
#更新任务的状态到“处理完成”
obj.State=5
obj.save()
except Exception:
success = False return success
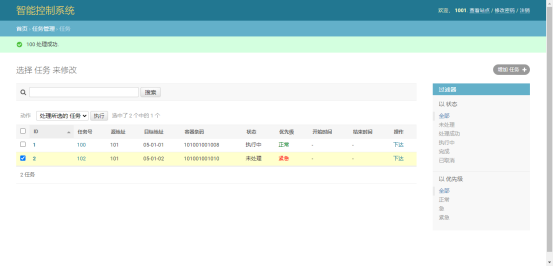
执行效果如下图:
1.3. 列表增加“作业数量”
任务分解完成后,列表除了显示状态变化之外,能够查看作业的分解数量,为此在Task Admin里增加job_count函数用来显示作业数量。
#Task模型的管理器
class TaskAdmin(admin.ModelAdmin):
#listdisplay设置要显示在列表中的字段(TaskId字段是Django模型的主键)
list_display = ('TaskId','TaskNum', 'Source', 'Target', 'Barcode','State','PriorityColor','BeginDate','EndDate','job_count','task_operate',) ... def job_count(self, obj):
return obj.job_set.count() job_count.short_description = '作业数量'
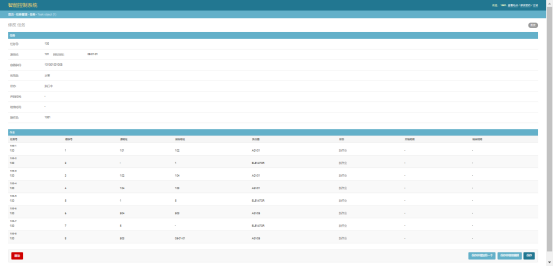
1.4. 编辑页面查看作业数据
Job模型外键管理Task模型,我就可以采用TabularInline的方式来显示任务的作业信息,通过编辑界面直接查看对应任务的Job列表。
class JobInline(admin.TabularInline):
model = Job
fields = ('TaskNum','OrderNo','Source', 'Target','Executor','State','BeginDate','EndDate',)
extra = 0 #默认所有条目
# 只读的字段
readonly_fields = ('TaskNum','OrderNo','Source', 'Target','Executor','State','BeginDate','EndDate',) def has_delete_permission(self, request, obj=None):
return False #不允许删除
def has_add_permission(self, request, obj=None):
return False #不允许添加 #Task模型的管理器
class TaskAdmin(admin.ModelAdmin): #listdisplay设置要显示在列表中的字段(TaskId字段是Django模型的主键)
list_display = ('TaskId','TaskNum', 'Source', 'Target', 'Barcode','State','PriorityColor','BeginDate','EndDate','job_count','task_operate',)
inlines=[JobInline]
fieldsets = (("任务", {'fields': ['TaskNum', ('Source', 'Target'), 'Barcode','Priority','State','BeginDate','EndDate','User']}),)
1.5. 魔法数(mogic number)
任务的状态赋值和变更我们采用了直接obj.State=1或obj.State=5的直接赋值数字的方式,这个就是程序的mogic number它们有特殊的含义,编程人员得知道这个数字对应的含义,当状态变多时间拉长,编程人员就得去回忆或来回查看数字对应的状态。好的编程习惯就是用常量来代替魔法数字。重构models.py里的Task和Job代码用常量替换mogic number.
class Task(models.Model):
STATE_NEW =1
STATE_PROCESSED=4
STATE_RUNNING=5
STATE_COMPLETED=99
STATE_CANCEL=-1 TASK_STATE=((STATE_NEW,u'未处理'),(STATE_PROCESSED,u'处理成功'),(STATE_RUNNING,u'执行中'),(STATE_COMPLETED,u'完成'),(STATE_CANCEL,u'已取消')) TaskId = models.AutoField(u'ID',primary_key=True, db_column='task_id')
TaskNum = models.IntegerField(u'任务号', null=False, db_column='task_num')
Source = models.CharField(u'源地址', null=False, max_length=50, db_column='source')
Target = models.CharField(u'目标地址', null=False, max_length=50, db_column='target')
Barcode = models.CharField(u'容器条码', null=False, max_length=50, db_column='barcode')
State = models.IntegerField(u'状态', choices=TASK_STATE, null=False, db_column='state')
Priority = models.IntegerField(u'优先级', choices=PRIORITY, null=True, db_column='priority')
BeginDate = models.DateTimeField(u'开始时间',null=True, db_column='begin_date')
EndDate = models.DateTimeField(u'结束时间',null=True, db_column='end_date')
SystemDate = models.DateTimeField(u'系统时间', null=False, auto_now_add=True, db_column='system_date')
User = models.ForeignKey(User, verbose_name="操作员",null=True, on_delete=models.CASCADE,db_column='user_id') class Meta:
db_table = 'task_task'
ordering = ['-Priority','TaskId']
verbose_name = verbose_name_plural = "任务" ... class Job(models.Model): STATE_NEW =1
STATE_START=2
STATE_COMPLETED=99
STATE_CANCEL=-1 JOB_STATE=((STATE_NEW,u'新作业'),(STATE_START,u'下达执行'), (STATE_COMPLETED,u'完成'),(STATE_CANCEL,u'已取消'))
凡是有魔法数字的地方都尽量替换成可以阅读的常量,采用中式英语都是可以推荐的方式:)。
class TaskBiz(object):
"""description of class""" def task_start(self,obj):
success=False
if obj.State==Task.STATE_PROCESSED:
obj.State=Task.STATE_RUNNING
try:
obj.save()
success = True
except Exception:
success = False
return success ... def task_decompose(self,request,obj):
success=True
try:
job1=Job(**{"Task":obj,"TaskNum":obj.TaskNum,"OrderNo":1,"Source":obj.Source,"Target":'102',"Executor":"AGV01","State":Job.STATE_NEW,\
"Priority":obj.Priority,"Barcode":obj.Barcode,"User":request.user,})
job1.save()
job2=Job(**{"Task":obj,"TaskNum":obj.TaskNum,"OrderNo":2,"Source":None,"Target":'1',"Executor":"ELEVATOR","State":Job.STATE_NEW,\
"Priority":obj.Priority,"Barcode":obj.Barcode,"User":request.user,})
job2.save()
job3=Job(**{"Task":obj,"TaskNum":obj.TaskNum,"OrderNo":3,"Source":"102","Target":'104',"Executor":"AGV01","State":Job.STATE_NEW,\
"Priority":obj.Priority,"Barcode":obj.Barcode,"User":request.user,})
job3.save()
job4=Job(**{"Task":obj,"TaskNum":obj.TaskNum,"OrderNo":4,"Source":'104',"Target":'103',"Executor":"AGV01","State":Job.STATE_NEW,\
"Priority":obj.Priority,"Barcode":obj.Barcode,"User":request.user,})
job4.save()
job5=Job(**{"Task":obj,"TaskNum":obj.TaskNum,"OrderNo":5,"Source":'1',"Target":'5',"Executor":"ELEVATOR","State":Job.STATE_NEW,\
"Priority":obj.Priority,"Barcode":obj.Barcode,"User":request.user,})
job5.save()
job6=Job(**{"Task":obj,"TaskNum":obj.TaskNum,"OrderNo":6,"Source":'504',"Target":'503',"Executor":"AGV05","State":Job.STATE_NEW,\
"Priority":obj.Priority,"Barcode":obj.Barcode,"User":request.user,})
job6.save()
job7=Job(**{"Task":obj,"TaskNum":obj.TaskNum,"OrderNo":7,"Source":'5',"Target":None,"Executor":"ELEVATOR","State":Job.STATE_NEW,\
"Priority":obj.Priority,"Barcode":obj.Barcode,"User":request.user,})
job7.save()
job8=Job(**{"Task":obj,"TaskNum":obj.TaskNum,"OrderNo":8,"Source":'503',"Target":'05-01-01',"Executor":"AGV05","State":Job.STATE_NEW,\
"Priority":obj.Priority,"Barcode":obj.Barcode,"User":request.user,})
job8.save()
#子任务分解完成,并提交数据库
#更新任务的状态到“处理完成”
obj.State=Task.STATE_PROCESSED
obj.save()
except Exception:
success = False return success
1.6. 小结
本章节我们讲述了如何通过admin.py来快速的完成页面功能的构建,并通过自定义action快速的实现了任务分解功能,并根据业务进展也逐步的完善了查看页面以内联表的方式显示作业详情。随着业务功能的增加admin.py的代码逐步增多和变得复杂,下一章我们演示如何通过功能内聚和重构代码,增加代码可读性和可维护性。
python工业互联网应用实战6—任务分解的更多相关文章
- python工业互联网应用实战2—从需求开始
前言:随着国家工业2025战略的推进,工业互联网发展将会提速,将迎来一个新的发展时期,越来越多的企业开始逐步的把产线自动化,去年年底投产的小米亦庄的智能工厂就是一个热议的新闻.小米/华为智能工厂只能说 ...
- python工业互联网应用实战1—SQL与ORM
从sql到ORM应该说也是编程体系逐步演化的结果,通过类和对象更好的组织开个过程中遇到的各种业务问题,面向对象的解耦和内聚作为一套有效的方法论,对于复杂的企业应用而言确实能够解决实践过程中很多问题. ...
- python工业互联网应用实战3—模型层构建
本章开始我们正式进入到实战项目开发过程,如何从需求分析获得的实体数据转到模型设计中来,变成Django项目中得模型层.当然,第一步还是在VS2019 IDE环境重创建一个工程项目,本文我们把工程名称命 ...
- python工业互联网应用实战7—业务层
本章我们演示代码是如何"进化"的,实战的企业日常开发过程中,系统功能总伴随着业务的不断增加,早期简单的代码慢慢的越来越复杂,敏捷编程中的"禅"--简单设计.快速 ...
- python工业互联网应用实战13—基于selenium的功能测试
本章节我们再来说说测试,单元测试和功能测试.单元测试我们在数据验证章节简单提过了,本章我们进一步如何用单元测试来测试view的功能代码:同时,也涉及一下基于selenium的功能测试做法.笔者过去的项 ...
- python工业互联网应用实战15-前后端分离模式1
我们在13章节里通过监控界面讲了如何使用jquery的动态加载数据写法,通过简单案例来说明了如何实现动态的刷新监控界面的数据,本章我们将演示如何从Django模板加载数据逐步演化到前后端分离的异步数据 ...
- python工业互联网应用实战18—前后端分离模式之jquery vs vue
前面我们分三章来说明了使用django template与jquery的差别,通过jquery如何来实现前后端的分离,同时再9章节使用vue.js 我们浅尝辄止的介绍了JQuery到vue的切换,由于 ...
- python工业互联网应用实战3—Django Admin列表
Django Admin笔者使用下来可以说是Django框架的开发利器,业务model构建完成后,我们就能快速的构建一个增删查改的后台管理框架.对于大量的企业管理业务开发来说,可以快速的构建一个可发布 ...
- python工业互联网应用实战5—Django Admin 编辑界面和操作
1.1. 编辑界面 默认任务的编辑界面,对于model属性包含"choices"会自动显示下来列表供选择,"datetime"数据类型也默认提供时间选择组件,如 ...
随机推荐
- 前端基础功能,原生js实现轮播图实例教程
轮播图是前端最基本.最常见的功能,不论web端还是移动端,大平台还是小网站,大多在首页都会放一个轮播图效果.本教程讲解怎么实现一个简单的轮播图效果.学习本教程之前,读者需要具备html和css技能,同 ...
- pytorch——合并分割
分割与合并 import torch import numpy as np #假设a是班级1-4的数据,每个班级里有32个学生,每个学生有8门分数 #假设b是班级5-9的数据,每个班级里有32个学生, ...
- Flink可靠性的基石-checkpoint机制详细解析
Checkpoint介绍 checkpoint机制是Flink可靠性的基石,可以保证Flink集群在某个算子因为某些原因(如 异常退出)出现故障时,能够将整个应用流图的状态恢复到故障之前的某一状态,保 ...
- java虚拟机入门(二)-探索内存世界
上节简单介绍了一下jvm的内存布局以及简单概念,那么对于虚拟机来说,它是怎么一步步的让我们能执行方法的呢: 1.首先,jvm启动时,跟个小领导一样会根据配置参数(没有配置的话jvm会有默认值)向大领导 ...
- 如何使用 Vuepress
项目结构 ├─docs │ ├─.vuepress --vuepress相关文件路径 (主要配置) │ │ ├─dist --build 打包生成路径 (自定义) │ │ ├─nav --导航条配置 ...
- testng学习笔记-- beforeclass和afterclass
一.定义 类之前和类之后运行的方法 使用场景: 类运行之前是否需要静态方法,变量赋值,写完其他方法都可以用了 二.标签代码 三.运行结果
- file descriptor 0 1 2 一切皆文件 stdout stderr stdin /dev/null 沉默是金 pipes 禁止输出 屏蔽 stdout 和 stderr 输入输出重定向 重定向文件描述符
movie.mpeg.001 movie.mpeg.002 movie.mpeg.003 ... movie.mpeg.099 $cat movie.mpeg.0*>movie.mpeg ...
- 手把手教你定位常见Java性能问题
概述 性能优化一向是后端服务优化的重点,但是线上性能故障问题不是经常出现,或者受限于业务产品,根本就没办法出现性能问题,包括笔者自己遇到的性能问题也不多,所以为了提前储备知识,当出现问题的时候不会手忙 ...
- CQOI 2006 简单题
CQOI 2006 简单题 有一个 n 个元素的数组,每个元素初始均为 0.有 m 条指令,要么让其中一段连续序列数字反转--0 变 1,1 变 0(操作 11),要么询问某个元素的值(操作 2). ...
- 关于MongoDB的简单理解(三)--Spring Boot篇
一.前言 Spring Boot集成MongoDB非常简单,主要为加依赖,加配置,编码. 二.说明 环境说明: JDK版本为15(1.8+即可) Spring Boot 2.4.1 三.集成步骤 3. ...