SQL Server 列存储索引 第三篇:维护
列存储索引分为两种类型:聚集的列存储索引和非聚集的列存储索引,在一个表上只能创建一个聚集索引,要么是聚集的列存储索引,要么是聚集的行存储索引,然而一个表上可以创建多个非聚集索引。
一,创建列存储索引
创建列存储索引的语法如下:


-- Create a clustered columnstore index on disk-based table.
CREATE CLUSTERED COLUMNSTORE INDEX index_name
ON { database_name.schema_name.table_name | schema_name.table_name | table_name }
[ WITH ( < with_option> [ ,...n ] ) ]
[ ON <on_option> ]
[ ; ] --Create a nonclustered columnstore index on a disk-based table.
CREATE [NONCLUSTERED] COLUMNSTORE INDEX index_name
ON { database_name.schema_name.table_name | schema_name.table_name | table_name }
( column [ ,...n ] )
[ WHERE <filter_expression> [ AND <filter_expression> ] ]
[ WITH ( < with_option> [ ,...n ] ) ]
[ ON <on_option> ]
[ ; ] <with_option> ::=
DROP_EXISTING = { ON | OFF } -- default is OFF
| MAXDOP = max_degree_of_parallelism
| ONLINE = { ON | OFF }
| COMPRESSION_DELAY = { 0 | delay [ Minutes ] }
| DATA_COMPRESSION = { COLUMNSTORE | COLUMNSTORE_ARCHIVE }
[ ON PARTITIONS ( { partition_number_expression | range } [ ,...n ] ) ] <on_option>::=
partition_scheme_name ( column_name )
| filegroup_name
| "default" <filter_expression> ::=
column_name IN ( constant [ ,...n ]
| column_name { IS | IS NOT | = | <> | != | > | >= | !> | < | <= | !< } constant
选项注释:
- DROP_EXISTING = [OFF] | ON : 删除已经存储的索引,创建一个新的索引,默认值是ON
- MAXDOP = max_degree_of_parallelism:设置最大并发度,0是默认值,根据系统的工作负载动态调正并发度;1表示单线程,禁止并发;>1 表示指定并发度,但是系统会根据当前的工作负载适当减少并发度。
- COMPRESSION_DELAY = 0 | delay [ Minutes ]:默认值是0,对于disk-based表,该选项指定处于CLOSED 状态的delta rowgroup必须保留在delta rowgroup的最小延迟,当超过该延迟后,SQL Server的后台进程 tuple-mover 会把该CLOSED增量行组压缩到列存储中。
- DATA_COMPRESSION = COLUMNSTORE | COLUMNSTORE_ARCHIVE:列存储的数据压缩算法
- ON on_opiton:用于指定分区架构或文件组
1,创建聚集的列存储索引
创建聚集的列存储索引,实际上是把行版本的heap或行版本的聚集索引转换为列存储,聚集的列存储索引实际上就是整个表。
创建聚集的列存储索引,是对表中所有行和列进行存储,按照列进行压缩和排序,在物理存储上也会重建组织。
CREATE CLUSTERED COLUMNSTORE INDEX index_name
ON { database_name.schema_name.table_name | schema_name.table_name | table_name }
[ WITH ( < with_option> [ ,...n ] ) ]
[ ON <on_option> ]
2,创建非聚集的列存储索引
在一个行存储的heap或聚集索引上创建一个in-memoy的非聚集的列存储索引(in-memory nonclustered columnstore index),该索引可以有过滤条件,不需要包含所有的数据行;该索引还可以有列过滤,不需要包含所有的列。
该索引需要足够的空间来存储数据的副本,它是可更新的, 随着基表的更新而更新。
--Create a nonclustered columnstore index on a disk-based table.
CREATE [NONCLUSTERED] COLUMNSTORE INDEX index_name
ON { database_name.schema_name.table_name | schema_name.table_name | table_name }
( column [ ,...n ] )
[ WHERE <filter_expression> [ AND <filter_expression> ] ]
[ WITH ( < with_option> [ ,...n ] ) ]
[ ON <on_option> ]
3,列存储索引不支持的数据类型
如果表中的字段是如下数据类型,不能创建列存储索引:
- ntext, text, and image
- nvarchar(max), varchar(max), and varbinary(max) (Applies to SQL Server 2016 (13.x) and prior versions, and nonclustered columnstore indexes)
- rowversion (and timestamp)
- sql_variant
- CLR types (hierarchyid and spatial types)
- xml
- uniqueidentifier (Applies to SQL Server 2012 (11.x))
二,数据加载和列存储索引的更新
把数据加载到表中,总的来说,有两种模式:bulk load和 trickle insert。
1,批量数据加载(bulk load)
批量加载是指将大量行添加到数据存储中的方式,这是把数据移入列存储索引的最高效方式,因为它对成批的行进行操作。 批量加载将行组填充到最大容量,并将其直接压缩到列存储中。 在加载结束时,只有不满足每个行组最少102,400行的行才能进入增量存储。
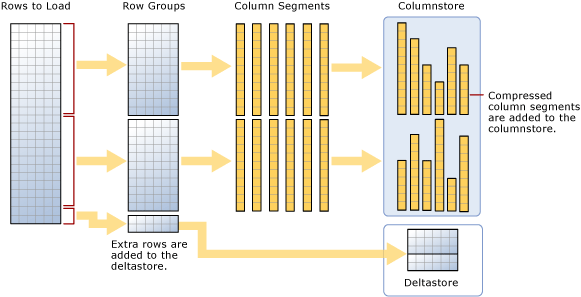
在批量加载数据时,应该考虑到:
- 批量加载不对数据进行预排序,数据按照接收的顺序插入到行组中。
- 如果批处理大小 > = 102400,则这些行将被直接放入压缩的行组中。建议设置大于或等于102400的批大小以进行有效的批量导入,这可以避免SQL Server把数据移入到增量行组(delta rowgroup)。
- 如果批量大小<102,400,或其余行<102,400,则将这些行加载到增量行组中。
- 对于增量行组中的数据,如果数据累加到阈值102400行,那么后台线程Tuple mover(TM)最终把行移动到压缩行组中。
批量加载的优点:
- 并发加载:多个批量加载可以并发运行,每个都加载一个单独的数据文件。这与行存储批量加载到SQL Server中不同,不需要指定TABLOCK,因为每个批量导入线程都把数据排他地锁定到单独的行组(压缩行或增量行组)中,并且排他锁定。
- 减少日志记录:把数据直接加载到压缩的行组中可显着减少日志的大小。例如,如果把数据压缩10倍,那么相应的事务日志大约小10倍,而无需TABLOCK或大容量日志记录/简单恢复模型。转到增量行组的所有数据均已完全记录。这包括小于102,400行的任何批处理大小。最佳实践是使用batchsize> =102400,由于不需要TABLOCK,因此可以并行加载数据。
- 最小化日志记录:如果遵循最小化日志记录的前提条件,则可以进一步减少日志记录。但是,这与把数据加载到行存储区不同,TABLOCK导致表上的X锁而不是BU(批量更新)锁,因此无法完成并行数据加载。
- 锁定优化:把数据加载到压缩的行组中时,会自动获取行组上的X锁。但是,当批量加载到增量行组中时,在行组处会获得X锁,但SQL Server仍会锁定PAGE / EXTENT,因为X行组锁不属于锁定层次结构。
2,流插入
流插入(Trickle Insert)是指逐行移入到列存储索引的方式,通常使用insert语句,使用流插入,所有行都会进入到deltastore,这对于少量的数据插入非常有用。
INSERT INTO <table-name>(....)
VALUES (<set of values>)
一旦delta 行组包含1,048,576行,这个delta 行组的状态由OPEN状态转换为CLOSED状态,有一个后台线程Tuple Mover(TM)每隔大约5分钟周期性地检查关闭的增量行组(CLOSED delta rowgroup),把数据压缩到列存储索引中。
如果delta行组处于CLOSED状态,用户可以显式调用以下命令来压缩封闭的增量行组:
ALTER INDEX <index-name>
on <table-name>
REORGANIZE
如果delta行组处于OPEN状态,用户也可以强制增量行组关闭和压缩,可以执行以下命令:
ALTER INDEX <index-name>
on <table-name>
REORGANIZE
with (COMPRESS_ALL_ROW_GROUPS = ON)
三,整理索引的碎片
列存储索引的碎片,实际上是指标记为删除的行。
1,检查列存储索引的碎片
通过使用 sys.dm_db_column_store_row_group_physical_stats,用户可以探测到列存储索引中被标记为删除的行所占的百分比,这是衡量列存储索引中碎片程度的度量,
SELECT i.object_id,
object_name(i.object_id) AS TableName,
i.index_id,
i.name AS IndexName,
100*(ISNULL(SUM(CSRowGroups.deleted_rows),0))/NULLIF(SUM(CSRowGroups.total_rows),0) AS 'Fragmentation'
FROM sys.indexes AS i
INNER JOIN sys.dm_db_column_store_row_group_physical_stats AS CSRowGroups
ON i.object_id = CSRowGroups.object_id
AND i.index_id = CSRowGroups.index_id
WHERE object_name(i.object_id) = 'FactResellerSalesXL_CCI'
GROUP BY i.object_id, i.index_id, i.name
ORDER BY object_name(i.object_id), i.name;
2,整理列存储索引的碎片
整理列存储索引的碎片,主要是索引的重组和重建:
- 重组索引是指: 重组索引的叶级别上的数据,通过对叶级页面进行物理重新排序以匹配叶节点的逻辑顺序(从左到右),可以对表和视图上的聚簇索引和非聚簇索引的叶级别进行碎片整理。重新组织还会压缩索引页。
- 重建索引是指:删除原始的索引,并重建创建一个新的索引,对于列存储索引来说,重建索引会移除碎片、把所有的数据行都移入列存储,把标记为删除的行所占用的存储空间释放。
3,举个例子,重组索引
第一次执行以下命令,用于把列存储索引上的所有CLOSED 和OPEN 的行组进入到colunstore中
ALTER INDEX columnstore_index_name
ON table_name
REORGANIZE WITH (COMPRESS_ALL_ROW_GROUPS = ON);
再次执行该命令,SQL Server会把小的行组合并到一个大的压缩行组中。
4,举个例子,重建索引
ALTER INDEX columnstore_index_name
ON table_name
REBUILD;
四,列存储索引的元数据
对列存储索引的操作,分为物理存储上的统计和逻辑层面的操作上的统计。
行组由两种格式,一种是columnstore格式的的行组,一种是rowstore格式的行组。在列存储索引中,deltastore中的行组是rowstore格式的,而columnstroe索引中的行组是columnstore格式的。
1,列存储行组的物理存储上统计
系统视图:sys.dm_db_column_store_row_group_physical_stats
关键字段注释:
- row_group_id:行组的ID,-1 表示in-memory tail。
- delta_store_hobt_id:在deltastore中的行组的hobt_id,如果为NULL表示行组不在deltastroe中。
- state和state_desc:行组的状态,
- INVISIBLE:用于行组,表示行组正在创建,数据正在被压缩,该行组在列存储中是不可见的,当压缩完成之后,状态由INVISIBLE转换为COMPRESSED,行组由rowstore格式转换为columnstore格式。
- COMPRESSED:用于行组,表示行组使用列存储压缩算法被压缩,被存储到columnstore中
- OPEN:用于deltastore,表示deltastore中的行组可以接收数据行,一个OPEN的行组是rowstore格式,并且没有被压缩到columnstore格式。
- CLOSED:用于deltastore, 表示deltastore中行组包含了最大数据行,正在等待被后台的tuple mover进程压缩到列存储,
- TOMBSTONE:一个行组曾经在deltastore,并且不再被引用。
- total_rows:行组实际存储的行数,包含新增的和标记为删除的行
- delted_rows:标记为删除的行
2,列存储索引的逻辑操作统计
系统视图:sys.dm_db_column_store_row_group_operational_stats
关键字段注释:
- row_group_id:行组的ID
- scan_count:通过行组进行扫描的次数
- delete_buffer_scan_count:使用删除缓冲区确定此行组中已删除行的次数,即被删除的行被重新查询的次数。
- index_scan_count:列存储索引分区被扫描的次数
- rowgroup_lock_count:对行组申请锁定的次数
- rowgroup_lock_wait_count:对行组申请锁定时需要等待的次数
- rowgroup_lock_wait_in_ms:对行组申请锁定时等待的时间,单位是毫秒
参考文档:
CREATE COLUMNSTORE INDEX (Transact-SQL)
Resolve index fragmentation by reorganizing or rebuilding indexes
SQL Server 列存储索引 第三篇:维护的更多相关文章
- SQL Server 列存储索引 第四篇:实时运营数据分析
实时运营数据分析(real-time operational analytics )是指同时在同一张数据表上执行分析处理和业务处理.分析查询主要是对海量数据执行聚合查询,而事务主要是指对数据表进行少量 ...
- SQL Server 列存储索引强化
SQL Server 列存储索引强化 SQL Server 列存储索引强化 1. 概述 2.背景 2.1 索引存储 2.2 缓存和I/O 2.3 Batch处理方式 3 聚集索引 3.1 提高索引创建 ...
- SQL Server 列存储索引 第二篇:设计
列存储索引可以是聚集的,也可以是非聚集的,用户可以在表上创建聚集的列存储索引(Clustered Columnstore Index)或非聚集的列存储索引(Nonclustered Columnsto ...
- SQL Server 列存储索引概述
第一次接触ColumnStore是在2017年,数据库环境是SQL Server 2012,Microsoft开始在SQL Server 2012中推广列存储索引,到现在的SQL Server 201 ...
- 使用Spark加载数据到SQL Server列存储表
原文地址https://devblogs.microsoft.com/azure-sql/partitioning-on-spark-fast-loading-clustered-columnstor ...
- SQL Server 列存储性能调优(翻译)
原文地址:http://social.technet.microsoft.com/wiki/contents/articles/4995.sql-server-columnstore-performa ...
- SQL Server Reporting Service(SSRS) 第三篇 SSRS Matrix用法
以前不是太清楚SSRS的功能,自从最近有了了解之后,发现它的功能的确很强大.对于Matrix,刚开始我竟不知道它到底有什么用,现将通过一个例子中去理解Matrix,以及和分组Group结合使用的便利性 ...
- SQL Server 2014聚集列存储索引
转发请注明引用和原文博客(http://www.cnblogs.com/wenBlog) 简介 之前已经写过两篇介绍列存储索引的文章,但是只有非聚集列存储索引,今天再来简单介绍一下聚集的列存储索引,也 ...
- SQL Server调优系列玩转篇三(利用索引提示(Hint)引导语句最大优化运行)
前言 本篇继续玩转模块的内容,关于索引在SQL Server的位置无须多言,本篇将分析如何利用Hint引导语句充分利用索引进行运行,同样,还是希望扎实掌握前面一系列的内容,才进入本模块的内容分析. 闲 ...
随机推荐
- xss利用——BeEF#stage3(绕过同源策略与浏览器代理)
绕过同源策略 正式进入攻击阶段.因为SOP(同源策略)的存在,BeEF只能对被勾子钩住的页面所在域进行操作.如果有办法绕过SOP,那么无疑会使攻击面放大. 绕过SOP可从两方面入手.第一个是从浏览器本 ...
- chrome禁止三方cookie,网站登录不了怎么办
背景 新版chrome(80+)浏览器默认屏蔽所有三方cookie已经不是什么新闻了,具体原因这里不去深究,有大量相关文章介绍,由于目前许多网站都依赖三方cookie,因此该特性的推出还是造成了一些的 ...
- Spring事务管理(编码式、配置文件方式、注解方式)
1.事务(https://www.cnblogs.com/zhai1997/p/11710082.html) (1)事务的特性:acdi (2)事务的并发问题:丢失修改,脏读,不可重复读 (3)事务的 ...
- 烦人的Null,你可以走开点了
1. Null 的问题 假设现在有一个需要三个参数的方法.其中第一个参数是必须的,后两个参数是可有可无的. 第一种情况,在我们调用这个方法的时候,我们只能传入两个参数,对第三个参数,我们在上下文里是没 ...
- Centos-清屏命令-clear
clear 清理屏幕输出 相关快捷键 ctrl + l
- 076 01 Android 零基础入门 02 Java面向对象 01 Java面向对象基础 01 初识面向对象 01 Java面向对象导学
076 01 Android 零基础入门 02 Java面向对象 01 Java面向对象基础 01 初识面向对象 01 Java面向对象导学 本文知识点:Java面向对象导学 说明:因为时间紧张,本人 ...
- P5091 【模板】扩展欧拉定理
题目链接 昨天考试考到了欧拉公式,结果发现自己不会,就来恶补一下. 欧拉公式 \(a^b \bmod p = a^{b}\) \(b < \varphi(p)\) \(a^b \bmod p = ...
- 可能是东半球第二好用的软件工具全部在这里(update in 2020.10.09)
1. 产品经理工具种草 浏览器:Google Chrome 网络浏览器 原型绘制软件:墨刀- 在线产品原型设计与协作平台(https://modao.cc/).摹客mockplus - 摹客,让设计和 ...
- Django Croppie
下载 Django CroppieDjango Croppie django -croppie是一个简单集成croppie.js图像cropper到django项目的应用程序. 安装 安装与pip安装 ...
- 用< 100行代码向EPUB或Web服务器添加视频回放
下载source - 32.3 KB 下载latest version from GituHub 介绍 在我 在关于CodeProject的前一篇文章中,我展示了一个简单的EPUB查看器 Androi ...