Logstash学习之路(四)使用Logstash将mysql数据导入elasticsearch(单表同步、多表同步、全量同步、增量同步)
一、使用Logstash将mysql数据导入elasticsearch
1、在mysql中准备数据:
mysql> show tables;
+----------------+
| Tables_in_yang |
+----------------+
| im |
+----------------+
1 row in set (0.00 sec) mysql> select * from im;
+----+------+
| id | name |
+----+------+
| 2 | MSN |
| 3 | QQ |
+----+------+
2 rows in set (0.00 sec)
2、简单实例配置文件准备:
[root@master bin]# cat mysqles.conf
input {
stdin {}
jdbc {
type => "jdbc"
jdbc_connection_string => "jdbc:mysql://192.168.200.100:3306/yang?characterEncoding=UTF-8&autoReconnect=true"
# 数据库连接账号密码;
jdbc_user => "root"
jdbc_password => "010209"
# MySQL依赖包路径;
jdbc_driver_library => "/mnt/mysql-connector-java-5.1.38.jar"
# the name of the driver class for mysql
jdbc_driver_class => "com.mysql.jdbc.Driver"
statement => "SELECT * FROM `im`"
}
}
output {
elasticsearch {
# 配置ES集群地址
hosts => ["192.168.200.100:9200"]
# 索引名字,必须小写
index => "im"
}
stdout {
}
}
3、实例结果:
[root@master bin]# ./logstash -f mysqles.conf
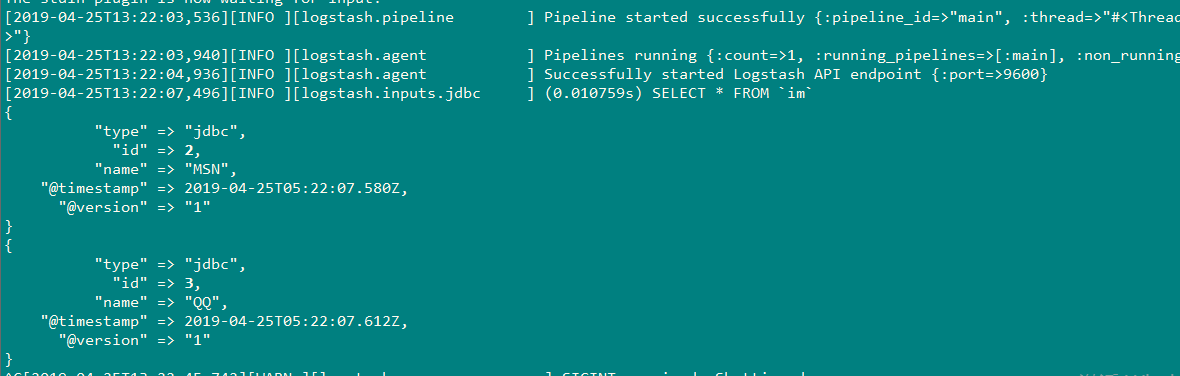

4、更多选项配置如下(单表同步):
input {
stdin {}
jdbc {
type => "jdbc"
# 数据库连接地址
jdbc_connection_string => "jdbc:mysql://192.168.1.1:3306/TestDB?characterEncoding=UTF-8&autoReconnect=true""
# 数据库连接账号密码;
jdbc_user => "username"
jdbc_password => "pwd"
# MySQL依赖包路径;
jdbc_driver_library => "mysql/mysql-connector-java-5.1.34.jar"
# the name of the driver class for mysql
jdbc_driver_class => "com.mysql.jdbc.Driver"
# 数据库重连尝试次数
connection_retry_attempts => "3"
# 判断数据库连接是否可用,默认false不开启
jdbc_validate_connection => "true"
# 数据库连接可用校验超时时间,默认3600S
jdbc_validation_timeout => "3600"
# 开启分页查询(默认false不开启);
jdbc_paging_enabled => "true"
# 单次分页查询条数(默认100000,若字段较多且更新频率较高,建议调低此值);
jdbc_page_size => "500"
# statement为查询数据sql,如果sql较复杂,建议配通过statement_filepath配置sql文件的存放路径;
# sql_last_value为内置的变量,存放上次查询结果中最后一条数据tracking_column的值,此处即为ModifyTime;
# statement_filepath => "mysql/jdbc.sql"
statement => "SELECT KeyId,TradeTime,OrderUserName,ModifyTime FROM `DetailTab` WHERE ModifyTime>= :sql_last_value order by ModifyTime asc"
# 是否将字段名转换为小写,默认true(如果有数据序列化、反序列化需求,建议改为false);
lowercase_column_names => false
# Value can be any of: fatal,error,warn,info,debug,默认info;
sql_log_level => warn
#
# 是否记录上次执行结果,true表示会将上次执行结果的tracking_column字段的值保存到last_run_metadata_path指定的文件中;
record_last_run => true
# 需要记录查询结果某字段的值时,此字段为true,否则默认tracking_column为timestamp的值;
use_column_value => true
# 需要记录的字段,用于增量同步,需是数据库字段
tracking_column => "ModifyTime"
# Value can be any of: numeric,timestamp,Default value is "numeric"
tracking_column_type => timestamp
# record_last_run上次数据存放位置;
last_run_metadata_path => "mysql/last_id.txt"
# 是否清除last_run_metadata_path的记录,需要增量同步时此字段必须为false;
clean_run => false
#
# 同步频率(分 时 天 月 年),默认每分钟同步一次;
schedule => "* * * * *"
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
# convert 字段类型转换,将字段TotalMoney数据类型改为float;
mutate {
convert => {
"TotalMoney" => "float"
}
}
}
output {
elasticsearch {
# 配置ES集群地址
hosts => ["192.168.1.1:9200", "192.168.1.2:9200", "192.168.1.3:9200"]
# 索引名字,必须小写
index => "consumption"
}
stdout {
codec => json_lines
}
}
5、多表同步:
多表配置和单表配置的区别在于input模块的jdbc模块有几个type,output模块就需对应有几个type;
input {
stdin {}
jdbc {
# 多表同步时,表类型区分,建议命名为“库名_表名”,每个jdbc模块需对应一个type;
type => "TestDB_DetailTab"
# 其他配置此处省略,参考单表配置
# ...
# ...
# record_last_run上次数据存放位置;
last_run_metadata_path => "mysql\last_id.txt"
# 是否清除last_run_metadata_path的记录,需要增量同步时此字段必须为false;
clean_run => false
#
# 同步频率(分 时 天 月 年),默认每分钟同步一次;
schedule => "* * * * *"
}
jdbc {
# 多表同步时,表类型区分,建议命名为“库名_表名”,每个jdbc模块需对应一个type;
type => "TestDB_Tab2"
# 多表同步时,last_run_metadata_path配置的路径应不一致,避免有影响;
# 其他配置此处省略
# ...
# ...
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
}
output {
# output模块的type需和jdbc模块的type一致
if [type] == "TestDB_DetailTab" {
elasticsearch {
# host => "192.168.1.1"
# port => "9200"
# 配置ES集群地址
hosts => ["192.168.1.1:9200", "192.168.1.2:9200", "192.168.1.3:9200"]
# 索引名字,必须小写
index => "detailtab1"
# 数据唯一索引(建议使用数据库KeyID)
document_id => "%{KeyId}"
}
}
if [type] == "TestDB_Tab2" {
elasticsearch {
# host => "192.168.1.1"
# port => "9200"
# 配置ES集群地址
hosts => ["192.168.1.1:9200", "192.168.1.2:9200", "192.168.1.3:9200"]
# 索引名字,必须小写
index => "detailtab2"
# 数据唯一索引(建议使用数据库KeyID)
document_id => "%{KeyId}"
}
}
stdout {
codec => json_lines
}
}
二、使用logstash全量同步(1分钟同步一次)mysql数据导入到elasticsearch
配置如下:
input {
stdin {}
jdbc {
type => "jdbc"
jdbc_connection_string => "jdbc:mysql://192.168.200.100:3306/yang?characterEncoding=UTF-8&autoReconnect=true"
# 数据库连接账号密码;
jdbc_user => "root"
jdbc_password => "010209"
# MySQL依赖包路径;
jdbc_driver_library => "/mnt/mysql-connector-java-5.1.38.jar"
# the name of the driver class for mysql
jdbc_driver_class => "com.mysql.jdbc.Driver"
statement => "SELECT * FROM `im`"
schedule => "* * * * *"
}
}
output {
elasticsearch {
# 配置ES集群地址
hosts => ["192.168.200.100:9200"]
# 索引名字,必须小写
index => "im"
}
stdout {
}
}
第一次同步结果:
[2019-04-25T14:39:03,194][INFO ][logstash.inputs.jdbc ] (0.100064s) SELECT * FROM `im`
{
"@version" => "1",
"@timestamp" => 2019-04-25T06:39:03.338Z,
"type" => "jdbc",
"id" => 3,
"name" => "QQ"
}
{
"@version" => "1",
"@timestamp" => 2019-04-25T06:39:03.309Z,
"type" => "jdbc",
"id" => 2,
"name" => "MSN"
}
向mysql插入数据后第二次同步:
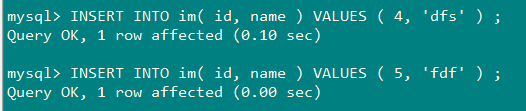
[2019-04-25T14:40:00,295][INFO ][logstash.inputs.jdbc ] (0.001956s) SELECT * FROM `im`
{
"@version" => "1",
"@timestamp" => 2019-04-25T06:40:00.310Z,
"type" => "jdbc",
"id" => 2,
"name" => "MSN"
}
{
"@version" => "1",
"@timestamp" => 2019-04-25T06:40:00.316Z,
"type" => "jdbc",
"id" => 3,
"name" => "QQ"
}
{
"@version" => "1",
"@timestamp" => 2019-04-25T06:40:00.317Z,
"type" => "jdbc",
"id" => 4,
"name" => "dfs"
}
{
"@version" => "1",
"@timestamp" => 2019-04-25T06:40:00.317Z,
"type" => "jdbc",
"id" => 5,
"name" => "fdf"
}
三、使用logstash增量同步(1分钟同步一次)mysql数据导入到elasticsearch
input {
stdin {}
jdbc {
type => "jdbc"
jdbc_connection_string => "jdbc:mysql://192.168.200.100:3306/yang?characterEncoding=UTF-8&autoReconnect=true"
# 数据库连接账号密码;
jdbc_user => "root"
jdbc_password => "010209"
# MySQL依赖包路径;
jdbc_driver_library => "/mnt/mysql-connector-java-5.1.38.jar"
# the name of the driver class for mysql
jdbc_driver_class => "com.mysql.jdbc.Driver"
#是否开启分页
jdbc_paging_enabled => "true"
#分页条数
jdbc_page_size => "50000"
# 执行的sql 文件路径+名称
#statement_filepath => "/data/my_sql2.sql"
#SQL语句,也可以使用statement_filepath来指定想要执行的SQL
statement => "SELECT * FROM `im` where id > :sql_last_value"
#每一分钟做一次同步
schedule => "* * * * *"
#是否将字段名转换为小写,默认true(如果有数据序列化、反序列化需求,建议改为false)
lowercase_column_names => false
# 是否记录上次执行结果,true表示会将上次执行结果的tracking_column字段的值保存到last_run_metadata_path指定的文件中;
record_last_run => true
# 需要记录查询结果某字段的值时,此字段为true,否则默认tracking_column为timestamp的值;
use_column_value => true
# 需要记录的字段,用于增量同步,需是数据库字段
tracking_column => "id"
# record_last_run上次数据存放位置;
last_run_metadata_path => "/mnt/sql_last_value"
#是否将字段名转换为小写,默认true(如果有数据序列化、反序列化需求,建议改为false)
clean_run => false
}
}
output {
elasticsearch {
# 配置ES集群地址
hosts => ["192.168.200.100:9200"]
# 索引名字,必须小写
index => "im"
}
stdout {
}
}
说明:
由于我上一次最后sql_last_value文件中记录的id为5,当向mysql插入id=6的值时,结果:

插入id=8,7时;
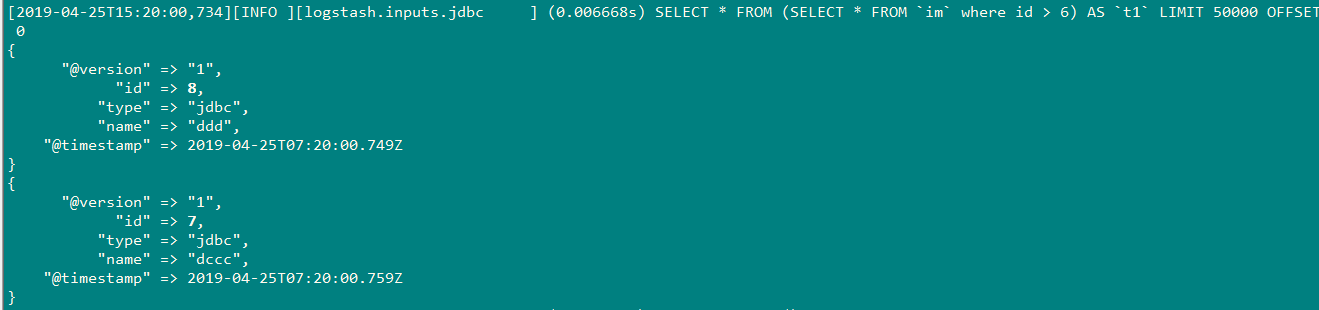
因为我插入的顺序,先插入id 为8,后插入id为7,因此最后一次记录的id为7,当我下一次插入id=9,10时,会重新导入id为8的值。

当我插入id=10的值后,结束,观察sql_last_value文件的最后记录:

结果:

Logstash学习之路(四)使用Logstash将mysql数据导入elasticsearch(单表同步、多表同步、全量同步、增量同步)的更多相关文章
- Logstash学习之路(一)Logstash的安装
一.Logstash简介 Logstash 是一个实时数据收集引擎,可收集各类型数据并对其进行分析,过滤和归纳.按照自己条件分析过滤出符合数据导入到可视化界面.它可以实现多样化的数据源数据全量或增量传 ...
- Logstash:把MySQL数据导入到Elasticsearch中
Logstash:把MySQL数据导入到Elasticsearch中 前提条件 需要安装好Elasticsearch及Kibana. MySQL安装 根据不同的操作系统我们分别对MySQL进行安装.我 ...
- 使用Logstash把MySQL数据导入到Elasticsearch中
总结:这种适合把已有的MySQL数据导入到Elasticsearch中 有一个csv文件,把里面的数据通过Navicat Premium 软件导入到数据表中,共有998条数据 文件下载地址:https ...
- Logstash学习之路(五)使用Logstash抽取mysql数据到kakfa
一.Logstash对接kafka测通 说明: 由于我这里kafka是伪分布式,且kafka在伪分布式下,已经集成了zookeeper. 1.先将zk启动,如果是在伪分布式下,kafka已经集成了zk ...
- Logstash学习之路(二)Elasticsearch导入json数据文件
一.数据从文件导入elasticsearch 1.数据准备: 1.数据文件:test.json 2.索引名称:index 3.数据类型:doc 4.批量操作API:bulk {"index& ...
- Redis——学习之路四(初识主从配置)
首先我们配置一台master服务器,两台slave服务器.master服务器配置就是默认配置 端口为6379,添加就一个密码CeshiPassword,然后启动master服务器. 两台slave服务 ...
- 【记录】ELK之logstash同步mysql数据到Elasticsearch ,配置文件详解
本文出处:https://my.oschina.net/xiaowangqiongyou/blog/1812708#comments 截取部分内容以便学习 input { jdbc { # mysql ...
- 实战ELK(6)使用logstash同步mysql数据到ElasticSearch
一.准备 1.mysql 我这里准备了个数据库mysqlEs,表User 结构如下 添加几条记录 2.创建elasticsearch索引 curl -XPUT 'localhost:9200/user ...
- centos7配置Logstash同步Mysql数据到Elasticsearch
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中.个人认为这款插件是比较稳定,容易配置的使用Logstash之前,我们得明确 ...
随机推荐
- 第9.13节 Python文件操作总结
本章老猿重点介绍了Python io模块的文件操作相关功能,包括文件打开.读.写.文件定位.文件关闭,并介绍了二进制文件和文本文件处理的差异,以及相关文件编码的一些知识,最后简单提及了Python中与 ...
- Docker部署CTF综合性靶场,定时刷新环境
部署如DVWA或upload-labs这类综合性靶场的时候,虽然是使用Docker环境,设置好权限后容器被击穿的问题不需要考虑,但担心部分选手修改了题目环境,比如一直XSS弹窗,所以想要编写脚本每天定 ...
- ATT&CK 实战 - 红日安全 vulnstack (二) 环境部署(劝退水文)
靶机下载地址:http://vulnstack.qiyuanxuetang.net/vuln/detail/3/ 靶场简述 红队实战系列,主要以真实企业环境为实例搭建一系列靶场,通过练习.视频教程.博 ...
- kaggle——Bag of Words Meets Bags of Popcorn(IMDB电影评论情感分类实践)
kaggle链接:https://www.kaggle.com/c/word2vec-nlp-tutorial/overview 简介:给出 50,000 IMDB movie reviews,进行0 ...
- Scrum 冲刺第七天
一.每日站立式会议 1.会议内容 1)进行每日工作汇报 张博愉: 昨天已完成的工作:与林梓琦同学完成发帖模块的交接 今日工作计划:完善发帖模块的点赞.上传图片功能 工作中遇到的困难:Mybatis的一 ...
- Jmeter(三十三) - 从入门到精通 - Jmeter Http协议录制脚本工具-Badboy6(详解教程)
1.简介 今天分享的就是在上一篇文章的基础上来进行讲解和分享:Badboy使用数据源Excel进行脚本参数化.然后在使用读取的参数进行对比断言. 2.具体场景 Badboy录制一个搜索的脚本,并对搜索 ...
- 落谷P3041 [USACO12JAN]Video Game G
题目链接 多模式匹配问题,先建 AC 自动机. 套路性的搞个 DP: \(f[i][j]\) 表示前 \(i\) 个字符,当前在 \(AC\) 自动机上的节点是 \(j\) 能匹配到的最多分. 初始化 ...
- oracle查年度周末日期
1.查年度周末日期sql SELECT distinct TRUNC(TO_DATE('2019-01-01','yyyy-mm-dd')+ rownum,'iw')+ 5 AS sat, TRUNC ...
- db2常用操作
1. db2建立远程节点编目及删除 db2 catalog tcpip node nodeName remote remoteIp server remotePort db2 list node di ...
- c预处理和宏
文件的预处理 #include "xxx.h" 1 首先查找当前源文件所在的路径 2 查找工程的头文件搜索路径 #include <xxxx.h> 查找工程的头文件搜索 ...