从PDF中提取信息----PDFMiner
今天由于某种原因需要将pdf中的文本提取出来,就去搜了下资料,发现PDFMiner是针对
内容提取的,虽然最后发现pdf里面的文本全都是图片,就没整成功,不过试了个文本可复制的
那种pdf文件,发现还是蛮好用的。
PDFMiner----python的PDF解析器和分析器
1.官方文档:http://www.unixuser.org/~euske/python/pdfminer/index.html
2.特征
- 完全使用python编写。 (适用于2.4或更新版本)
- 解析,分析,并转换成PDF文档。
- PDF-1.7规范的支持。 (几乎)
- 中日韩语言和垂直书写脚本支持。
- 各种字体类型(Type1、TrueType、Type3,和CID)的支持。
- 基本加密(RC4)的支持。
- PDF与HTML转换。
- 纲要(TOC)的提取。
- 标签内容提取。
- 通过分组文本块重建原始的布局。
3.安装
注:使用源码安装,并且处理中日韩语言的时候还需要一个额外的安装步骤
4.用法
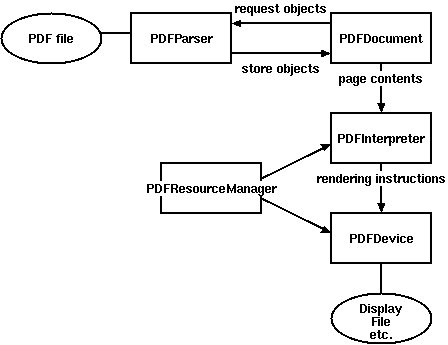
4.1解析pdf文件用到的类:
- PDFParser:从一个文件中获取数据
- PDFDocument:保存获取的数据,和PDFParser是相互关联的
- PDFPageInterpreter处理页面内容
- PDFDevice将其翻译成你需要的格式
- PDFResourceManager用于存储共享资源,如字体或图像。
PDFMiner的类之间的关系图:
4.2基本用法
4.2.1解析pdf文件
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfpage import PDFTextExtractionNotAllowed
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice fp = open('mypdf.pdf', 'rb')
#创建一个PDF文档解析器对象
parser = PDFParser(fp)
#创建一个PDF文档对象存储文档结构
#提供密码初始化,没有就不用传该参数
document = PDFDocument(parser, password)
#检查文件是否允许文本提取
if not document.is_extractable:
raise PDFTextExtractionNotAllowed
#创建一个PDF资源管理器对象来存储共享资源
rsrcmgr = PDFResourceManager()
#创建一个pdf设备对象
device = PDFDevice(rsrcmgr)
#创建一个PDF解析器对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
#处理文档当中的每个页面
for page in PDFPage.create_pages(document):
interpreter.process_page(page)
当然这只是进行解析,还可进行布局分析,我的数据就是从这一步的到的
4.2.2布局分析
首先对第一步的代码进行修改和增加
from pdfminer.layout import LAParams
from pdfminer.converter import PDFPageAggregator # 设定参数进行分析
laparams = LAParams()
# 创建一个PDF页面聚合对象
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
interpreter = PDFPageInterpreter(rsrcmgr, device)
for page in PDFPage.create_pages(document):
interpreter.process_page(page)
# 接收该页面的LTPage对象
layout = device.get_result()
布局分析返回的PDF文档中的每个页面LTPage对象。这个对象和页内包含的子对象,形成一个树结构
如图所示:
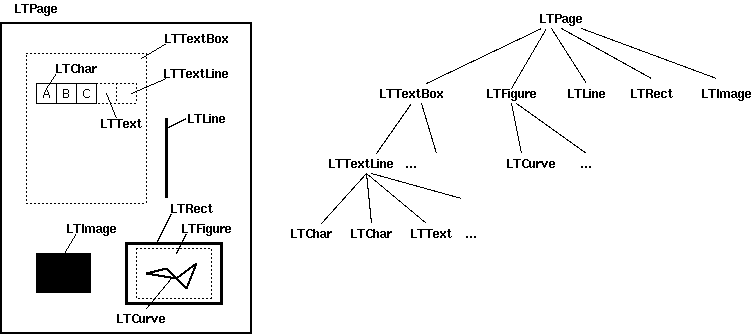
- LTPage :表示整个页。可能会含有LTTextBox,LTFigure,LTImage,LTRect,LTCurve和LTLine子对象。
- LTTextBox:表示一组文本块可能包含在一个矩形区域。注意此box是由几何分析中创建,并且不一定
表示该文本的一个逻辑边界。它包含LTTextLine对象的列表。使用 get_text()方法返回的文本内容。 - LTTextLine :包含表示单个文本行LTChar对象的列表。字符对齐要么水平或垂直,取决于文本的写入模式。
get_text()方法返回的文本内容。 - LTChar
- LTAnno:在文本中实际的字母表示为Unicode字符串(?)。需要注意的是,虽然一个LTChar对象具有实际边界,
LTAnno对象没有,因为这些是“虚拟”的字符,根据两个字符间的关系(例如,一个空格)由布局分析后插入。 - LTImage:表示一个图像对象。嵌入式图像可以是JPEG或其它格式,但是目前PDFMiner没有放置太多精力在图形对象。
- LTLine:代表一条直线。可用于分离文本或附图。
- LTRect:表示矩形。可用于框架的另一图片或数字。
LTCurve:表示一个通用的Bezier曲线
4.2.3获得目录(纲要)
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument # Open a PDF document.
fp = open('mypdf.pdf', 'rb')
parser = PDFParser(fp)
document = PDFDocument(parser, password) # Get the outlines of the document.
outlines = document.get_outlines()
for (level,title,dest,a,se) in outlines:
print (level, title)
5.个人使用
# -*- coding: utf-8 -*-
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfpage import PDFTextExtractionNotAllowed
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice
from pdfminer.layout import *
from pdfminer.converter import PDFPageAggregator
import os
os.chdir(r'F:\test')
fp = open('python.pdf', 'rb')
#来创建一个pdf文档分析器
parser = PDFParser(fp)
#创建一个PDF文档对象存储文档结构
document = PDFDocument(parser)
# 检查文件是否允许文本提取
if not document.is_extractable:
raise PDFTextExtractionNotAllowed
else:
# 创建一个PDF资源管理器对象来存储共赏资源
rsrcmgr=PDFResourceManager()
# 设定参数进行分析
laparams=LAParams()
# 创建一个PDF设备对象
# device=PDFDevice(rsrcmgr)
device=PDFPageAggregator(rsrcmgr,laparams=laparams)
# 创建一个PDF解释器对象
interpreter=PDFPageInterpreter(rsrcmgr,device)
# 处理每一页
for page in PDFPage.create_pages(document):
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout=device.get_result()
for x in layout:
if(isinstance(x,LTTextBoxHorizontal)):
with open('a.txt','a') as f:
f.write(x.get_text().encode('utf-8')+'\n')
将书中的文本内容得到了,只是简单的使用,官方文档中讲解的很全面,在此只是做个小总结。
注:转载请注明出处
从PDF中提取信息----PDFMiner的更多相关文章
- 用python库openpyxl操作excel,从源excel表中提取信息复制到目标excel表中
现代生活中,我们很难不与excel表打交道,excel表有着易学易用的优点,只是当表中数据量很大,我们又需要从其他表册中复制粘贴一些数据(比如身份证号)的时候,我们会越来越倦怠,毕竟我们不是机器,没法 ...
- 在excel单元格中提取信息
平时在excel中处理数据的时候,肯定会遇到在单元格提取信息的情况,比如在地址中提取省.市.地区等,如果数据源内容规整的话,可以直接使用left().right().mid()等函数直接提取,但是大多 ...
- 用PDFMiner从PDF中提取文本文字
1.下载并安装PDFMiner 从https://pypi.python.org/pypi/pdfminer/下载PDFMineer wget https://pypi.python.org/pack ...
- java从pdf中提取文本
一(单文件转换):下载pdfbox包,百度搜pdfbox.(fontbox-1.8.16.jar和pdfbox-app-1.8.16.jar) package pdf; import java.io. ...
- 如何从PDF文件中提取矢量图
很多时候我们需要PDF文档中的插图,直接用pdf中的复制或者截屏软件只能提取位图格式的图片,放大缩小难免失真. 本文教大家一种一种从pdf中提取矢量图的方法. 工具软件: 1 adobe acroba ...
- Java 添加、提取PDF中的图片
Spire.Cloud.SDK for Java提供了PdfImagesApi接口可用于添加图片到PDF文档addImage().提取PDF中的图片extractImages(),具体操作步骤和Jav ...
- 如何使用免费PDF控件从PDF文档中提取文本和图片
如何使用免费PDF控件从PDF文档中提取文本和图片 概要 现在手头的项目有一个需求是从PDF文档中提取文本和图片,我以前也使用过像iTextSharp, PDFBox 这些免费的PD ...
- 在线提取PDF中图片和文字
无需下载软件,你就可以在线提取PDF中图片和文字,http://www.extractpdf.com/不仅可以获取本地PDF文档的图片和文字,还能获取远程PDF文档的图片和文字.如下图所示:结果本人测 ...
- 第一个lucene程序,把一个信息写入到索引库中、根据关键词把对象从索引库中提取出来、lucene读写过程分析
新建一个Java Project :LuceneTest 准备lucene的jar包,要加入的jar包至少有: 1)lucene-core-3.1.0.jar (核心包) 2) lucene- ...
随机推荐
- Steve Loughran:Why not raid 0,its about time and snowflakes!!!
与RAID-0阵列的同组管理相比,Hadoop更喜欢一组单独磁盘.在Hadoop集群中,读取速度是最能体现性能的重要指标.在Steve Loughran文章中,尤其强调了这一点,他还指出,由于驱动器速 ...
- List view优化
ListView 针对每个item,要求 adapter "返回一个视图" (getView),也就是说ListView在开始绘制的时候,系统首先调用getCount()函数,根据 ...
- python3.4学习笔记(十七) 网络爬虫使用Beautifulsoup4抓取内容
python3.4学习笔记(十七) 网络爬虫使用Beautifulsoup4抓取内容 Beautiful Soup 是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖 ...
- svn版本搭建
安装步骤如下: 1.yum install subversion 2.输入rpm -ql subversion查看安装位置,如下图: 我们知道svn在bin目录下生成了几个二进制文件. 输入 ...
- win7下matlab2016a配置libsvm
1.下载libsvm https://www.csie.ntu.edu.tw/~cjlin/libsvm/ 2.解压到matlab2016a的安装目录的toolbox下 例如我的D:\Program ...
- 通过GCC编译器编译c语言
GCC编译C源代码的四个步骤 GCC编译C源代码有四个步骤:预处理---->编译---->汇编---->链接. 可以利用GCC的参数来控制执行的过程,这样就可以更深入的了解编译C程序 ...
- LLVM与Clang的概述及关系
LLVM是构架编译器(compiler)的框架系统,以C++编写而成,用于优化以任意程序语言编写的程序的编译时间(compile-time).链接时间(link-time).运行时间(run-time ...
- python 学习笔记十六 django深入学习一 路由系统,模板,admin,数据库操作
django 请求流程图 django 路由系统 在django中我们可以通过定义urls,让不同的url路由到不同的处理函数 from . import views urlpatterns = [ ...
- Java开发中经典的小实例-(冒泡法)
public class Test25 { public static void main(String[] args) { // 冒泡法 int[] array = ...
- 使用注解方式生成Hibernate映射文件
@Entity:表示是一个hibernate的实体类 @Table:表示实体类和表的对应关系 @Id:表示是数据库中的主键 @Column:在数据表中描述的对应的列的信息 属性名是根据get方法,数据 ...