05 (OC) 二叉树 深度优先遍历和广度优先遍历
总结深度优先与广度优先的区别
1、区别
1) 二叉树的深度优先遍历的非递归的通用做法是采用栈,广度优先遍历的非递归的通用做法是采用队列。
2) 深度优先遍历:对每一个可能的分支路径深入到不能再深入为止,而且每个结点只能访问一次。要特别注意的是,二叉树的深度优先遍历比较特殊,可以细分为先序遍历、中序遍历、后序遍历。具体说明如下:
- 先序遍历:对任一子树,先访问根,然后遍历其左子树,最后遍历其右子树。
- 中序遍历:对任一子树,先遍历其左子树,然后访问根,最后遍历其右子树。
- 后序遍历:对任一子树,先遍历其左子树,然后遍历其右子树,最后访问根。
广度优先遍历:又叫层次遍历,从上往下对每一层依次访问,在每一层中,从左往右(也可以从右往左)访问结点,访问完一层就进入下一层,直到没有结点可以访问为止。
3)深度优先搜素算法:不全部保留结点,占用空间少;有回溯操作(即有入栈、出栈操作),运行速度慢。
广度优先搜索算法:保留全部结点,占用空间大; 无回溯操作(即无入栈、出栈操作),运行速度快。
通常 深度优先搜索法不全部保留结点,扩展完的结点从数据库中弹出删去,这样,一般在数据库中存储的结点数就是深度值,因此它占用空间较少。
所以,当搜索树的结点较多,用其它方法易产生内存溢出时,深度优先搜索不失为一种有效的求解方法。
广度优先搜索算法,一般需存储产生的所有结点,占用的存储空间要比深度优先搜索大得多,因此,程序设计中,必须考虑溢出和节省内存空间的问题。
但广度优先搜索法一般无回溯操作,即入栈和出栈的操作,所以运行速度比深度优先搜索要快些
4)深度优先遍历:用时间换空间。
广度优先遍历:用空间换时间。
2.二叉树的遍历
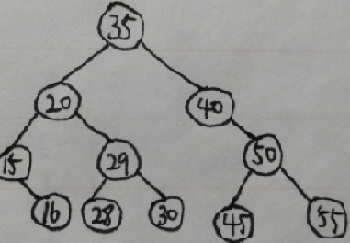
先序遍历(递归):35 20 15 16 29 28 30 40 50 45 55
中序遍历(递归):15 16 20 28 29 30 35 40 45 50 55
后序遍历(递归):16 15 28 30 29 20 45 55 50 40 35
先序遍历(非递归):35 20 15 16 29 28 30 40 50 45 55
中序遍历(非递归):15 16 20 28 29 30 35 40 45 50 55
后序遍历(非递归):16 15 28 30 29 20 45 55 50 40 35
广度优先遍历:35 20 40 15 29 50 16 28 30 45 55
05 (OC) 二叉树 深度优先遍历和广度优先遍历的更多相关文章
- js实现深度优先遍历和广度优先遍历
深度优先遍历和广度优先遍历 什么是深度优先和广度优先 其实简单来说 深度优先就是自上而下的遍历搜索 广度优先则是逐层遍历, 如下图所示 1.深度优先 2.广度优先 两者的区别 对于算法来说 无非就是时 ...
- 深度优先遍历 and 广度优先遍历
深度优先遍历 and 广度优先遍历 遍历在前端的应用场景不多,多数是处理DOM节点数或者 深拷贝.下面笔者以深拷贝为例,简单说明一些这两种遍历.
- C++ 二叉树深度优先遍历和广度优先遍历
二叉树的创建代码==>C++ 创建和遍历二叉树 深度优先遍历:是沿着树的深度遍历树的节点,尽可能深的搜索树的分支. //深度优先遍历二叉树void depthFirstSearch(Tree r ...
- python、java实现二叉树,细说二叉树添加节点、深度优先(先序、中序、后续)遍历 、广度优先 遍历算法
数据结构可以说是编程的内功心法,掌握好数据结构真的非常重要.目前基本上流行的数据结构都是c和c++版本的,我最近在学习python,尝试着用python实现了二叉树的基本操作.写下一篇博文,总结一下, ...
- 二叉树的深度优先遍历与广度优先遍历 [ C++ 实现 ]
深度优先搜索算法(Depth First Search),是搜索算法的一种.是沿着树的深度遍历树的节点,尽可能深的搜索树的分支. 当节点v的所有边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点 ...
- 树的深度优先遍历和广度优先遍历的原理和java实现代码
import java.util.ArrayDeque; public class BinaryTree { static class TreeNode{ int value; TreeNode le ...
- 邻接矩阵c源码(构造邻接矩阵,深度优先遍历,广度优先遍历,最小生成树prim,kruskal算法)
matrix.c #include <stdio.h> #include <stdlib.h> #include <stdbool.h> #include < ...
- C++编程练习(9)----“图的存储结构以及图的遍历“(邻接矩阵、深度优先遍历、广度优先遍历)
图的存储结构 1)邻接矩阵 用两个数组来表示图,一个一维数组存储图中顶点信息,一个二维数组(邻接矩阵)存储图中边或弧的信息. 2)邻接表 3)十字链表 4)邻接多重表 5)边集数组 本文只用代码实现用 ...
- js实现对树深度优先遍历与广度优先遍历
深度优先与广度优先的定义 首先我们先要知道什么是深度优先什么是广度优先. 深度优先遍历是指从某个顶点出发,首先访问这个顶点,然后找出刚访问这个结点的第一个未被访问的邻结点,然后再以此邻结点为顶点,继续 ...
随机推荐
- spring中的事件 applicationevent 讲的确实不错(转)
event,listener是observer模式一种体现,在spring 3.0.5中,已经可以使用annotation实现event和eventListner里. 我们以spring-webflo ...
- Leetcode 5. Longest Palindromic Substring(最长回文子串, Manacher算法)
Leetcode 5. Longest Palindromic Substring(最长回文子串, Manacher算法) Given a string s, find the longest pal ...
- think in java 泛型
曾几何时,我们对java的泛型充满了好奇,但是感觉用起来有很爽,但又会在spring类型泛型的地方,遇到问题. 我第一次的遇到泛型是在使用别人的BaseDao的时候,这是一个java封装hiberna ...
- [原创] Nginx1.13版本reload过程对TCP包影响的测试
Nginx1.13版本reload过程中各项连接情况和状态的测试.测试Nginx1.13 Reload过程中,对客户端和服务器的TCP层面的包影响. 1)对客户端开启长连接,服务端开启/不开启 ...
- egret之每日登陆奖励
//*******首登奖励********* */ //*********************** */ public setUserSetting(key, value) { if (value ...
- 转载-springboot缓存开发
转载:https://www.cnblogs.com/wyq178/p/9840985.html 前言:缓存在开发中是一个必不可少的优化点,近期在公司的项目重构中,关于缓存优化了很多点,比如在加载 ...
- 同步vmware虚拟机和主机的时间
1. 打开虚拟机->设置 2. 选择选项标签页,选中VMware Tools,勾选“将客户机时间与主机同步”
- Elasticsearch 在docker和centos下的安装教程
前言 新版本的Elasticsearch不能以root用户来运行.因此,MAC下建议使用Docker来安装. 国内各版本镜像:点击这 Centos7.4 64位 第一步 下载.tar.gz的安装包 不 ...
- HZNU Training 2 for Zhejiang Provincial Collegiate Programming Contest 2019
赛后总结: T:今天下午参加了答辩比赛,没有给予队友很大的帮助.远程做题的时候发现队友在H上遇到了挫折,然后我就和她们说我看H吧,她们就开始做了另外两道题.今天一人一道题.最后我们在研究一道dp的时候 ...
- 牛课练习赛34 Flittle w and Discretization 主席树维护Mex
ittle w and Discretization 主席树维护Mex. 每个右端点 r 维护出一棵 在[1, r ] 区间中 其他所有的 值离这个 r 最近的的位置是多少. 然后询问区间[L,R]的 ...