二叉树的深度优先遍历与广度优先遍历 [ C++ 实现 ]
深度优先搜索算法(Depth First Search),是搜索算法的一种。是沿着树的深度遍历树的节点,尽可能深的搜索树的分支。
当节点v的所有边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。
如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。
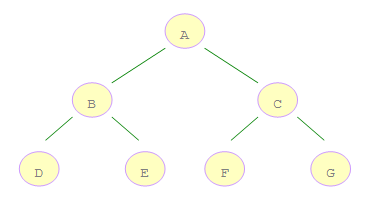
如右图所示的二叉树:
A 是第一个访问的,然后顺序是 B、D,然后是 E。接着再是 C、F、G。
那么,怎么样才能来保证这个访问的顺序呢?
分析一下,在遍历了根结点后,就开始遍历左子树,最后才是右子树。
因此可以借助堆栈的数据结构,由于堆栈是后进先出的顺序,由此可以先将右子树压栈,然后再对左子树压栈,
这样一来,左子树结点就存在了栈顶上,因此某结点的左子树能在它的右子树遍历之前被遍历。
深度优先遍历代码片段
//深度优先遍历
void depthFirstSearch(Tree root){
stack<Node *> nodeStack; //使用C++的STL标准模板库
nodeStack.push(root);
Node *node;
while(!nodeStack.empty()){
node = nodeStack.top();
printf(format, node->data); //遍历根结点
nodeStack.pop();
if(node->rchild){
nodeStack.push(node->rchild); //先将右子树压栈
}
if(node->lchild){
nodeStack.push(node->lchild); //再将左子树压栈
}
}
}
广度优先搜索算法(Breadth First Search),又叫宽度优先搜索,或横向优先搜索。
是从根节点开始,沿着树的宽度遍历树的节点。如果所有节点均被访问,则算法中止。
如右图所示的二叉树,A 是第一个访问的,然后顺序是 B、C,然后再是 D、E、F、G。
那么,怎样才能来保证这个访问的顺序呢?
借助队列数据结构,由于队列是先进先出的顺序,因此可以先将左子树入队,然后再将右子树入队。
这样一来,左子树结点就存在队头,可以先被访问到。
广度优先遍历代码片段
//广度优先遍历
void breadthFirstSearch(Tree root){
queue<Node *> nodeQueue; //使用C++的STL标准模板库
nodeQueue.push(root);
Node *node;
while(!nodeQueue.empty()){
node = nodeQueue.front();
nodeQueue.pop();
printf(format, node->data);
if(node->lchild){
nodeQueue.push(node->lchild); //先将左子树入队
}
if(node->rchild){
nodeQueue.push(node->rchild); //再将右子树入队
}
}
}
完整代码:
/**
* <!--
* File : binarytree.h
* Author : fancy
* Email : fancydeepin@yeah.net
* Date : 2013-02-03
* --!>
*/
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
#include <Stack>
#include <Queue>
using namespace std;
#define Element char
#define format "%c" typedef struct Node {
Element data;
struct Node *lchild;
struct Node *rchild;
} *Tree; int index = 0; //全局索引变量 //二叉树构造器,按先序遍历顺序构造二叉树
//无左子树或右子树用'#'表示
void treeNodeConstructor(Tree &root, Element data[]){
Element e = data[index++];
if(e == '#'){
root = NULL;
}else{
root = (Node *)malloc(sizeof(Node));
root->data = e;
treeNodeConstructor(root->lchild, data); //递归构建左子树
treeNodeConstructor(root->rchild, data); //递归构建右子树
}
} //深度优先遍历
void depthFirstSearch(Tree root){
stack<Node *> nodeStack; //使用C++的STL标准模板库
nodeStack.push(root);
Node *node;
while(!nodeStack.empty()){
node = nodeStack.top();
printf(format, node->data); //遍历根结点
nodeStack.pop();
if(node->rchild){
nodeStack.push(node->rchild); //先将右子树压栈
}
if(node->lchild){
nodeStack.push(node->lchild); //再将左子树压栈
}
}
} //广度优先遍历
void breadthFirstSearch(Tree root){
queue<Node *> nodeQueue; //使用C++的STL标准模板库
nodeQueue.push(root);
Node *node;
while(!nodeQueue.empty()){
node = nodeQueue.front();
nodeQueue.pop();
printf(format, node->data);
if(node->lchild){
nodeQueue.push(node->lchild); //先将左子树入队
}
if(node->rchild){
nodeQueue.push(node->rchild); //再将右子树入队
}
}
}
/**
* <!--
* File : BinaryTreeSearch.h
* Author : fancy
* Email : fancydeepin@yeah.net
* Date : 2013-02-03
* --!>
*/
#include "binarytree.h" int main() { //上图所示的二叉树先序遍历序列,其中用'#'表示结点无左子树或无右子树
Element data[15] = {'A', 'B', 'D', '#', '#', 'E', '#', '#', 'C', 'F','#', '#', 'G', '#', '#'};
Tree tree;
treeNodeConstructor(tree, data);
printf("深度优先遍历二叉树结果: ");
depthFirstSearch(tree);
printf("\n\n广度优先遍历二叉树结果: ");
breadthFirstSearch(tree);
return 0; }
二叉树的深度优先遍历与广度优先遍历 [ C++ 实现 ]的更多相关文章
- js实现深度优先遍历和广度优先遍历
深度优先遍历和广度优先遍历 什么是深度优先和广度优先 其实简单来说 深度优先就是自上而下的遍历搜索 广度优先则是逐层遍历, 如下图所示 1.深度优先 2.广度优先 两者的区别 对于算法来说 无非就是时 ...
- 深度优先遍历 and 广度优先遍历
深度优先遍历 and 广度优先遍历 遍历在前端的应用场景不多,多数是处理DOM节点数或者 深拷贝.下面笔者以深拷贝为例,简单说明一些这两种遍历.
- C++ 二叉树深度优先遍历和广度优先遍历
二叉树的创建代码==>C++ 创建和遍历二叉树 深度优先遍历:是沿着树的深度遍历树的节点,尽可能深的搜索树的分支. //深度优先遍历二叉树void depthFirstSearch(Tree r ...
- python、java实现二叉树,细说二叉树添加节点、深度优先(先序、中序、后续)遍历 、广度优先 遍历算法
数据结构可以说是编程的内功心法,掌握好数据结构真的非常重要.目前基本上流行的数据结构都是c和c++版本的,我最近在学习python,尝试着用python实现了二叉树的基本操作.写下一篇博文,总结一下, ...
- 05 (OC) 二叉树 深度优先遍历和广度优先遍历
总结深度优先与广度优先的区别 1.区别 1) 二叉树的深度优先遍历的非递归的通用做法是采用栈,广度优先遍历的非递归的通用做法是采用队列. 2) 深度优先遍历:对每一个可能的分支路径深入到不能再深入 ...
- 树的深度优先遍历和广度优先遍历的原理和java实现代码
import java.util.ArrayDeque; public class BinaryTree { static class TreeNode{ int value; TreeNode le ...
- 邻接矩阵c源码(构造邻接矩阵,深度优先遍历,广度优先遍历,最小生成树prim,kruskal算法)
matrix.c #include <stdio.h> #include <stdlib.h> #include <stdbool.h> #include < ...
- C++编程练习(9)----“图的存储结构以及图的遍历“(邻接矩阵、深度优先遍历、广度优先遍历)
图的存储结构 1)邻接矩阵 用两个数组来表示图,一个一维数组存储图中顶点信息,一个二维数组(邻接矩阵)存储图中边或弧的信息. 2)邻接表 3)十字链表 4)邻接多重表 5)边集数组 本文只用代码实现用 ...
- js实现对树深度优先遍历与广度优先遍历
深度优先与广度优先的定义 首先我们先要知道什么是深度优先什么是广度优先. 深度优先遍历是指从某个顶点出发,首先访问这个顶点,然后找出刚访问这个结点的第一个未被访问的邻结点,然后再以此邻结点为顶点,继续 ...
随机推荐
- 关于sql链接超时的问题
也许你会说,我在连接字符串中已经 设置了 Connect Timeout=80000 ,并且数据库中超时连接也是设置的值是一个很大的值.为啥到了30秒,仍然超时了呢?? 这是因为: ...
- leetcode1009
class Solution: def bitwiseComplement(self, N: int) -> int: if N==0: return 1 elif N==1: return 0 ...
- 选择、操作web元素-3
11月5日 Selenium 作业 3 登录 51job , http://www.51job.com 输入搜索关键词 "python", 地区选择 "杭州"( ...
- centos如何安装tomcat
1 通过 SecureCRT 连接到阿里云 CentOS7 服务器; 2 进入到目录 /usr/local/ 中: cd /usr/local/ 3 创建目录 /usr/local/tools,如果有 ...
- Others-工具箱
pycharm下载激活工具 : https://www.lanzous.com/i20tl8f作者(来源):https://www.52pojie.cn/thread-803822-1-1.html ...
- java定时任务——间隔指定时间执行方法
摘要:运行 main 方法的时候开始进行定时任务, service.scheduleAtFixedTate(task,5,TimeUnit.SECONDS);方法为关键 此次任务就是 run() 方法 ...
- shell命令中用source 和sh(或者bash)执行脚本的区别,以及export的作用
用户登录到Linux系统后,系统将启动一个用户shell,我们暂且称这个shell为shell父. 在这个shell父中,可以使用shell命令或声明变量,也可以创建并运行shell脚本程序. 当使用 ...
- linux /dev/null 中有数据
前段时间有个同事问我说,他 cat /dev/null有数据.这个颠覆大家认知的问题最终却是个小问题. 我们来看/dev/null的操作函数: static const struct memdev { ...
- Mastering Creativity:A brief guide on how to overcome creative blocks
MASTERING CREATIVITY, 1st EditionThis guide is free and you are welcome to share it withothers.From ...
- OpenWrt上搭建纯L2TP服务器[ZT]
转自:http://www.openwrt.pro/post-389.html 纯L2TP(l2tp + ppp,无IPSec) 首先安装xl2tpd软件包 opkg update opkg inst ...